搜索到
20
篇与
的结果
-
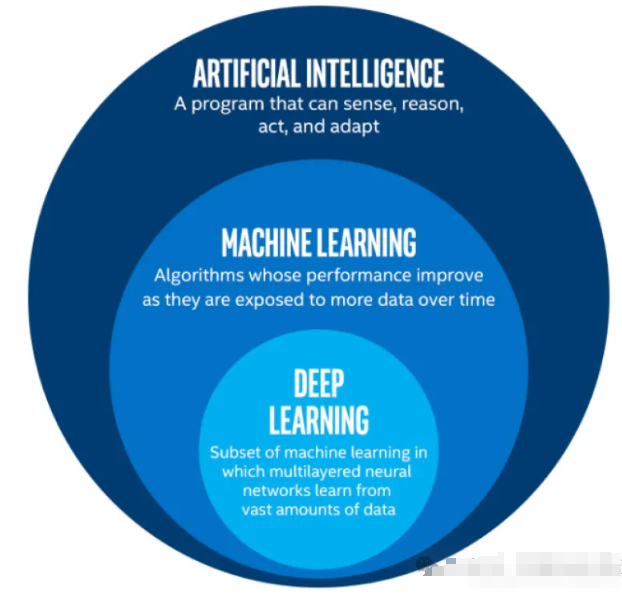
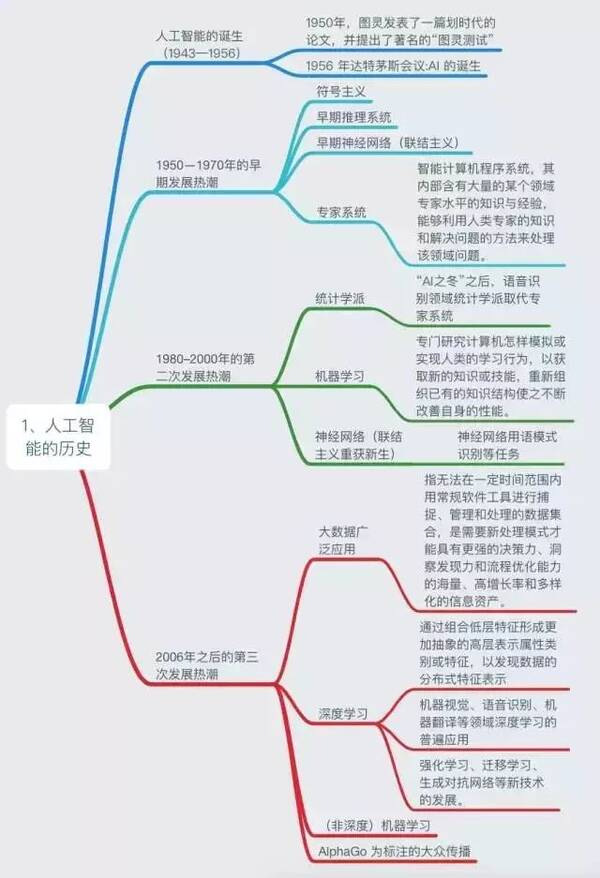
 AI专题一:人工智能、机器学习、深度学习 一 概念及定义通俗来说,人工智能(AI)就是让计算机像人类一样思考、学习和做出决策。通过利用各种技术(如机器学习、深度学习、专家系统等),人工智能系统可以处理和分析大量数据,自主地学习和优化算法,从而完成各种复杂的任务。人工智能的应用非常广泛,包括但不限于语音识别、图像识别、自然语言处理、智能推荐、智能客服等。具体的,从技术层面来看(如下图),现在所说的人工智能技术基本上就是机器学习(含深度学习)方面的技术。机器学习、深度学习是人工智能的重要组成。机器学习(ML)是让计算机通过算法自动从数据中学习规律和模式,机器学习常见的任务有分类任务(如通过逻辑回归模型 判断邮件是否为垃圾邮件类)、回归预测任务(线性回归模型预测股价)等等。深度学习(DL)是机器学习的一个子方向,是当下的热门,它实现的功能和机器学习差不多,区别在于深度学习是通过搭建深层的神经网络模型 以处理任务,主要任务有如深度神经网络模型回归预测股价 、 CNN做图像分类的任务,以及最近特别火爆的大模型内容生成。人工智能(AI):目标是“智能”定义:让机器完成通常需要人类智能才能胜任的任务。根据AI的能力范围和智能化程度,可以将人工智能分为ANI、AGI和ASI三个等级。ANI(弱人工智能)主要被编程以执行单一任务,它通常只能针对特定领域或任务展现出类似人类智能的能力。例如,手机地图导航、网购产品推荐等都是ANI的典型应用。AGI(通用人工智能)则是在不特定编码知识与应用区域的情况下,应对多种甚至泛化问题的人工智能技术。它拥有推理、计划、解决问题、抽象思考、快速学习和从经验中学习的能力。AGI更像是无所不能的计算机,能够像人类一样应对多种任务和环境。ASI(超人工智能)相较AGI,不仅要求具备人类某些能力,还要能够独立思考并解决问题。ASI不仅在智能化程度上超越了AGI,还在应用范围上有所扩展,能够应对更加复杂和多样化的任务。人工智能包括自然语言处理(NLP)、计算机视觉(CV)、机器学习、深度学习、数据挖掘、机器人技术等分支。这些分支在处理不同类型的数据和任务时各有优势。例如,自然语言处理(NLP)主要关注于自然语言的理解和生成,计算机视觉(CV)则关注于图像和视频的识别和理解,机器学习和深度学习则通过训练数据来让计算机自主地进行决策和预测,数据挖掘则从大量数据中挖掘出有用的信息,机器人技术则利用AI技术来构建能够执行各种任务的自动化系统。实现方式不止一种:基于规则的系统(早期AI):程序员手动编写“如果…就…”的逻辑。例如:国际象棋程序通过预设策略下棋。机器学习(现代主流):让机器从大量例子中自己总结规律。进化算法、专家系统、模糊逻辑等:其他非主流但有效的AI方法。 📌 关键点:AI 是目标,不是技术。就像“飞行”是目标,而飞机、火箭、热气球是不同实现方式。机器学习(ML):让机器“从经验中学习”核心思想: 不直接告诉机器怎么做,而是给它一堆输入-输出示例(比如1000张猫狗照片及其标签),让它自动找出映射规律。常用算法:线性回归、决策树、支持向量机(SVM)、K均值聚类等。📌 关键点:ML 的本质是函数逼近——找到一个函数 f,使得 f(输入) ≈ 输出。深度学习(DL):用“深度神经网络”自动提取特征传统机器学习往往需要人工设计特征(比如“猫有尖耳朵、胡须”),而深度学习能自动从原始数据中逐层提取特征。核心技术:深度神经网络(DNN),尤其是:卷积神经网络(CNN):擅长处理图像循环神经网络(RNN)/Transformer:擅长处理文本和序列生成对抗网络(GAN):用于生成新内容(如AI绘画)为什么叫“深度”? 因为网络包含多个隐藏层(有时上百层),每一层都对数据进行一次抽象。例如:第1层识别边缘第2层组合成纹理第3层识别眼睛、鼻子最后层判断“这是一张人脸” 📌 关键点:DL 是 ML 的“自动化升级版”——连特征工程都省了,但需要海量数据和强大算力。二 AI和ML 区别机器学习(ML)是人工智能(AI)的一个特定分支。