搜索到
29
篇与
的结果
-
 AI专题十四:大模型运行和多用户支持 1 一台服务器的部署的一个大模型同时支持多个用户的同时进行推理的原理是什么?多个用户同时使用不会造成计算混乱吗?核心原理:模型是“静态”的,请求是“动态”的你可以把训练好的大模型想象成一个巨型的、复杂的、只读的数学函数(参数文件)。这个函数本身是固定的,不会因为不同人使用而改变。多个用户的并发使用,实际上是依次或并行地向这个“函数”传入不同的输入数据(即用户的提问),并各自得到独立的输出。技术实现的关键点:服务化与请求队列模型被封装成一个推理服务。当多个用户同时发送请求时,这些请求会进入一个请求队列。服务端有一个调度器负责从队列中取出请求,组织计算。计算图与批处理这是并发的核心技术。服务器在加载模型时,会将模型结构预先编译成一个高效的静态计算图(尤其是在使用TensorRT、Triton等推理优化框架时)。批处理:调度器不会一次只处理一个请求,而是会将短时间内收到的多个请求(即使来自不同用户)组合成一个“批”,一次性送入GPU进行计算。例如,用户A的“写一首诗”和用户B的“翻译一句话”这两个请求,可能被组合成一个批次(batch size=2)输入模型。优势:GPU拥有数千个核心,擅长并行计算。批处理能极大地提高GPU的利用率和吞吐量,让硬件“吃饱”,从而服务更多用户。这就像烤箱一次烤10个面包,远比一个一个烤高效。内存与上下文隔离这是解决“混乱”问题的关键。模型参数共享:所有用户共享同一份模型参数,它们常驻在GPU显存中,只读,不会互相影响。计算上下文独立:每个用户的请求都有自己独立的内存空间,用于存储其输入的词元、计算过程中产生的中间激活值、以及独有的对话历史(KV Cache)。服务器框架会为每个请求维护独立的上下文,确保用户A的数据绝不会混入用户B的计算中。分时复用与流式输出分时复用:对于无法组成批次的请求,或者长序列请求,调度器会采用分时策略,快速在多个计算任务间切换。由于GPU计算速度极快,给用户的感知仍然是“同时”在响应。流式输出:为了提升用户体验,模型通常以流式方式逐个词元生成文本。服务器可以同时管理多个这样的“流”,分别推送给不同的用户。一个简单的比喻:中央厨房将大模型服务器比作一个高度自动化的中央厨房:模型:就是厨房里固定不变的、复杂的菜谱(函数)和厨具设备(GPU)。厨师(GPU核心):可以同时处理多份订单。订单(用户请求):来自不同顾客。批处理:厨师一次性腌制10块牛排(一个批次),而不是一块一块地腌,效率大增。隔离:每份订单都有独立的餐盘和包装,绝不会把顾客A的酱汁打到顾客B的菜里。调度器:是餐厅经理,负责接收订单、安排厨师工作、将做好的菜分送给正确的顾客。总结:为什么不会混乱?状态隔离:每个用户的会话和计算上下文在内存中是逻辑隔离的。参数只读:模型本身作为基础模板,不被任何单一请求改变。有序调度:通过请求队列、批处理、分时等调度技术,系统有条不紊地处理并发请求,最大化硬件效率。专用框架:使用如 vLLM, TGI, Triton Inference Server 等专业推理服务器框架,它们正是为高效、稳定地处理高并发推理场景而设计的。所以,单个模型不仅能被多人同时使用,而且通过并发技术,服务提供商还能显著降低单次推理的平均成本,这正是AI服务能够大规模商业化的技术基石。2 一台服务器的部署的一个大模型支持的最大同时使用的用户数量是有哪些因素决定的?一台服务器能支持的最大并发用户数(或并发请求数)是一个性能容量规划问题,没有单一公式可以直接算出,但可以通过系统化的方法来估算。它取决于硬件、模型、工作负载和服务质量(QoS)四大类因素的复杂交互。以下是你提到的 32张H100服务器(假设为戴尔PowerEdge,搭配高速互联) 场景下的关键决定因素和估算方法。一、 四大决定因素硬件极限GPU算力(FLOPs):H100的FP16张量核心峰值算力极高,但实际利用率取决于模型和优化程度。推理通常是内存瓶颈或通信瓶颈,而非算力瓶颈。GPU显存(容量与带宽):这是最硬性的约束。模型参数、KV缓存、激活值、批处理数据都存储在显存中。参数占用:例如,一个70B参数的FP16模型需要约140GB显存。KV缓存占用:这是大模型推理的“内存杀手”。每个并发请求的序列越长,KV缓存占用越大。公式大致为:2 层数 隐藏维度 序列长度 批大小 * 精度(字节)。这直接限制了能同时“保持活跃”的请求数。HBM带宽:自回归生成是“内存带宽受限”操作,每次生成一个token都需要从显存读取整个模型参数(或大部分)。因此,显存带宽决定了生成token的极限速度。互联带宽:在32张卡上进行张量并行或流水线并行时,GPU间的通信(NVLink, NVSwitch)可能成为瓶颈。通信开销会降低计算效率。模型特性参数量与架构:模型越大,单次前向传播的计算量和内存占用越大。优化程度:量化:使用FP8或INT4量化,可以将参数和激活值占用的显存减半或更多,从而显著增加并发容量。内核融合/定制化内核:使用像FlashAttention这样的优化内核,可以减少内存访问、提升速度。连续批处理/动态批处理:这是现代推理服务器(如vLLM, TGI)的核心功能。它允许不同请求的序列被高效地打包在一个批次中,动态更新KV缓存,极大提升GPU利用率和并发支持数。工作负载特征(用户行为)请求到达模式:是平稳流还是突发高峰?输入长度(Prompt Tokens):用户提问的长度。输出长度(Generation Tokens):模型回复的长度。这通常更重要,因为生成是自回归的,每个输出token都需要一次完整的前向传播。请求频率:单个用户在收到上一个回复后,多快会发送下一个请求?服务质量要求延迟(Latency):用户能容忍的响应时间。首Token延迟(TTFT):从发送请求到收到第一个token的时间。这受批处理等待、计算初始提示影响。Token间延迟(TPT):后续每个token的生成速度。高延迟容忍度意味着系统可以积累更大的批处理尺寸,从而提高吞吐量和并发用户数。反之,低延迟要求会限制批处理大小,降低并发能力。二、 估算方法与步骤(以70B模型为例)这是一个从吞吐量倒推并发用户数的简化流程。你需要先设定目标延迟和典型用户行为模式。步骤1:确定单次请求的“计算负载”假设一个典型请求:输入长度(I): 512 tokens输出长度(O): 256 tokens总处理量: 模型需要为这个请求计算 I + O 次前向传播(实际上,计算提示是一次性并行计算I个token,生成则是串行进行O次)。但更关键的指标是 “每用户每秒处理的Token数(Token/s/user)”。步骤2:测量系统在目标延迟下的最大吞吐量这是必须通过实际基准测试得到的核心数据。你需要:将70B模型以最优的并行策略(如张量并行TP=8,即8张卡服务一个模型实例)部署在32张H100上。那么你可以运行 4个这样的模型实例(32/8=4),每个实例独立处理请求,实现多副本并行以提高总吞吐。使用基准测试工具,模拟不同并发请求数,测量在满足目标延迟(如TTFT < 2s,TPT < 50ms) 的前提下,整个系统(4个副本)的:总吞吐量(Throughput): 单位是 Tokens/秒。假设:在目标延迟下,测得系统总吞吐量为 T_total = 40,000 Tokens/秒。步骤3:定义典型用户场景假设每个用户的平均请求间隔(从收到完整回复到发送下一个请求)为 R 秒。例如,一个聊天机器人场景,用户平均每10秒发送一条新消息。那么:每个用户对系统的平均需求吞吐量 = (I + O) tokens / R seconds。以上述数字为例:每个请求总tokens为768,R=10秒,则每用户平均需求吞吐 = 76.8 Tokens/秒/用户。步骤4:计算最大支持用户数理论最大并发用户数 = T_total / (每用户平均需求吞吐) = 40,000 / 76.8 ≈ 521 用户。这是平均情况。如果所有用户同时发送请求(突发),系统需要使用队列,并且瞬时并发请求数会受到KV缓存容量和调度器的限制。步骤5:用KV缓存容量进行校验这是更硬性的即时约束。假设:模型层数 L=80,隐藏维度 H=8192,使用FP16存储KV缓存(2字节)。系统为每个请求分配的最大序列长度为 2048 tokens。