与 AI 相比,机器学习的范围和重点有限。AI 还包括一些机器学习范围之外的策略和技术。以下是两者之间的一些关键区别。目标任何 AI 系统的目标都是让机器高效地完成复杂的人类任务。此类任务可能涉及学习、解决问题和模式识别。另一方面,机器学习的目标是让机器分析大量数据。机器将使用统计模型来识别数据中的模式并生成结果。结果具有相关的正确概率或可信度。方法AI 领域包括用于解决各种问题的各种方法。这些方法包括遗传算法、神经网络、深度学习、搜索算法、基于规则的系统和机器学习本身。在机器学习中,方法分为两大类:有监督学习和无监督学习。有监督机器学习算法使用标有 input 和 output 的数据值来解决问题。无监督学习更具探索性,它试图在未标记的数据中发现隐藏的模式。 实施构建机器学习解决方案的过程通常涉及两项任务:选择并准备训练数据集选择先前存在的机器学习策略或模型,例如线性回归或决策树数据科学家选择重要的数据特征并将其输入到模型中进行训练。他们通过更新的数据和错误检查来不断完善数据集。数据的质量和多样性提高了机器学习模型的准确性。 构建 AI 产品通常是一个更为复杂的过程,因此许多人选择预先构建的 AI 解决方案来实现他们的目标。这些 AI 解决方案通常是经过多年研究后开发的,开发人员可以通过 API 将其与产品和服务集成。要求机器学习解决方案需要使用包含数百个数据点的数据集进行训练,还需要足够的计算能力才能运行。根据您的应用程序和用例,单个服务器实例或小型服务器集群可能就足够了。其他智能系统可能有不同的基础设施要求,这取决于您想要完成的任务和所使用的计算分析方法。高计算用例需要数千台机器协同工作才能实现复杂的目标。但是,请务必注意,预先构建的 AI 和机器学习函数都可用。您可以通过 API 将它们集成到您的应用程序中,而无需额外资源。三 ML和DL 区别机器学习包括传统的机器学习与深度学习接下来我们具体介绍下机器学习(传统机器学习)与深度学习的区别及联系!学习方法机器学习:基于数据和算法,通过训练数据来调整模型参数,从而实现预测和分类等功能。常见的机器学习算法 包括线性回归、决策树、支持向量机等。深度学习:使用神经网络模型,通过反向传播算法和梯度下降优化技术来调整网络权重和参数。常见的深度学习模型 包括卷积神经网络(CNN)、循环神经网络(RNN)、Transformer等。数据需求机器学习:需要足够的数据来训练模型,但并不一定需要全部数据。可以通过特征选择、降维等技术来处理大规模数据集 。深度学习:需要大量的数据进行训练,尤其是对于复杂的任务和模型。通常需要使用无监督学习进行预训练,以减少对大规模数据集的需求。模型的复杂性机器学习:模型通常较为简单,主要是线性模型和统计模型等。模型的复杂度取决于所选择的算法和特征工程。深度学习:模型通常非常复杂,具有大量的神经元和层数。通过逐层传递信息,深度学习模型能够自动提取和抽象出有用的特征。优缺点机器学习:优点在于其预测准确度高,适用于各种类型的数据和任务;缺点是需要足够的数据和特征工程,对于复杂任务的建模能力有限。深度学习:优点在于其强大的表示能力和泛化能力,能够处理复杂的非线性问题;缺点是计算量大、训练时间长,对于大规模数据集的需求较高。应用领域机器学习:应用领域包括推荐系统、数据挖掘等。例如,使用支持向量机进行文本分类或使用决策树进行预测。深度学习:应用领域主要为图像识别、语音识别、自然语言处理等。例如,使用卷积神经网络进行图像分类或使用循环神经网络进行文本生成。两者区别(总结)模型层面:机器学习是基于传统模型(统计学习模型、KNN等等);深度学习则使用神经网络模型进行学习和预测。应用方面:机器学习适用于各种类型的数据和任务;深度学习则更适用于处理复杂的非线性问题。复杂度:深度学习的模型通常比机器学习模型更加复杂,需要更多的计算资源和训练时间。可解释性:机器学习:模型通常较为简单,因此具有一定的可解释性。例如,决策树和线性回归模型可以通过规则和系数来解释。深度学习:由于模型的复杂性和黑箱性质,通常难以解释。这使得深度学习在某些需要解释的场景中受到限制。鲁棒性:机器学习:一些传统的机器学习算法可能对噪声和异常值敏感。深度学习:通过强大的表示能力和鲁棒的网络结构,大数据加持的深度学习模型通常具有较好的鲁棒性,能够更好地处理噪声和异常值。数据标注需求:机器学习:许多传统的有监督机器学习算法需要一些标注数据,主要视模型复杂度具体来看,一些简单模型样本需求并不高,几百个也可以支持。深度学习:深度学习模型通常需要大量的标注数据,尤其是对于复杂的任务。然而,深度学习无监督学习和其他技术也可以减少对大量标注数据的需求。部分内容来源于:https://blog.csdn.net/python122_/article/details/138791308
AI专题一:人工智能、机器学习、深度学习 一 概念及定义通俗来说,人工智能(AI)就是让计算机像人类一样思考、学习和做出决策。通过利用各种技术(如机器学习、深度学习、专家系统等),人工智能系统可以处理和分析大量数据,自主地学习和优化算法,从而完成各种复杂的任务。人工智能的应用非常广泛,包括但不限于语音识别、图像识别、自然语言处理、智能推荐、智能客服等。具体的,从技术层面来看(如下图),现在所说的人工智能技术基本上就是机器学习(含深度学习)方面的技术。机器学习、深度学习是人工智能的重要组成。机器学习(ML)是让计算机通过算法自动从数据中学习规律和模式,机器学习常见的任务有分类任务(如通过逻辑回归模型 判断邮件是否为垃圾邮件类)、回归预测任务(线性回归模型预测股价)等等。深度学习(DL)是机器学习的一个子方向,是当下的热门,它实现的功能和机器学习差不多,区别在于深度学习是通过搭建深层的神经网络模型 以处理任务,主要任务有如深度神经网络模型回归预测股价 、 CNN做图像分类的任务,以及最近特别火爆的大模型内容生成。人工智能(AI):目标是“智能”定义:让机器完成通常需要人类智能才能胜任的任务。根据AI的能力范围和智能化程度,可以将人工智能分为ANI、AGI和ASI三个等级。ANI(弱人工智能)主要被编程以执行单一任务,它通常只能针对特定领域或任务展现出类似人类智能的能力。例如,手机地图导航、网购产品推荐等都是ANI的典型应用。AGI(通用人工智能)则是在不特定编码知识与应用区域的情况下,应对多种甚至泛化问题的人工智能技术。它拥有推理、计划、解决问题、抽象思考、快速学习和从经验中学习的能力。AGI更像是无所不能的计算机,能够像人类一样应对多种任务和环境。ASI(超人工智能)相较AGI,不仅要求具备人类某些能力,还要能够独立思考并解决问题。ASI不仅在智能化程度上超越了AGI,还在应用范围上有所扩展,能够应对更加复杂和多样化的任务。人工智能包括自然语言处理(NLP)、计算机视觉(CV)、机器学习、深度学习、数据挖掘、机器人技术等分支。这些分支在处理不同类型的数据和任务时各有优势。例如,自然语言处理(NLP)主要关注于自然语言的理解和生成,计算机视觉(CV)则关注于图像和视频的识别和理解,机器学习和深度学习则通过训练数据来让计算机自主地进行决策和预测,数据挖掘则从大量数据中挖掘出有用的信息,机器人技术则利用AI技术来构建能够执行各种任务的自动化系统。实现方式不止一种:基于规则的系统(早期AI):程序员手动编写“如果…就…”的逻辑。例如:国际象棋程序通过预设策略下棋。机器学习(现代主流):让机器从大量例子中自己总结规律。进化算法、专家系统、模糊逻辑等:其他非主流但有效的AI方法。 📌 关键点:AI 是目标,不是技术。就像“飞行”是目标,而飞机、火箭、热气球是不同实现方式。机器学习(ML):让机器“从经验中学习”核心思想: 不直接告诉机器怎么做,而是给它一堆输入-输出示例(比如1000张猫狗照片及其标签),让它自动找出映射规律。常用算法:线性回归、决策树、支持向量机(SVM)、K均值聚类等。📌 关键点:ML 的本质是函数逼近——找到一个函数 f,使得 f(输入) ≈ 输出。深度学习(DL):用“深度神经网络”自动提取特征传统机器学习往往需要人工设计特征(比如“猫有尖耳朵、胡须”),而深度学习能自动从原始数据中逐层提取特征。核心技术:深度神经网络(DNN),尤其是:卷积神经网络(CNN):擅长处理图像循环神经网络(RNN)/Transformer:擅长处理文本和序列生成对抗网络(GAN):用于生成新内容(如AI绘画)为什么叫“深度”? 因为网络包含多个隐藏层(有时上百层),每一层都对数据进行一次抽象。