单张H100 80GB显存中,除去模型参数和其他开销,可用于KV缓存的空间约为 50GB。则单张GPU上能同时活跃的请求数(批大小)上限为: KV缓存容量 / (2 L H 序列长度 2字节) = 50GB / (2 80 8192 2048 2) ≈ 50e9 / (5.36e9) ≈ 9个请求。如果你使用TP=8,那么一个模型实例(跨8张卡)的批大小上限也大致是这个数量级(因为KV缓存是并行分散的)。那么4个副本的总瞬时并发请求数上限约为 9 * 4 = 36个。这里出现了关键区别:吞吐量估算的用户数(521):是随时间平均的用户数,系统通过快速处理请求,在1秒内可以服务很多用户,但不是同时。KV缓存限制的并发数(36):是同一时刻正在被处理(处于生成过程中)的活跃请求数。在连续批处理调度下,系统会在极短的时间窗口(毫秒级)内循环处理这些活跃请求,快速切换上下文。因此,系统能支持的总在线用户数可以远高于36,只要他们的请求不是严格同时到达,而是错开的。36代表的是系统的“瞬时并发处理深度”。三、 结论与公式提炼对于你的32张H100服务器,支持的最大同时在线用户数(满足一定响应延迟)取决于:瞬时并发硬上限: 瞬时并发请求数 ≈ (总GPU显存可用于KV缓存的部分) / (单个请求的KV缓存占用) 这由模型架构、序列长度和GPU数量决定。可持续吞吐软上限: 平均支持用户数 ≈ (系统在目标延迟下的总吞吐 Tokens/秒) / (每个用户的平均Token需求速率 Tokens/秒/用户) 这由GPU算力/带宽、优化程度、用户行为模式决定。实际生产中:你会先用KV缓存容量估算出瞬时并发批处理大小(例如36)。然后通过基准测试,测量在这个批处理大小下,系统的吞吐量(Tokens/秒)和延迟。最后根据用户行为模型,计算能支持多少用户。给你的直接建议: 如果你想估算32张H100对特定模型(如Llama3 70B)的容量,可以:查找该模型在类似硬件(如8xH100)上的公开基准测试数据(vLLM、NVIDIA TensorRT-LLM等发布的Benchmark)。关注其 “每秒生成Token数” 和 “支持的最大并发请求数” 指标。按比例(4个副本)进行外推,并结合你的业务场景用户模型进行计算。最终,真实的容量必须通过在生产负载下的压力测试来验证,因为用户行为往往是不可预测的,且软件栈的优化水平对性能有巨大影响。3 多个用户同时使用时,状态隔离:每个用户的会话和计算上下文在内存中是逻辑隔离的;有序调度:通过请求队列、批处理、分时等调度技术 , 这些机制是在哪里实现的?是AI 服务器的操作系统?还是GPU的kernel 还是什么软件代码?您提到的这些机制,是由一整套分层的软件栈协同实现的,从高层的应用框架一直到底层的硬件驱动。没有一个单一组件(如操作系统或GPU内核)能独立完成这一切。下面我为您拆解这些机制具体在哪里实现:一、状态隔离的实现层状态隔离的核心是为每个请求独立管理其对话历史(KV缓存)和计算中间状态。推理框架/服务器层(如vLLM、TGI、Triton)这是实现逻辑隔离的核心层。 框架会为每个进入系统的请求创建一个唯一的“请求句柄”或“序列对象”。该对象内部维护着该请求专属的:输入Token IDs已生成的输出Token IDs指向其独占的KV缓存内存块的指针。在像vLLM这样的框架中,其核心创新PagedAttention技术,就像操作系统的虚拟内存管理器一样,将不同请求的KV缓存分配在不同的、可独立换入换出的“内存页”中,从物理存储上就保证了隔离。GPU内核与运行时层当框架发起一次批处理计算时,它会告诉底层计算内核(Kernel):“这是批处理A,包含用户1、用户2、用户3的数据,他们的KV缓存地址分别在X、Y、Z。”定制化的GPU计算内核(如FlashAttention的变体) 在计算注意力时,会根据框架传入的地址,精确地从显存的不同位置读取属于每个请求的KV缓存,并在计算后写回原处。内核代码本身被设计为能根据索引正确处理批次中不同序列的数据。二、有序调度的实现层调度是将无序、海量的用户请求转化为高效、有序GPU计算指令的过程。调度器(Scheduler) - 位于推理框架内这是调度的大脑,是框架代码的一部分(如vLLM的Scheduler模块)。它维护着多个队列:等待队列:存放新到达的请求。运行队列:存放正在被预填充(处理Prompt)或生成(Generation)的请求。交换队列:管理因显存不足而暂时被换出到CPU内存的请求状态。它做出所有关键决策:何时进行批处理(Batching):等待一小段时间(例如几毫秒)以收集更多请求,组成更大的批次,提升吞吐量。批次的构成(Continuous Batching):这是现代框架的核心。它不会等一个请求完全生成完再处理下一个,而是动态地将新请求加入批次,同时将已生成完成的请求移出批次。这就好像餐厅经理不断安排新顾客入座,同时给吃完的顾客结账。何时抢占或交换:当高优先级请求到来,或显存不足时,决定暂停或换出哪些低优先级请求。GPU内核与硬件执行调度器决定“做什么”(批次的构成),而GPU硬件负责“快速地做”。GPU收到一个计算批次后,其数千个核心会并行地执行相同的指令(SIMT架构),但处理批次中不同序列的不同数据。分时(Time-sharing) 的效果,本质上是由调度器快速提交多个小的计算任务到GPU的命令队列(CUDA Stream)中,由GPU硬件高速串行执行而宏观上并发的。GPU计算速度极快(微秒级),这种切换对用户来说就是“同时”。三、技术栈全景图我们可以用一个从高到低的层次来看:总结与类比操作系统(OS) 就像是场地和基础服务提供商:它提供了建筑(内存空间)、电力(CPU调度)、物流通道(网络和PCIe总线)。但它不懂“烹饪AI模型”这个业务。推理框架(如vLLM) 就像是中央厨房的智能管理系统和经理:它设计工作流(调度)、管理食材库存(显存)、为每个订单分配独立的厨具和餐盘(状态隔离),并指挥厨师工作。GPU内核 就像是高度专业化、训练有素的厨师团队:他们严格按照工作指令(内核代码),同时、快速、精准地处理多个订单(批处理)中的不同步骤。因此,您所问的状态隔离和有序调度,其智能和逻辑核心是在“推理框架层”(如vLLM)中实现的。它充分利用了底层操作系统和GPU硬件提供的基础能力,但赋予了它们理解大模型并发推理这一特定业务场景的“智慧”。正是这些专用框架的出现,才使得大模型的高效、高并发服务成为可能。4 推理框架(如vLLM) 是在AI 服务器哪里实现的,操作系统安装某个推理框架(如vLLM) 的应用app 包吗?还是什么调度机制在哪里实现?您可以将推理框架看作是为大模型推理这个特殊任务而专门构建的一个高度特化的“智能操作系统”或“超级后台服务”。它运行在服务器的基础操作系统之上,但管理着GPU这个“第二王国”的一切。下面我为您具体拆解它在哪里、以及如何实现:一、推理框架是什么,安装在哪里?它不是操作系统的一部分,也不是一个简单的“应用商店APP”。像 vLLM, TensorRT-LLM, TGI 这样的推理框架,本质上是一个用Python/C++编写的、复杂的软件项目(或“服务程序”)。您通过服务器的命令行终端,使用Python包管理器(如 pip)或容器技术(如 Docker)将其“安装”到系统中。安装后,它是一系列可执行脚本和库文件,就像您安装了Nginx或MySQL数据库服务一样。它的运行形态:一个长期运行的守护进程当您启动服务时,通常会执行一条类似 python -m vllm.entrypoints.api_server --model=xxx 的命令。这会启动一个持续的进程。这个进程会:加载您指定的大模型权重文件到GPU显存。启动一个HTTP服务器(如FastAPI)监听特定端口(如8000),等待用户请求。初始化其核心的调度器、内存管理器等组件,并常驻内存,7x24小时运行。二、调度机制具体在哪里实现?这是最关键的部分。我们可以分层来看:第1层:用户空间应用层 - “调度决策中心”位置:在vLLM进程的内存空间里,具体是它的 Scheduler 和 Worker 等核心类的Python/C++代码中。功能:这是调度的“大脑”,负责高级决策。请求队列:当HTTP服务器收到用户请求后,将其转化为一个Request对象,放入Python代码中维护的等待队列。