例如:第1层识别边缘第2层组合成纹理第3层识别眼睛、鼻子最后层判断“这是一张人脸” 📌 关键点:DL 是 ML 的“自动化升级版”——连特征工程都省了,但需要海量数据和强大算力。二 AI和ML 区别机器学习(ML)是人工智能(AI)的一个特定分支。与 AI 相比,机器学习的范围和重点有限。AI 还包括一些机器学习范围之外的策略和技术。以下是两者之间的一些关键区别。目标任何 AI 系统的目标都是让机器高效地完成复杂的人类任务。此类任务可能涉及学习、解决问题和模式识别。另一方面,机器学习的目标是让机器分析大量数据。机器将使用统计模型来识别数据中的模式并生成结果。结果具有相关的正确概率或可信度。方法AI 领域包括用于解决各种问题的各种方法。这些方法包括遗传算法、神经网络、深度学习、搜索算法、基于规则的系统和机器学习本身。在机器学习中,方法分为两大类:有监督学习和无监督学习。有监督机器学习算法使用标有 input 和 output 的数据值来解决问题。无监督学习更具探索性,它试图在未标记的数据中发现隐藏的模式。 实施构建机器学习解决方案的过程通常涉及两项任务:选择并准备训练数据集选择先前存在的机器学习策略或模型,例如线性回归或决策树数据科学家选择重要的数据特征并将其输入到模型中进行训练。他们通过更新的数据和错误检查来不断完善数据集。数据的质量和多样性提高了机器学习模型的准确性。 构建 AI 产品通常是一个更为复杂的过程,因此许多人选择预先构建的 AI 解决方案来实现他们的目标。这些 AI 解决方案通常是经过多年研究后开发的,开发人员可以通过 API 将其与产品和服务集成。要求机器学习解决方案需要使用包含数百个数据点的数据集进行训练,还需要足够的计算能力才能运行。根据您的应用程序和用例,单个服务器实例或小型服务器集群可能就足够了。其他智能系统可能有不同的基础设施要求,这取决于您想要完成的任务和所使用的计算分析方法。高计算用例需要数千台机器协同工作才能实现复杂的目标。但是,请务必注意,预先构建的 AI 和机器学习函数都可用。您可以通过 API 将它们集成到您的应用程序中,而无需额外资源。三 ML和DL 区别机器学习包括传统的机器学习与深度学习接下来我们具体介绍下机器学习(传统机器学习)与深度学习的区别及联系!学习方法机器学习:基于数据和算法,通过训练数据来调整模型参数,从而实现预测和分类等功能。常见的机器学习算法 包括线性回归、决策树、支持向量机等。深度学习:使用神经网络模型,通过反向传播算法和梯度下降优化技术来调整网络权重和参数。常见的深度学习模型 包括卷积神经网络(CNN)、循环神经网络(RNN)、Transformer等。数据需求机器学习:需要足够的数据来训练模型,但并不一定需要全部数据。可以通过特征选择、降维等技术来处理大规模数据集 。深度学习:需要大量的数据进行训练,尤其是对于复杂的任务和模型。通常需要使用无监督学习进行预训练,以减少对大规模数据集的需求。模型的复杂性机器学习:模型通常较为简单,主要是线性模型和统计模型等。模型的复杂度取决于所选择的算法和特征工程。深度学习:模型通常非常复杂,具有大量的神经元和层数。通过逐层传递信息,深度学习模型能够自动提取和抽象出有用的特征。优缺点机器学习:优点在于其预测准确度高,适用于各种类型的数据和任务;缺点是需要足够的数据和特征工程,对于复杂任务的建模能力有限。深度学习:优点在于其强大的表示能力和泛化能力,能够处理复杂的非线性问题;缺点是计算量大、训练时间长,对于大规模数据集的需求较高。应用领域机器学习:应用领域包括推荐系统、数据挖掘等。例如,使用支持向量机进行文本分类或使用决策树进行预测。深度学习:应用领域主要为图像识别、语音识别、自然语言处理等。例如,使用卷积神经网络进行图像分类或使用循环神经网络进行文本生成。两者区别(总结)模型层面:机器学习是基于传统模型(统计学习模型、KNN等等);深度学习则使用神经网络模型进行学习和预测。应用方面:机器学习适用于各种类型的数据和任务;深度学习则更适用于处理复杂的非线性问题。复杂度:深度学习的模型通常比机器学习模型更加复杂,需要更多的计算资源和训练时间。可解释性:机器学习:模型通常较为简单,因此具有一定的可解释性。例如,决策树和线性回归模型可以通过规则和系数来解释。深度学习:由于模型的复杂性和黑箱性质,通常难以解释。这使得深度学习在某些需要解释的场景中受到限制。鲁棒性:机器学习:一些传统的机器学习算法可能对噪声和异常值敏感。深度学习:通过强大的表示能力和鲁棒的网络结构,大数据加持的深度学习模型通常具有较好的鲁棒性,能够更好地处理噪声和异常值。数据标注需求:机器学习:许多传统的有监督机器学习算法需要一些标注数据,主要视模型复杂度具体来看,一些简单模型样本需求并不高,几百个也可以支持。深度学习:深度学习模型通常需要大量的标注数据,尤其是对于复杂的任务。然而,深度学习无监督学习和其他技术也可以减少对大量标注数据的需求。部分内容来源于:https://blog.csdn.net/python122_/article/details/138791308 -
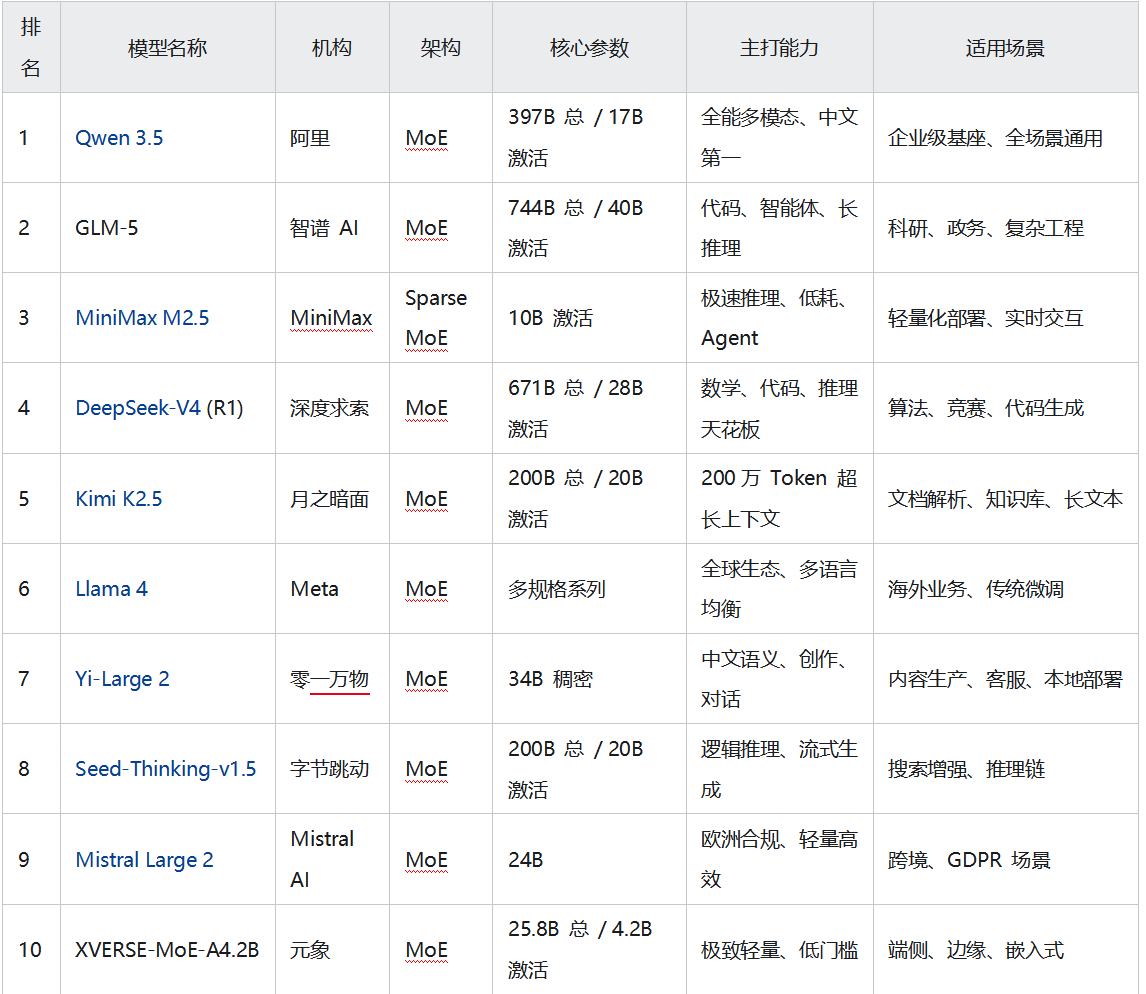
2026 年开源大模型 TOP10 2026 年,开源大模型彻底告别“参数内卷”,进入效率优先、场景为王、生态成熟的普惠时代。 本文基于 Hugging Face 下载量、LMSYS 盲测、工程化落地成本、商用友好度、社区活跃度 五大维度,发布 2026 全球开源大模型 TOP10 权威榜单。榜单呈现一个明确事实: 全球开源 TOP10 中,中国模型占 8 席;MoE 架构成为绝对主流;国产模型在中文、推理、代码、多模态全面领跑。一、2026 开源大模型 TOP10 完整榜单(权威版)二、TOP10 模型深度解读Qwen 3.5 —— 全球开源综合之王总参数 397B,仅激活 17B,性能直逼 Gemini 3、GPT-5.2原生多模态,支持 201 种语言Hugging Face 全球下载量、综合评分双第一商用友好、文档齐全、生态最完善定位:企业级通用基座首选GLM-5 —— 开源代码与智能体之王744B 总参数,激活 40BSWE-bench 开源第一,代码通过率 77.8%支持复杂智能体、多工具协同、长链思考政务、学术、金融工程首选定位:高端研发与系统工程基座MiniMax M2.5 —— 性价比与速度之王轻量 MoE,推理成本仅为旗舰模型 1%低延迟、高吞吐,适合实时交互原生支持 Agent 工作流定位:中小企业、快速落地、API 服务DeepSeek-V4 (R1) —— 数学推理之王MATH 准确率 61.6%,HumanEval 65.2%开源模型中推理能力最接近 GPT-4o长思考、自验证、代码调试极强定位:科研、竞赛、高逻辑需求场景Kimi K2.5 —— 长文本处理之王支持 200 万 Token 上下文文档摘要、表格解析、PDF/Excel/PPT 全链路处理C 端用户量最大的开源模型之一定位:知识管理、办公自动化、法律/医疗文档Llama 4 —— 欧美生态根基Meta 官方旗舰开源 MoE海外资源最多、教程最丰富多语言均衡,但中文弱于国产定位:出海业务、传统 LLM 迁移Yi-Large 2 —— 中文稠密模型标杆34B 稠密架构,部署简单、稳定性高中文理解、情感、文案生成顶尖消费级显卡可流畅运行定位:个人开发者、轻量化企业服务Seed-Thinking-v1.5 —— 推理链专项强者字节开源,专注深度逻辑与流式推理AIME、Codeforces 等难题平均准确率超 75%三级并行,吞吐量极高定位:搜索增强、逻辑问答、智能诊断Mistral Large 2 —— 欧洲合规首选轻量高效、GDPR 合规小参数、强泛化、低部署成本欧洲市场占有率第一定位:跨境业务、欧盟区企业服务XVERSE-MoE-A4.2B —— 端侧部署王者仅激活 4.2B 参数,性能媲美 13B 模型全开源、免费商用边缘设备、手机、IoT 可运行定位:端侧 AI、嵌入式、低成本硬件三、2026 开源大模型三大趋势MoE 架构彻底统治市场几乎所有 TOP 模型均采用 MoE:总参数大 → 能力强激活参数小 → 成本低、速度快 稠密模型仅在轻量场景保留。中国开源力量全球主导TOP10 中 8 个来自中国Hugging Face 中文模型下载占比超 60%中文理解、工程化、性价比全面领先从“通用”走向“场景专精”推理型代码型长文本型端侧轻量型多模态型 选模型 = 选场景,不再唯参数论四、2026 开发者实战选型指南企业通用基座 → Qwen 3.5代码/智能体 → GLM-5低成本/高并发 → MiniMax M2.5数学/推理 → DeepSeek-V4长文档/知识库 → Kimi K2.5端侧/边缘 → XVERSE-MoE-A4.2B出海/多语言 → Llama 4 / Mistralhttps://zhuanlan.zhihu.com/p/2009705203163752429