调度策略:调度器的代码逻辑(例如,vllm/core/scheduler.py)会周期性地检查队列,根据预设策略(如FCFS先来先服务,或是否优先处理短请求)决定:从等待队列中取出哪些请求。将它们与当前正在生成的请求动态组合成一个新的批处理。决定哪些已完成的请求该移出。内存管理:其PagedAttention内存管理器(同样是vLLM的Python/C++代码)负责为这个新批次中的每个请求分配或查找物理显存块,用于存储KV缓存,确保完全隔离。第2层:计算图与运行时层 - “命令编制部”位置:在PyTorch、CUDA Graphs或框架自有的引擎中。功能:调度器做出“要处理A、B、C用户请求”的决策后,需要将决策转化为GPU能执行的具体计算。框架会为这个特定的批次(包含不同长度、不同内容的请求)动态编译或调用一个预编译的计算图。这个计算图会精确地包含从显存哪个地址读取用户A的KV缓存,哪个地址读取用户B的输入等“低级指令”。第3层:GPU内核与驱动层 - “执行工厂”位置:在GPU上运行的定制化内核(Kernel)代码中。功能:这是调度的“肌肉”,负责最终执行。计算图最终会调用一系列高度优化的GPU内核函数(例如用CUDA C++编写的FlashAttention内核)。这些内核被设计为支持批处理:它们内部有逻辑,能根据一个“序列ID”或偏移量参数,在同一时间内,但为批次中不同的序列进行正确的计算。内核代码保证了计算在数学上的正确性和隔离性。分时的实现:当调度器快速连续地提交多个小批次任务到GPU的命令队列时,GPU硬件会以极高的速度串行执行它们,宏观上实现了并行。这是由NVIDIA驱动和GPU硬件调度器在纳秒/微秒级别完成的。三、一个简化的运行流程图用户请求 -> 网络 -> 服务器端口 ↓[vLLM 进程 - 常驻内存] ↓HTTP服务器接收请求(FastAPI代码) ↓放入内部等待队列(Python列表/队列对象) ↓核心调度器(Scheduler类)被触发决策:将请求A、B、C组成一个新批管理:为A、B、C分配独立的KV缓存页 ↓构建计算图(调用PyTorch/CUDA)输入:批数据 + A/B/C的KV缓存地址 ↓启动GPU内核执行GPU内核:并行计算,但数据各安其位 ↓获取结果,返回给对应HTTP连接四、重要总结:为什么不是操作系统内核?职责不同:操作系统内核(如Linux Kernel)的通用调度器,调度的是进程和线程这种通用计算单元。它对“大模型推理”、“KV缓存”、“自回归生成”这些领域特定知识一无所知。效率与灵活性:在用户空间实现的调度器(如vLLM的),可以用Python/C++快速实现复杂的、针对LLM优化的调度策略(如连续批处理、内存换入换出),并随时调整,无需修改操作系统内核。访问硬件:推理框架通过CUDA驱动API这个“特权通道”直接与GPU对话,绕过了操作系统对计算细节的管理,实现了极致性能。所以,答案是: 推理框架(如vLLM)是安装并运行在操作系统之上的一个独立的、专门化的后台服务进程。它最核心的调度机制,是在这个进程内部,由其自身用高级语言(Python/C++)实现的逻辑代码来完成的。 它就像是在通用操作系统之上,为AI计算这个特定领域建立的一个“自治王国”,拥有自己的法律(调度策略)、资源管理方式(显存分页)和军队(GPU内核)。5 一个AI服务器的一个大模型其实在同一时刻其实只有一个人使用是吗? 多个用户是按照时间片划分看起来在同时使用,如果使用用户过多,调度不过来,就需要排队?它不是纯粹的时间片轮转,而是两者的结合:既有真正的物理并行,也有时间上的交错。核心答案:既是“并行”,也是“交错”,排队是必然的“同一时刻只有一个人使用”是错误的现代GPU(如H100)拥有成千上万个核心,其设计初衷就是为了并行计算。推理框架通过批处理技术,会将多个用户的请求数据(输入的Token、各自的KV缓存)物理上打包成一个批次,一次性送入GPU。在这个批次的前向传播计算过程中,GPU的硬件是同时在为所有请求进行计算。例如,计算注意力分数时,矩阵运算会并行处理批次中的所有序列。所以,在计算微观层面,GPU确实在同一时刻为多个用户工作。“时间片划分”体现在哪里?关键在于自回归生成的过程。模型生成文本是一个“猜下一个词”的循环过程:第一步(预填充):并行处理整个批次中所有用户的输入提示(Prompt)。这是高度并行的。第二步(生成):为每个用户逐个生成输出Token。这个过程是交错并行的:调度器会执行一次前向传播,为批次中的所有活跃请求各生成一个Token。然后,将已生成完毕的请求移出批次,加入新的请求,再执行下一次前向传播。从每个用户的感受上看,他们是轮流收到下一个词的(例如用户A收到第1个词,用户B收到第3个词),宏观上像是“时间片”。但从GPU的视角看,每一次前向传播都是同时在为多个请求工作。“调度不过来,就需要排队”是完全正确的这发生在两个层面:进入运行队列前的排队:当新请求到达速率超过调度器能将其加入运行批次的速度时,请求会在等待队列中排队。KV缓存容量导致的排队:这是更根本的限制。GPU显存中能同时保存的“活跃请求”的KV缓存总数是有限的(如之前计算的,可能只有几十个)。一旦超过这个数,新请求就必须在等待队列中排队,直到有活跃请求完成、释放出其KV缓存空间后,才能被调度进来。一个更精确的比喻:中央厨房的炒菜流程延续之前的比喻:批处理(并行):厨师(GPU)同时将10份订单(一个批次)的牛排放进同一个大火炉(并行计算)烹煮。这是物理上的同时处理。交错生成(时间交错):每份牛排需要煎5分钟。厨师不是等一份煎完再煎下一份,而是同时开煎。但出锅时,由于订单要求不同(有的要5分熟,有的要7分熟),牛排会按各自的时间线依次出锅(对应每个请求流式输出Token)。排队:如果瞬间来了100份订单,厨房最多只能同时处理10份。另外90份就在订单接收区(等待队列)排队。只有当前面10份中的某份完成出锅、腾出了炉位,排队中的订单才能进入烹饪区。总结所以,实际情况是:GPU计算是并行的:硬件在同一时刻处理多个请求的数据。生成输出是交错并行的:每个请求按自己的序列逐个获得Token,宏观上像是轮流服务。排队不可避免:由于硬件资源(显存、算力)有限,当并发需求超过系统吞吐量或KV缓存容量上限时,排队必然发生。这正是为什么我们需要评估系统“最大支持用户数”的原因——这个数字本质上就是在可接受延迟下,系统能处理的平均请求速率。因此,您可以说“多个用户是共享同一个模型的计算资源”,但不是简单的单核CPU时间片轮转,而是更高效的、并行与交错相结合的高级调度。排队是系统保护自身、保证服务质量的自然机制。5 那就是GPU 在设计之初就支持多进程同时计算,这些进程的数据互补干扰,是这样吗?这是一个非常关键的问题。您的理解方向是正确的,但需要更精确地澄清“进程”和“干扰”的含义。GPU的并行能力:硬件基础GPU在设计之初的核心思想就是大规模并行计算。它拥有数千甚至上万个小而高效的计算核心(CUDA Core/Tensor Core),这些核心被组织成多个流多处理器(SM)。其架构擅长执行 “单指令,多线程” 的任务,即让大量核心同时执行相同的操作,但处理不同的数据。多进程与数据隔离:软件实现GPU硬件本身并不理解“进程”这个概念。数据隔离和不干扰是由软件栈(驱动、运行时、框架) 在硬件提供的并行能力之上实现的。多进程同时使用GPU:是的操作系统可以启动多个应用程序进程,每个进程都可以通过CUDA驱动向GPU提交计算任务。GPU硬件和驱动有能力快速切换、交错执行来自不同进程的计算任务(通过CUDA Stream等机制)。宏观上,多个进程“同时”在使用GPU。数据互不干扰:需要软件精心管理GPU本身不保证隔离:如果两个进程的程序错误地访问了相同的显存地址,数据就会互相干扰、覆盖。隔离是由软件层保障的:CUDA驱动/运行时:它为每个进程(或上下文)提供虚拟化的显存地址空间和管理,类似于操作系统为进程管理内存。这奠定了隔离的基础。推理框架(如vLLM):这是实现业务逻辑层面隔离的关键。它在上述基础之上,更进一步:会为每个用户请求精确分配独立的显存区域来存储其独有的KV缓存和中间数据。在启动GPU计算内核时,会传入精确的参数,告诉内核“请求A的数据在地址X,请求B的数据在地址Y”。内核代码则根据这些参数,确保在并行计算过程中,核心们处理的是各自正确的数据块,不会交叉混淆。一个技术层面的类比GPU硬件 像一个巨大的印刷厂,有成千上万个相同的印刷机(核心)。CUDA驱动 像印刷厂的调度员,可以接收来自多个客户(进程)的订单,并安排印刷机工作。推理框架 则像一个超级客户,它有一个大订单(运行大模型)。但它内部又把这个大订单拆分成无数个子订单(用户请求),并为每个子订单指定了专用的纸张和油墨(显存空间)。它告诉调度员:“请用印刷机同时印刷子订单A和B,但A用左边仓库的纸,B用右边仓库的纸。”印刷机(GPU核心)虽然同时运转,但因为拿的纸张和油墨来源不同,最终产品不会混淆。结论所以,答案是: 是的,GPU硬件设计支持并行计算,允许多个进程或任务同时利用其核心。但“数据互不干扰”并非由GPU自动保证,而是通过CUDA软件栈和上层推理框架(如vLLM)的精细内存管理和调度逻辑来实现的。 硬件提供了并行执行的“肌肉”,软件则提供了正确组织工作、避免混乱的“大脑”。因此,在您提到的AI服务器场景中,多个用户同时使用不会造成计算混乱,正是得益于这套从硬件底层到软件顶层的完整协作体系。
AI专题十四:大模型运行和多用户支持 1 一台服务器的部署的一个大模型同时支持多个用户的同时进行推理的原理是什么?多个用户同时使用不会造成计算混乱吗?核心原理:模型是“静态”的,请求是“动态”的你可以把训练好的大模型想象成一个巨型的、复杂的、只读的数学函数(参数文件)。这个函数本身是固定的,不会因为不同人使用而改变。多个用户的并发使用,实际上是依次或并行地向这个“函数”传入不同的输入数据(即用户的提问),并各自得到独立的输出。技术实现的关键点:服务化与请求队列模型被封装成一个推理服务。当多个用户同时发送请求时,这些请求会进入一个请求队列。服务端有一个调度器负责从队列中取出请求,组织计算。计算图与批处理这是并发的核心技术。服务器在加载模型时,会将模型结构预先编译成一个高效的静态计算图(尤其是在使用TensorRT、Triton等推理优化框架时)。批处理:调度器不会一次只处理一个请求,而是会将短时间内收到的多个请求(即使来自不同用户)组合成一个“批”,一次性送入GPU进行计算。例如,用户A的“写一首诗”和用户B的“翻译一句话”这两个请求,可能被组合成一个批次(batch size=2)输入模型。优势:GPU拥有数千个核心,擅长并行计算。批处理能极大地提高GPU的利用率和吞吐量,让硬件“吃饱”,从而服务更多用户。这就像烤箱一次烤10个面包,远比一个一个烤高效。内存与上下文隔离这是解决“混乱”问题的关键。模型参数共享:所有用户共享同一份模型参数,它们常驻在GPU显存中,只读,不会互相影响。计算上下文独立:每个用户的请求都有自己独立的内存空间,用于存储其输入的词元、计算过程中产生的中间激活值、以及独有的对话历史(KV Cache)。服务器框架会为每个请求维护独立的上下文,确保用户A的数据绝不会混入用户B的计算中。分时复用与流式输出分时复用:对于无法组成批次的请求,或者长序列请求,调度器会采用分时策略,快速在多个计算任务间切换。由于GPU计算速度极快,给用户的感知仍然是“同时”在响应。流式输出:为了提升用户体验,模型通常以流式方式逐个词元生成文本。服务器可以同时管理多个这样的“流”,分别推送给不同的用户。一个简单的比喻:中央厨房将大模型服务器比作一个高度自动化的中央厨房:模型:就是厨房里固定不变的、复杂的菜谱(函数)和厨具设备(GPU)。厨师(GPU核心):可以同时处理多份订单。订单(用户请求):来自不同顾客。批处理:厨师一次性腌制10块牛排(一个批次),而不是一块一块地腌,效率大增。隔离:每份订单都有独立的餐盘和包装,绝不会把顾客A的酱汁打到顾客B的菜里。调度器:是餐厅经理,负责接收订单、安排厨师工作、将做好的菜分送给正确的顾客。总结:为什么不会混乱?状态隔离:每个用户的会话和计算上下文在内存中是逻辑隔离的。参数只读:模型本身作为基础模板,不被任何单一请求改变。有序调度:通过请求队列、批处理、分时等调度技术,系统有条不紊地处理并发请求,最大化硬件效率。专用框架:使用如 vLLM, TGI, Triton Inference Server 等专业推理服务器框架,它们正是为高效、稳定地处理高并发推理场景而设计的。所以,单个模型不仅能被多人同时使用,而且通过并发技术,服务提供商还能显著降低单次推理的平均成本,这正是AI服务能够大规模商业化的技术基石。2 一台服务器的部署的一个大模型支持的最大同时使用的用户数量是有哪些因素决定的?一台服务器能支持的最大并发用户数(或并发请求数)是一个性能容量规划问题,没有单一公式可以直接算出,但可以通过系统化的方法来估算。它取决于硬件、模型、工作负载和服务质量(QoS)四大类因素的复杂交互。以下是你提到的 32张H100服务器(假设为戴尔PowerEdge,搭配高速互联) 场景下的关键决定因素和估算方法。一、 四大决定因素硬件极限GPU算力(FLOPs):H100的FP16张量核心峰值算力极高,但实际利用率取决于模型和优化程度。推理通常是内存瓶颈或通信瓶颈,而非算力瓶颈。GPU显存(容量与带宽):这是最硬性的约束。模型参数、KV缓存、激活值、批处理数据都存储在显存中。参数占用:例如,一个70B参数的FP16模型需要约140GB显存。KV缓存占用:这是大模型推理的“内存杀手”。每个并发请求的序列越长,KV缓存占用越大。公式大致为:2 层数 隐藏维度 序列长度 批大小 * 精度(字节)。这直接限制了能同时“保持活跃”的请求数。HBM带宽:自回归生成是“内存带宽受限”操作,每次生成一个token都需要从显存读取整个模型参数(或大部分)。因此,显存带宽决定了生成token的极限速度。互联带宽:在32张卡上进行张量并行或流水线并行时,GPU间的通信(NVLink, NVSwitch)可能成为瓶颈。通信开销会降低计算效率。模型特性参数量与架构:模型越大,单次前向传播的计算量和内存占用越大。优化程度:量化:使用FP8或INT4量化,可以将参数和激活值占用的显存减半或更多,从而显著增加并发容量。内核融合/定制化内核:使用像FlashAttention这样的优化内核,可以减少内存访问、提升速度。连续批处理/动态批处理:这是现代推理服务器(如vLLM, TGI)的核心功能。它允许不同请求的序列被高效地打包在一个批次中,动态更新KV缓存,极大提升GPU利用率和并发支持数。工作负载特征(用户行为)请求到达模式:是平稳流还是突发高峰?输入长度(Prompt Tokens):用户提问的长度。输出长度(Generation Tokens):模型回复的长度。这通常更重要,因为生成是自回归的,每个输出token都需要一次完整的前向传播。请求频率:单个用户在收到上一个回复后,多快会发送下一个请求?服务质量要求延迟(Latency):用户能容忍的响应时间。首Token延迟(TTFT):从发送请求到收到第一个token的时间。这受批处理等待、计算初始提示影响。Token间延迟(TPT):后续每个token的生成速度。高延迟容忍度意味着系统可以积累更大的批处理尺寸,从而提高吞吐量和并发用户数。反之,低延迟要求会限制批处理大小,降低并发能力。二、 估算方法与步骤(以70B模型为例)这是一个从吞吐量倒推并发用户数的简化流程。你需要先设定目标延迟和典型用户行为模式。步骤1:确定单次请求的“计算负载”假设一个典型请求:输入长度(I): 512 tokens输出长度(O): 256 tokens总处理量: 模型需要为这个请求计算 I + O 次前向传播(实际上,计算提示是一次性并行计算I个token,生成则是串行进行O次)。但更关键的指标是 “每用户每秒处理的Token数(Token/s/user)”。步骤2:测量系统在目标延迟下的最大吞吐量这是必须通过实际基准测试得到的核心数据。你需要:将70B模型以最优的并行策略(如张量并行TP=8,即8张卡服务一个模型实例)部署在32张H100上。那么你可以运行 4个这样的模型实例(32/8=4),每个实例独立处理请求,实现多副本并行以提高总吞吐。使用基准测试工具,模拟不同并发请求数,测量在满足目标延迟(如TTFT < 2s,TPT < 50ms) 的前提下,整个系统(4个副本)的:总吞吐量(Throughput): 单位是 Tokens/秒。