-
-
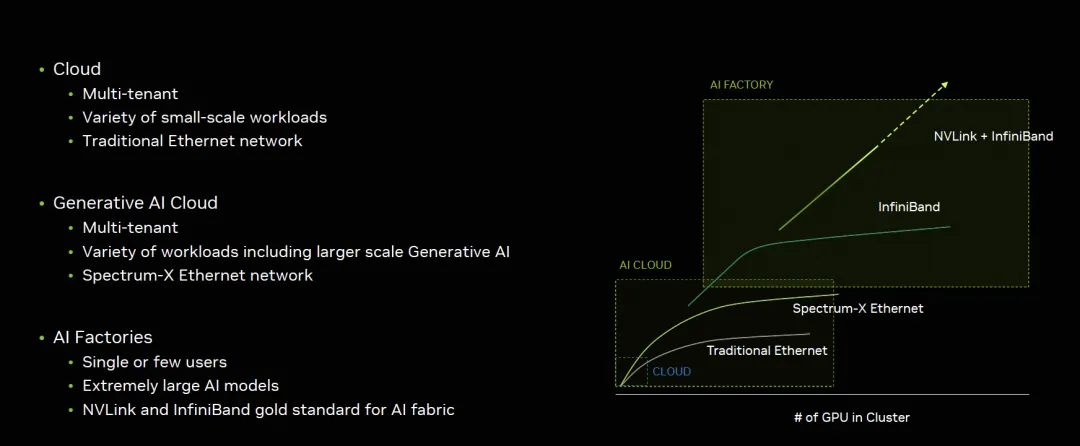
英伟达GB200架构解析2:谈谈AI工厂和AI云的技术和商业逻辑 原创/还呗 zartbot2024年03月31日22:36浙江从技术路径上来看,GB200的互联系统大概有三个方式, 英伟达的市场策略是很明晰的,如图所示:对于生成式的AI云和AI工厂的最大区别在于租户不同,单一任务规模不同,底层技术上也通过支持以太网的Spectrum-X和Infiniband/NVLINK互联区分,那么这三个解决方案就更加清楚了:互联方式 使用场景NVL72 + Infiniband AI工厂标配NVL576 + Infiniband AI工厂土豪特选NVL72 + Spectrum-X 生成式AI云服务另外又有一个思科和英伟达合作,在GTC上的Session谈到一个根本性的问题:自建还是租?结论很有趣:两者都会存在,但是需要像Cloud那样的使用体验?云的体验是什么?本质上是一个算力证券化的过程。体验统一了,背后的分歧应该只是商业模式上的,是买还是租,或者采用融资租赁等金融工具来买?而实质的技术上不应该有分歧,如果我们把它定义成AI CLOUD-X,对比如下右图所示,这背后又需要什么样的技术呢?其实很多人没有明白云的价值是什么,基本上还是跟IDC混为一谈。根本的区别是云是一个算力金融机构,流动性(弹性)和安全(多租户)是它的根本。比尔盖茨曾说过:"Banking is neccesary, Banks are not". 王坚博士讲过:"计算,为了无法计算的价值(Computing for Value Beyond Computation)". 本质上博士也是在阐述计算的价值,那么照着写一句:"Computing is neccesary, Computers are not". 这样来看更有云计算的味道,又有了几分Serverless,Datacenter as a computer的意境。云服务提供商和金融机构具有太多的共性,具体的内容可以参考以前的一篇文章《从金融的视角谈云计算》从商业逻辑上来看AI工厂和AI云1.1 模型规模和弹性通常金融机构盈利的主要策略是“借短投长”,对于期限错配和流动性风险的管理是金融机构必须要关注的。而对于GB200这样的算力投资来看,云计算厂商考虑的也是类似的逻辑。一次性长期投资下,如何能够尽量的通过频繁的短期租赁来获取收益?对于超大规模Foundation模型的训练,也就是AI工厂的范畴看,参与者基本上也就会收敛到20家左右,并且训练都是持续数个月的,对于云来说更多的是考虑一种非弹性的融资租赁模式,盈利模式可能更多的是在换代后的推理收益上,下面以一个例子来解释:例如微软给OpenAI训练GPT-5用了100,000片H100,这些投资前期可能以很低的毛利供给给OpenAI,因为这些长期包年包月的服务并不具有流动性溢价,特别是在国内有多个智算中心的大背景下。而在两年后B100集群上量后,这100,000片H100将拆分出来用于FineTune和推理等业务。从整个H100的生命周期而言,从现金流的角度来看,中短期内是一个收益率较低的持续稳定现金流,而中长期则是一个看推理/FineTune市场的收益率相对高一些的弹性售卖的逻辑,但是现金流本身和流动性息息相关和售卖率也相关,因此也可以看到英伟达和云对大模型公司的投资,其实是在进行算力的流动性风险管理, 为整个现金流寻找确定性。