假设:在目标延迟下,测得系统总吞吐量为 T_total = 40,000 Tokens/秒。步骤3:定义典型用户场景假设每个用户的平均请求间隔(从收到完整回复到发送下一个请求)为 R 秒。例如,一个聊天机器人场景,用户平均每10秒发送一条新消息。那么:每个用户对系统的平均需求吞吐量 = (I + O) tokens / R seconds。以上述数字为例:每个请求总tokens为768,R=10秒,则每用户平均需求吞吐 = 76.8 Tokens/秒/用户。步骤4:计算最大支持用户数理论最大并发用户数 = T_total / (每用户平均需求吞吐) = 40,000 / 76.8 ≈ 521 用户。这是平均情况。如果所有用户同时发送请求(突发),系统需要使用队列,并且瞬时并发请求数会受到KV缓存容量和调度器的限制。步骤5:用KV缓存容量进行校验这是更硬性的即时约束。假设:模型层数 L=80,隐藏维度 H=8192,使用FP16存储KV缓存(2字节)。系统为每个请求分配的最大序列长度为 2048 tokens。单张H100 80GB显存中,除去模型参数和其他开销,可用于KV缓存的空间约为 50GB。则单张GPU上能同时活跃的请求数(批大小)上限为: KV缓存容量 / (2 L H 序列长度 2字节) = 50GB / (2 80 8192 2048 2) ≈ 50e9 / (5.36e9) ≈ 9个请求。如果你使用TP=8,那么一个模型实例(跨8张卡)的批大小上限也大致是这个数量级(因为KV缓存是并行分散的)。那么4个副本的总瞬时并发请求数上限约为 9 * 4 = 36个。这里出现了关键区别:吞吐量估算的用户数(521):是随时间平均的用户数,系统通过快速处理请求,在1秒内可以服务很多用户,但不是同时。KV缓存限制的并发数(36):是同一时刻正在被处理(处于生成过程中)的活跃请求数。在连续批处理调度下,系统会在极短的时间窗口(毫秒级)内循环处理这些活跃请求,快速切换上下文。因此,系统能支持的总在线用户数可以远高于36,只要他们的请求不是严格同时到达,而是错开的。36代表的是系统的“瞬时并发处理深度”。三、 结论与公式提炼对于你的32张H100服务器,支持的最大同时在线用户数(满足一定响应延迟)取决于:瞬时并发硬上限: 瞬时并发请求数 ≈ (总GPU显存可用于KV缓存的部分) / (单个请求的KV缓存占用) 这由模型架构、序列长度和GPU数量决定。可持续吞吐软上限: 平均支持用户数 ≈ (系统在目标延迟下的总吞吐 Tokens/秒) / (每个用户的平均Token需求速率 Tokens/秒/用户) 这由GPU算力/带宽、优化程度、用户行为模式决定。实际生产中:你会先用KV缓存容量估算出瞬时并发批处理大小(例如36)。然后通过基准测试,测量在这个批处理大小下,系统的吞吐量(Tokens/秒)和延迟。最后根据用户行为模型,计算能支持多少用户。给你的直接建议: 如果你想估算32张H100对特定模型(如Llama3 70B)的容量,可以:查找该模型在类似硬件(如8xH100)上的公开基准测试数据(vLLM、NVIDIA TensorRT-LLM等发布的Benchmark)。关注其 “每秒生成Token数” 和 “支持的最大并发请求数” 指标。按比例(4个副本)进行外推,并结合你的业务场景用户模型进行计算。最终,真实的容量必须通过在生产负载下的压力测试来验证,因为用户行为往往是不可预测的,且软件栈的优化水平对性能有巨大影响。3 多个用户同时使用时,状态隔离:每个用户的会话和计算上下文在内存中是逻辑隔离的;有序调度:通过请求队列、批处理、分时等调度技术 , 这些机制是在哪里实现的?是AI 服务器的操作系统?还是GPU的kernel 还是什么软件代码?您提到的这些机制,是由一整套分层的软件栈协同实现的,从高层的应用框架一直到底层的硬件驱动。没有一个单一组件(如操作系统或GPU内核)能独立完成这一切。下面我为您拆解这些机制具体在哪里实现:一、状态隔离的实现层状态隔离的核心是为每个请求独立管理其对话历史(KV缓存)和计算中间状态。推理框架/服务器层(如vLLM、TGI、Triton)这是实现逻辑隔离的核心层。 框架会为每个进入系统的请求创建一个唯一的“请求句柄”或“序列对象”。该对象内部维护着该请求专属的:输入Token IDs已生成的输出Token IDs指向其独占的KV缓存内存块的指针。在像vLLM这样的框架中,其核心创新PagedAttention技术,就像操作系统的虚拟内存管理器一样,将不同请求的KV缓存分配在不同的、可独立换入换出的“内存页”中,从物理存储上就保证了隔离。GPU内核与运行时层当框架发起一次批处理计算时,它会告诉底层计算内核(Kernel):“这是批处理A,包含用户1、用户2、用户3的数据,他们的KV缓存地址分别在X、Y、Z。”定制化的GPU计算内核(如FlashAttention的变体) 在计算注意力时,会根据框架传入的地址,精确地从显存的不同位置读取属于每个请求的KV缓存,并在计算后写回原处。内核代码本身被设计为能根据索引正确处理批次中不同序列的数据。二、有序调度的实现层调度是将无序、海量的用户请求转化为高效、有序GPU计算指令的过程。调度器(Scheduler) - 位于推理框架内这是调度的大脑,是框架代码的一部分(如vLLM的Scheduler模块)。它维护着多个队列:等待队列:存放新到达的请求。运行队列:存放正在被预填充(处理Prompt)或生成(Generation)的请求。交换队列:管理因显存不足而暂时被换出到CPU内存的请求状态。它做出所有关键决策:何时进行批处理(Batching):等待一小段时间(例如几毫秒)以收集更多请求,组成更大的批次,提升吞吐量。批次的构成(Continuous Batching):这是现代框架的核心。它不会等一个请求完全生成完再处理下一个,而是动态地将新请求加入批次,同时将已生成完成的请求移出批次。这就好像餐厅经理不断安排新顾客入座,同时给吃完的顾客结账。何时抢占或交换:当高优先级请求到来,或显存不足时,决定暂停或换出哪些低优先级请求。GPU内核与硬件执行调度器决定“做什么”(批次的构成),而GPU硬件负责“快速地做”。GPU收到一个计算批次后,其数千个核心会并行地执行相同的指令(SIMT架构),但处理批次中不同序列的不同数据。分时(Time-sharing) 的效果,本质上是由调度器快速提交多个小的计算任务到GPU的命令队列(CUDA Stream)中,由GPU硬件高速串行执行而宏观上并发的。GPU计算速度极快(微秒级),这种切换对用户来说就是“同时”。三、技术栈全景图我们可以用一个从高到低的层次来看:总结与类比操作系统(OS) 就像是场地和基础服务提供商:它提供了建筑(内存空间)、电力(CPU调度)、物流通道(网络和PCIe总线)。但它不懂“烹饪AI模型”这个业务。推理框架(如vLLM) 就像是中央厨房的智能管理系统和经理:它设计工作流(调度)、管理食材库存(显存)、为每个订单分配独立的厨具和餐盘(状态隔离),并指挥厨师工作。GPU内核 就像是高度专业化、训练有素的厨师团队:他们严格按照工作指令(内核代码),同时、快速、精准地处理多个订单(批处理)中的不同步骤。因此,您所问的状态隔离和有序调度,其智能和逻辑核心是在“推理框架层”(如vLLM)中实现的。它充分利用了底层操作系统和GPU硬件提供的基础能力,但赋予了它们理解大模型并发推理这一特定业务场景的“智慧”。正是这些专用框架的出现,才使得大模型的高效、高并发服务成为可能。4 推理框架(如vLLM) 是在AI 服务器哪里实现的,操作系统安装某个推理框架(如vLLM) 的应用app 包吗?还是什么调度机制在哪里实现?您可以将推理框架看作是为大模型推理这个特殊任务而专门构建的一个高度特化的“智能操作系统”或“超级后台服务”。它运行在服务器的基础操作系统之上,但管理着GPU这个“第二王国”的一切。下面我为您具体拆解它在哪里、以及如何实现:一、推理框架是什么,安装在哪里?它不是操作系统的一部分,也不是一个简单的“应用商店APP”。像 vLLM, TensorRT-LLM, TGI 这样的推理框架,本质上是一个用Python/C++编写的、复杂的软件项目(或“服务程序”)。您通过服务器的命令行终端,使用Python包管理器(如 pip)或容器技术(如 Docker)将其“安装”到系统中。安装后,它是一系列可执行脚本和库文件,就像您安装了Nginx或MySQL数据库服务一样。它的运行形态:一个长期运行的守护进程当您启动服务时,通常会执行一条类似 python -m vllm.entrypoints.api_server --model=xxx 的命令。这会启动一个持续的进程。这个进程会:加载您指定的大模型权重文件到GPU显存。启动一个HTTP服务器(如FastAPI)监听特定端口(如8000),等待用户请求。初始化其核心的调度器、内存管理器等组件,并常驻内存,7x24小时运行。二、调度机制具体在哪里实现?这是最关键的部分。我们可以分层来看:第1层:用户空间应用层 - “调度决策中心”位置:在vLLM进程的内存空间里,具体是它的 Scheduler 和 Worker 等核心类的Python/C++代码中。功能:这是调度的“大脑”,负责高级决策。请求队列:当HTTP服务器收到用户请求后,将其转化为一个Request对象,放入Python代码中维护的等待队列。调度策略:调度器的代码逻辑(例如,vllm/core/scheduler.py)会周期性地检查队列,根据预设策略(如FCFS先来先服务,或是否优先处理短请求)决定:从等待队列中取出哪些请求。将它们与当前正在生成的请求动态组合成一个新的批处理。决定哪些已完成的请求该移出。内存管理:其PagedAttention内存管理器(同样是vLLM的Python/C++代码)负责为这个新批次中的每个请求分配或查找物理显存块,用于存储KV缓存,确保完全隔离。第2层:计算图与运行时层 - “命令编制部”位置:在PyTorch、CUDA Graphs或框架自有的引擎中。功能:调度器做出“要处理A、B、C用户请求”的决策后,需要将决策转化为GPU能执行的具体计算。框架会为这个特定的批次(包含不同长度、不同内容的请求)动态编译或调用一个预编译的计算图。这个计算图会精确地包含从显存哪个地址读取用户A的KV缓存,哪个地址读取用户B的输入等“低级指令”。第3层:GPU内核与驱动层 - “执行工厂”位置:在GPU上运行的定制化内核(Kernel)代码中。功能:这是调度的“肌肉”,负责最终执行。计算图最终会调用一系列高度优化的GPU内核函数(例如用CUDA C++编写的FlashAttention内核)。这些内核被设计为支持批处理:它们内部有逻辑,能根据一个“序列ID”或偏移量参数,在同一时间内,但为批次中不同的序列进行正确的计算。内核代码保证了计算在数学上的正确性和隔离性。分时的实现:当调度器快速连续地提交多个小批次任务到GPU的命令队列时,GPU硬件会以极高的速度串行执行它们,宏观上实现了并行。这是由NVIDIA驱动和GPU硬件调度器在纳秒/微秒级别完成的。三、一个简化的运行流程图用户请求 -> 网络 -> 服务器端口 ↓[vLLM 进程 - 常驻内存] ↓HTTP服务器接收请求(FastAPI代码) ↓放入内部等待队列(Python列表/队列对象) ↓核心调度器(Scheduler类)被触发决策:将请求A、B、C组成一个新批管理:为A、B、C分配独立的KV缓存页 ↓构建计算图(调用PyTorch/CUDA)输入:批数据 + A/B/C的KV缓存地址 ↓启动GPU内核执行GPU内核:并行计算,但数据各安其位 ↓获取结果,返回给对应HTTP连接四、重要总结:为什么不是操作系统内核?职责不同:操作系统内核(如Linux Kernel)的通用调度器,调度的是进程和线程这种通用计算单元。它对“大模型推理”、“KV缓存”、“自回归生成”这些领域特定知识一无所知。效率与灵活性:在用户空间实现的调度器(如vLLM的),可以用Python/C++快速实现复杂的、针对LLM优化的调度策略(如连续批处理、内存换入换出),并随时调整,无需修改操作系统内核。访问硬件:推理框架通过CUDA驱动API这个“特权通道”直接与GPU对话,绕过了操作系统对计算细节的管理,实现了极致性能。所以,答案是: 推理框架(如vLLM)是安装并运行在操作系统之上的一个独立的、专门化的后台服务进程。它最核心的调度机制,是在这个进程内部,由其自身用高级语言(Python/C++)实现的逻辑代码来完成的。 它就像是在通用操作系统之上,为AI计算这个特定领域建立的一个“自治王国”,拥有自己的法律(调度策略)、资源管理方式(显存分页)和军队(GPU内核)。5 一个AI服务器的一个大模型其实在同一时刻其实只有一个人使用是吗? 多个用户是按照时间片划分看起来在同时使用,如果使用用户过多,调度不过来,就需要排队?它不是纯粹的时间片轮转,而是两者的结合:既有真正的物理并行,也有时间上的交错。核心答案:既是“并行”,也是“交错”,排队是必然的“同一时刻只有一个人使用”是错误的现代GPU(如H100)拥有成千上万个核心,其设计初衷就是为了并行计算。推理框架通过批处理技术,会将多个用户的请求数据(输入的Token、各自的KV缓存)物理上打包成一个批次,一次性送入GPU。在这个批次的前向传播计算过程中,GPU的硬件是同时在为所有请求进行计算。例如,计算注意力分数时,矩阵运算会并行处理批次中的所有序列。所以,在计算微观层面,GPU确实在同一时刻为多个用户工作。“时间片划分”体现在哪里?关键在于自回归生成的过程。模型生成文本是一个“猜下一个词”的循环过程:第一步(预填充):并行处理整个批次中所有用户的输入提示(Prompt)。这是高度并行的。第二步(生成):为每个用户逐个生成输出Token。这个过程是交错并行的:调度器会执行一次前向传播,为批次中的所有活跃请求各生成一个Token。然后,将已生成完毕的请求移出批次,加入新的请求,再执行下一次前向传播。从每个用户的感受上看,他们是轮流收到下一个词的(例如用户A收到第1个词,用户B收到第3个词),宏观上像是“时间片”。但从GPU的视角看,每一次前向传播都是同时在为多个请求工作。“调度不过来,就需要排队”是完全正确的这发生在两个层面:进入运行队列前的排队:当新请求到达速率超过调度器能将其加入运行批次的速度时,请求会在等待队列中排队。KV缓存容量导致的排队:这是更根本的限制。GPU显存中能同时保存的“活跃请求”的KV缓存总数是有限的(如之前计算的,可能只有几十个)。一旦超过这个数,新请求就必须在等待队列中排队,直到有活跃请求完成、释放出其KV缓存空间后,才能被调度进来。一个更精确的比喻:中央厨房的炒菜流程延续之前的比喻:批处理(并行):厨师(GPU)同时将10份订单(一个批次)的牛排放进同一个大火炉(并行计算)烹煮。这是物理上的同时处理。交错生成(时间交错):每份牛排需要煎5分钟。厨师不是等一份煎完再煎下一份,而是同时开煎。但出锅时,由于订单要求不同(有的要5分熟,有的要7分熟),牛排会按各自的时间线依次出锅(对应每个请求流式输出Token)。排队:如果瞬间来了100份订单,厨房最多只能同时处理10份。另外90份就在订单接收区(等待队列)排队。只有当前面10份中的某份完成出锅、腾出了炉位,排队中的订单才能进入烹饪区。总结所以,实际情况是:GPU计算是并行的:硬件在同一时刻处理多个请求的数据。生成输出是交错并行的:每个请求按自己的序列逐个获得Token,宏观上像是轮流服务。排队不可避免:由于硬件资源(显存、算力)有限,当并发需求超过系统吞吐量或KV缓存容量上限时,排队必然发生。这正是为什么我们需要评估系统“最大支持用户数”的原因——这个数字本质上就是在可接受延迟下,系统能处理的平均请求速率。因此,您可以说“多个用户是共享同一个模型的计算资源”,但不是简单的单核CPU时间片轮转,而是更高效的、并行与交错相结合的高级调度。排队是系统保护自身、保证服务质量的自然机制。5 那就是GPU 在设计之初就支持多进程同时计算,这些进程的数据互补干扰,是这样吗?这是一个非常关键的问题。您的理解方向是正确的,但需要更精确地澄清“进程”和“干扰”的含义。GPU的并行能力:硬件基础GPU在设计之初的核心思想就是大规模并行计算。它拥有数千甚至上万个小而高效的计算核心(CUDA Core/Tensor Core),这些核心被组织成多个流多处理器(SM)。其架构擅长执行 “单指令,多线程” 的任务,即让大量核心同时执行相同的操作,但处理不同的数据。