因此从现金流来看,AI云服务提供商和AI工厂有着巨大的差异,因此Build or Rent的逻辑更多的可能还是在每个企业如何衡量自身的现金流上, 例如企业自身还可以通过融资租赁的方式来Build替代Rent from Cloud,背后的成本核算是一个很有趣的话题, 例如学过CFA/FRM的人基本上都懂债券的Barbell或者Bullet两种策略以及其凸性,那么针对AI场景下的ROI分析可能是一个因子更多的问题, 不光是基础设施投资回报还有模型带来的经营收益回报上,后面会针对投资回报率相对确定的搜广推做一些分析。1.2 弹性视角下的AI云现阶段AI集群存在三套网络一个是NVLink这样的Scale-Up网络,另一个是基于RDMA的东西向Scale-Out网络,还有一套是原有的Front-End 存储/管控和南北向流量,今年GTC上Gilad有个演讲《Entering A New Frontier of AI Networking Innovation》[1],也提到了类似的区分针对网络中的数据流量分为东西向和南北向,主要差异在计算紧耦合/长尾抖动容忍度低/突发强等,宏观的秒级监控来看平均带宽中等,但是微观上突发这也是英伟达宣称为什么传统以太网无法解决,必须要Spectrum-X技术,或者UEC联盟/ OCP-Falcon 需要解决的问题。从云的经营视角来看,更多的是关注弹性部署的问题,除了Azure使用Infiniband外,另外两大云服务提供商AWS/GCP似乎都没有独立的Scale-Out网络,并且都在传统以太网上通过在其DPU上实现了EFA/Falcon协议来支持,例如AWS部署的GH200 NVL32全部使用了Nitro EFA组网,并没有特别的东西/南北流量区分,而事实上这些技术问题确实可以解决并共存,后面第二章我们将详细分析。1.3 AI云服务提供商选择Scale-Up和Scale-Out的平衡对于云服务提供商而言除了整合Scale-Out和Front-End网络外,还有一个非常重要的话题是Scale-Up和Scale-Out的平衡,AI工厂可能有一些更极端的逻辑去追求极致的性能和探索更大规模的模型,但是上一代的NVL256和这一代的NVL576基本上没有客户买单,AI云服务提供商依旧选择了NVL72,甚至英伟达的推荐也是。在这次GTC《The Next-Generation DGX Architecture for Generative AI》[2]它通过576个Blackwell GPU构成一个Building block,并称其为hot-aisle containment closet (HAC),可以看到其内在的逻辑是考虑到物理约束/功耗限制/液冷散热等情况通常由一组互相备份的分布式制冷单元CDUs (cooling distribution units),配合16个机柜构成,每列机柜包含8个NVL72计算机柜和8个互联的支持机柜通过Infiniband构建的Scale-Out网络拓扑如下:可以看到在单个Pod内构建的576卡集群Scale-Out网络是1:1收敛的,而多个Pod之间的互联并没有构成1:1收敛。整个系统通过这样的两列Sub-HAC构成:最终通过把大量的sub-HAC连接构成一个32,000卡的集群官方的介绍中基本上没看到有NVL576的方案,只有在安费诺的一个和连接器相关的Session中介绍了一部分,例如铜缆转光模块的笼子,不确定NVSwitch上闲置的两根线是否跟这个有关从云服务提供商的视角来看,GB200NVL这样的平台比DGX B200的平台更符合云服务提供商对业务弹性的需求,相对于单机8卡,GB200可以按照单机两卡售卖拆散了售卖,同时又可以组装起来构成一个NVL72的大系统。当然对云服务提供商的ROI还需要更多的定量分析,只是个人大概估算了一下GB200NVL的ROI会远高于B200,因为产品中后期的弹性售卖能力和故障恢复能力远高于B200的平台。1.4 AI云的任务编排和调度另一方面是网络带来的冲突和拥塞控制上,对于大规模AI工厂,通过对节点的编排可以很好的避免冲突。但是对于多租户的AI云场景下由于弹性售卖的逻辑,多个任务调度编排难度极大,编排不当会导致性能损失:而这个问题通过特殊的交换机和DPU也可以解决,但是英伟达的方案并不干净,必须要使用无损 刚性兑付的网络当然,通过这些技术可以使得整个云服务提供商对Job编排做到位置无感知,可以更好的提供弹性售卖的能力AI云基础设施建设上和AI工厂最大的区别就在于此,它需要考虑GPU生命周期中后期的弹性售卖逻辑支撑多租户和灵活的资源调度编排能力,和碎片化的资源售卖能力。