多进程与数据隔离:软件实现GPU硬件本身并不理解“进程”这个概念。数据隔离和不干扰是由软件栈(驱动、运行时、框架) 在硬件提供的并行能力之上实现的。多进程同时使用GPU:是的操作系统可以启动多个应用程序进程,每个进程都可以通过CUDA驱动向GPU提交计算任务。GPU硬件和驱动有能力快速切换、交错执行来自不同进程的计算任务(通过CUDA Stream等机制)。宏观上,多个进程“同时”在使用GPU。数据互不干扰:需要软件精心管理GPU本身不保证隔离:如果两个进程的程序错误地访问了相同的显存地址,数据就会互相干扰、覆盖。隔离是由软件层保障的:CUDA驱动/运行时:它为每个进程(或上下文)提供虚拟化的显存地址空间和管理,类似于操作系统为进程管理内存。这奠定了隔离的基础。推理框架(如vLLM):这是实现业务逻辑层面隔离的关键。它在上述基础之上,更进一步:会为每个用户请求精确分配独立的显存区域来存储其独有的KV缓存和中间数据。在启动GPU计算内核时,会传入精确的参数,告诉内核“请求A的数据在地址X,请求B的数据在地址Y”。内核代码则根据这些参数,确保在并行计算过程中,核心们处理的是各自正确的数据块,不会交叉混淆。一个技术层面的类比GPU硬件 像一个巨大的印刷厂,有成千上万个相同的印刷机(核心)。CUDA驱动 像印刷厂的调度员,可以接收来自多个客户(进程)的订单,并安排印刷机工作。推理框架 则像一个超级客户,它有一个大订单(运行大模型)。但它内部又把这个大订单拆分成无数个子订单(用户请求),并为每个子订单指定了专用的纸张和油墨(显存空间)。它告诉调度员:“请用印刷机同时印刷子订单A和B,但A用左边仓库的纸,B用右边仓库的纸。”印刷机(GPU核心)虽然同时运转,但因为拿的纸张和油墨来源不同,最终产品不会混淆。结论所以,答案是: 是的,GPU硬件设计支持并行计算,允许多个进程或任务同时利用其核心。但“数据互不干扰”并非由GPU自动保证,而是通过CUDA软件栈和上层推理框架(如vLLM)的精细内存管理和调度逻辑来实现的。 硬件提供了并行执行的“肌肉”,软件则提供了正确组织工作、避免混乱的“大脑”。因此,在您提到的AI服务器场景中,多个用户同时使用不会造成计算混乱,正是得益于这套从硬件底层到软件顶层的完整协作体系。 -
C语言枚举end是做什么用的? 最近在知乎上看到一个问题:C语言枚举end是做什么用的?刚开始,我也有一些疑惑,后面查了一些资料,对于这个问题,简单地说一下我的看法。枚举有多大?枚举类型到底有多大,占多少空间呢?这个要具体情况具体分析,编译器会视情况而定。下面是我测试用的编译器版本:gcc (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0Copyright (C) 2017 Free Software Foundation, Inc.This is free software; see the source for copying conditions. There is NOwarranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.当我写下这段代码的时候,实际的输出会是多少呢?有人会说是 1,有人会说是 4,我最终运行的确实是4;▲输出结果但是,这个结果并不是唯一的,它取决于你的编译器,另外还取决于编译器参数,gcc这里有个编译器参数 -fshort-enums,如果我们在编译的时候加上这个,那么编译出来是什么呢?▲短枚举的输出结果最终结果变成了1现在我在原先的代码中,加入CMD_MAX_16BIT = 0xFFFF,下面看看输出结果是多少。▲增带值范围运行输出结果如下:▲输出结果是的,它变成了2。因此,我们可以得出结论就是:编译器将为枚举分配足够的内存大小,来保存我们所声明的任何值。所以,如果我们的代码中只使用低于 256(8位的范围是0~255) 的值,我们的枚举应该是 8 位宽,也就是一个字节,而后面的0xFFFF显然是16位,两个字节,所以最终输出为2为此,我参考了一下gcc user manual,如下;https ://gcc.gnu.org/onlinedocs/gcc/Code-Gen-Options.html-fshort-enumsAllocate to an enum type only as many bytes as it needs for the declared range of possible values. Specifically, the enum type is equivalent to the smallest integer type that has enough room.Warning: the -fshort-enums switch causes GCC to generate code that is not binary compatible with code generated without that switch. Use it to conform to a non-default application binary interface.所以,我们需要明确的是编译器是否会默认执行 -fshort-enums这个命令,大多数是不会的,这里我还测试了一些clang,具体结果和gcc相同。但是,在嵌入式编程中需要注意,这里我查了一下,IAR的编译器默认会执行 -fshort-enums 。电脑上没有IAR,这里我参考了IAR 的 ARM C 编译器的文档IAR C/C++ Development Guide。可以看到enum类型默认的规定,如果要强制为int类型的话,需要编译的时候提那就--enum_is_int的编译参数,如下所示:▲枚举类型所以,这里为了避免编译器的优化,以及不同的硬件平台和不同编译器,从而导致枚举分配内存空间的变化,所以上述增加了一个0xFFFFFFFF,强制编译器为枚举分配4个字节的空间。▲设置最大范围为4字节最终的输出结果都是4,如下图所示:▲输出结果比较看来虽然是一个很小的知识点,但这中间的坑还真不少!好了,本期的文章就到这里了,我们下期再见。
-
MMU那些事儿 EET0P2020年12月27日03:47MMU 诞生之前:在传统的批处理系统如 DOS 系统,应用程序与操作系统在内存中的布局大致如下图:应用程序直接访问物理内存,操作系统占用一部分内存区。操作系统的职责是“加载”应用程序,“运行”或“卸载”应用程序。如果我们一直是单任务处理,则不会有任何问题,也或者应用程序所需的内存总是非常小,则这种架构是不会有任何问题的。然而随着计算机科学技术的发展,所需解决的问题越来越复杂,单任务批处理已不能满足需求了。而且应用程序需要的内存量也越来越大。而且伴随着多任务同时处理的需求,这种技术架构已然不能满足需求了,早先的多任务处理系统是怎么运作的呢?程序员将应用程序分段加载执行,但是分段是一个苦力活。而且死板枯燥。此时聪明的计算机科学家想到了好办法,提出来虚拟内存的思想。程序所需的内存可以远超物理内存的大小,将当前需要执行的留在内存中,而不需要执行的部分留在磁盘中,这样同时就可以满足多应用程序同时驻留内存能并发执行了。从总体上而言,需要实现哪些大的策略呢?所有的应用程序能同时驻留内存,并由操作系统调度并发执行。需要提供机制管理 I/O 重叠,CPU 资源竞争访问。虚实内存映射及交换管理,可以将真实的物理内存,有可变或固定的分区,分页或者分段与虚拟内存建立交换映射关系,并且有效的管理这种映射,实现交换管理。这样,衍生而来的一些实现上的更具体的需求:竞争访问保护管理需求:需要严格的访问保护,动态管理哪些内存页/段或区,为哪些应用程序所用。这属于资源的竞争访问管理需求。高效的翻译转换管理需求:需要实现快速高效的映射翻译转换,否则系统的运行效率将会低下。高效的虚实内存交换需求:需要在实际的虚拟内存与物理内存进行内存页/段交换过程中快速高效。总之,在这样的背景下,MMU 应运而生,也由此可见,任何一项技术的发展壮大,都必然是需求驱动的。这是技术本身发展的客观规律。内存管理的好处为编程提供方便统一的内存空间抽象,在应用开发而言,好似都完全拥有各自独立的用户内存空间的访问权限,这样隐藏了底层实现细节,提供了统一可移植用户抽象。 