关于英伟达Spectrum-X具体内容可以参考《谈谈英伟达的SpectrumX以太网RDMA方案》从技术上分析如何实现AI Cloud-X是否存在一个技术能够完成AI工厂超大规模的Foundation模型训练,又能够完成在生命周期的中后期能够弹性售卖?三套网络看上去是不太合理的例如GPU针对SORA类应用要从存储拉数据,或者云上需要弹性售卖时,从Front-End到CPU再PCIe灌入GPU显得有些瓶颈。而针对GB200这类业务,其实Front-End的网络带宽也大大提升了。随着SCALE-UP的能力增强对SCALE-OUT网络的依赖也会越少。这一些问题是值得我们去探讨的。2.1 SCALE-OUT和SCALE-UP合并这是来自于BRCM投资者交流日的胶片:伴随着CPO和1.6T以太网,这样的合并价值可能会凸显出来,这也是英伟达未来一代的演进趋势,构建光互联的系统概念图如下:最终构建一个超大规模的光互联系统2.2 SCALE-OUT和Front-End合并对于AI这些推理应用落地场景最多的搜广推业务,存在大量的CPU实例和GPU实例的交互。例如Meta的一个数据:事实上针对实时推荐系统来看,十亿级用户行为的捕获,进入Flink这些系统后,用户行为数据通常需要快速的进入推荐系统进行存储并构建Embedding,而伴随着大模型在线推理业务的部署,RAG/AGENT等对向量数据库的需求上都会要求CPU和GPU系统之间有更大的带宽进行通信。注:对于大模型用于搜广推和GH200/GB200的优势,我们将在下一篇文章中详细阐述。Grace-Blackwell这些直接CPU和GPU之间通过C2C互联是一种解法,另一种做法就是Front-End和SCALE-OUT网络合并互联。例如Google在其A3 H100实例上就是这样的部署方式,任何一个通用CPU计算的VM都可以直接通过FRONT-END连接到起SCALE-OUT网卡,事实上也就证明了GCP已经完成了SCALE-OUT和FRONT-END网络的合并,并且协议也没有采用ROCEv2,而是为了兼容有损的FRONT-END网络采用了GPUDirectTCPX或者未来的Falcon。对于AWS的NVL32和NVL72的系统依旧会采用其Nitro构建的EFASRD。对于英伟达,Jensen在和投资者交流的会议中还在提及无损网络和AR,以及如何实现Noise Isolation等,但事实上有损网络支撑SCALE-OUT网络已经在工业界落地,只需要一些非常优雅的多路径转发和拥塞控制算法即可,这一点上我们也通过上一代传统交换网络进行了验证,并不需要什么超级以太网的新型交换机支撑。结论本文从生成式AI云服务经营的视角来分析了云对弹性多租的需求,但同时也存在和AI工厂之间的一系列差异,这些差异在商业模式上和技术路径演进上都存在。对于云服务提供商而言,其未来演进会存在一系列网络合并,无论是博通还是英伟达都有明确的路径,另一条路是AWS和GCP。当然GCP还特殊一点,其AI工厂还有TPU这一条线支撑。参考资料[1]Entering A New Frontier of AI Networking Innovation: https://static.rainfocus.com/nvidia/gtcs24/sess/1707189722732001l46P/FinalPresPDF/S62293a%20-%20Entering%20A%20New%20Frontier%20of%20AI%20Networking%20Innovation_1711040929732001ayMI.pdf[2]The Next-Generation DGX Architecture for Generative AI: https://static.rainfocus.com/nvidia/gtcs24/sess/1696188785866001bSLb/FinalPresPDF/S62421_1711139422506001ouGg.pdf
-