以最小的开销换取性能最大化,利用 MMU 管理内存肯定不如直接对内存进行访问效率高,为什么需要用这样的机制进行内存管理,是因为并发进程每个进程都拥有完整且相互独立的内存空间。那么实际上内存是昂贵的,即使内存成本远比从前便宜,但是应用进程对内存的寻求仍然无法在实际硬件中,设计足够大的内存实现直接访问,即使能满足,CPU 利用地址总线直接寻址空间也是有限的。内存管理实现总体策略从操作系统角度来看,虚拟内存的基本抽象由操作系统实现完成:处理器内存空间不必与真实的所连接的物理内存空间一致。 当应用程序请求访问内存时,操作系统将虚拟内存地址翻译成物理内存地址,然后完成访问。 从应用程序角度来看,应用程序(往往是进程)所使用的地址是虚拟内存地址,从概念上就如下示意图所示,MMU 在操作系统的控制下负责将虚拟内存实际翻译成物理内存。从而这样的机制,虚拟内存使得应用程序不用将其全部内容都一次性驻留在内存中执行: 节省内存:很多应用程序都不必让其全部内容一次性加载驻留在内存中,那么这样的好处是显而易见,即使硬件系统配置多大的内存,内存在系统中仍然是最为珍贵的资源。所以这种技术节省内存的好处是显而易见的。 使得应用程序以及操作系统更具灵活性。操作系统根据应用程序的动态运行时行为灵活的分配内存给应用程序。使得应用程序可以使用比实际物理内存多或少的内存空间。MMU 以及 TLBMMU(Memory Management Unit)内存管理单元:一种硬件电路单元负责将虚拟内存地址转换为物理内存地址所有的内存访问都将通过 MMU 进行转换,除非没有使能 MMU。TLB(Translation Lookaside Buffer)转译后备缓冲器: 本质上是 MMU 用于虚拟地址到物理地址转换表的缓存这样一种架构,其最终运行时目的,是为主要满足下面这样运行需求:多进程并发同时并发运行在实际物理内存空间中,而 MMU 充当了一个至关重要的虚拟内存到物理内存的桥梁作用。那么,这种框架具体从高层级的概念上是怎么做到的呢?事实上,是将物理内存采用分片管理的策略来实现的,那么,从实现的角度将有两种可选的策略:固定大小分区机制可变大小分区机制固定大小区片机制通过这样一种概念上的策略,将物理内存分成固定等大小的片: 每一个片提供一个基地址 实际寻址,物理地址=某片基址+虚拟地址 片基址由操作系统在进程动态运行时动态加载这种策略实现,其优势在于简易,切换快速。但是该策略也带来明显的劣势: 内部碎片:一个进程不使用的分区中的内存对其他进程而言无法使用 一种分区大小并不能满足所有应用进程所需。可变大小分区机制内存被划分为可变大小的区块进行映射交换管理: 需要提供基址以及可变大小边界,可变大小边界用于越界保护。实 际寻址,物理地址=某片基址+虚拟地址那么这种策略其优势在于没有内部内存碎片,分配刚好够进程所需的大小。但是劣势在于,在加载和卸载的动态过程中会产生碎片。分页机制分页机制采用在虚拟内存空间以及物理内存空间都使用固定大小的分区进行映射管理。从应用程序(进程)角度看内存是连续的 0-N 的分页的虚拟地址空间。物理内存角度看,内存页是分散在整个物理存储中这种映射关系对应用程序不可见,隐藏了实现细节。分页机制是如何寻址的呢?这里介绍的设计理念,具体的处理器实现各有细微差异:虚拟地址包含了两个部分:虚拟页序号 VPN(virtual paging number)以及偏移量虚拟页序号 VPN是页表(Page Table)的索引页表(Page Table)维护了页框号(Page frame number PFN)物理地址由PFN::Offset进行解析。举个栗子,如下图所示:还没有查到具体的物理地址,憋急,再看一下完整解析示例:如何管理页表对于 32 位地址空间而言,假定 4K 为分页大小,则页表的大小为 100MB,这对于页表的查询而言是一个很大的开销。那么如何减小这种开销呢?实际运行过程中发现,事实上只需要映射实际使用的很小一部分地址空间。那么在一级页机制基础上,延伸出多级页表机制。 以二级分页机制为例:单级页表已然有不小的开销,查询页表以及取数,而二级分页机制,因为需要查询两次页表,则将这种开销再加一倍。那么如何提高效率呢?其实前面提到一个概念一直还没有深入描述 TLB,将翻译工作由硬件缓存 cache,这就是 TLB 存在的意义。 TLB 将虚拟页翻译成 PTE,这个工作可在单周期指令完成。TLB 由硬件实现完全关联缓存(并行查找所有条目)缓存索引是虚拟页码缓存内容是 PTE则由 PTE+offset,可直接计算出物理地址TLB 加载谁负责加载 TLB 呢?这里可供选择的有两种策略:由操作系统加载,操作系统找到对应的 PTE,而后加载到 TLB。格式比较灵活。MMU 硬件负责,由操作系统维护页表,MMU 直接访问页表,页表格式严格依赖硬件设计格式。总结一下从计算机大致发展历程来了解内存管理的大致发展策略,如何衍生出 MMU,以及固定分片管理、可变分片管理等不同机制的差异,最后衍生出单级分页管理机制、多级分页管理机制、TLB 的作用。从概念上相对比较易懂的角度描述了 MMU 的诞生、机制,而忽略了处理器的具体实现细节。作为从概念上更深入的理解 MMU 的工作机理的角度,还是不失为一篇浅显易懂的文章。
-
Python 必杀技:用 print() 函数实现的三个特效 print() 应该是初学者最先接触到的第一个 Python 函数,因为几乎所有的启蒙课程都是从 print('Hello world') 开始的。事实上, print() 也是程序员使用频率最高的函数之一,同时也是很多程序员喜欢的代码调试利器。但是关于 print() 函数,你真的了解吗?打字机效果不了解 print() 的 flush 参数,很难实现下图所示的打字机效果:动图封面print() 像个调皮的小朋友,你让他帮你打印,他一定会做,但未必是立即去做,也许会攒够了多个打印任务才执行一次。设置 flush=True,可以让这位小朋友立刻去执行命令。 import time def printer(text, delay=0.2): """打字机效果""" for ch in text: print(ch, end='', flush=True) time.sleep(delay) printer('玄铁重剑,是金庸小说笔下第一神剑,持之则无敌于天下。')旋转式进度指示Linux 系统文本界面下,最常用的进度指示是用横竖斜杠构成的旋转图案。动图封面Python也可以轻松实现这个效果,秘诀就在于 '\b' 字符。 '\b' 相当于键盘上的退格键,可以让我们把刚刚打印过的最后一个字符擦掉重新打印。这个效果,同样需要设置参数 flush 为真。 import time def waiting(cycle=20, delay=0.1): """旋转式进度指示""" for i in range(cycle): for ch in ['-', '\\', '|', '/']: print('\b%s'%ch, end='', flush=True) time.sleep(delay) waiting() 反转字符顺序,就可以改变旋转方向。将第一个字符 '-' 改成 '-- ',还可以实现这样的效果:动图封面覆盖式打印效果'\b' 的作用是回退一个字符,'\r' 则可以退回到行首。借助于 '\r',可以实现整行覆盖式的打印效果:动图封面需要注意的是,整行覆盖的话,新的字符串长度不能小于原字符串长度,否则会留下前一次的打印内容。这个效果,同样需要设置参数 flush 为真。 import time def cover(cycle=100, delay=0.2): """覆盖式打印效果""" for i in range(cycle): s = '\r%d'%i print(s.ljust(3), end='', flush=True) time.sleep(delay) cover()
-
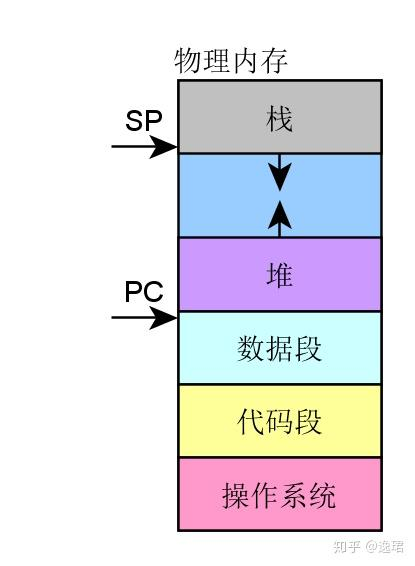
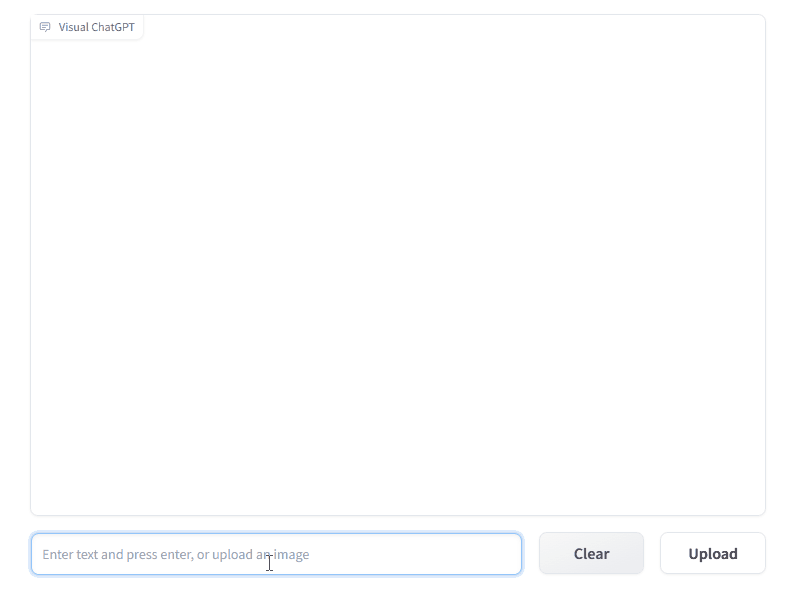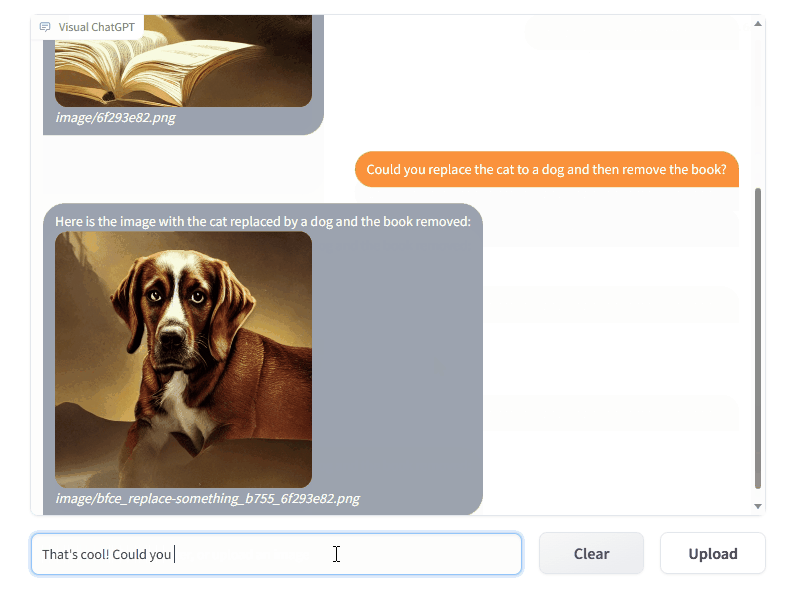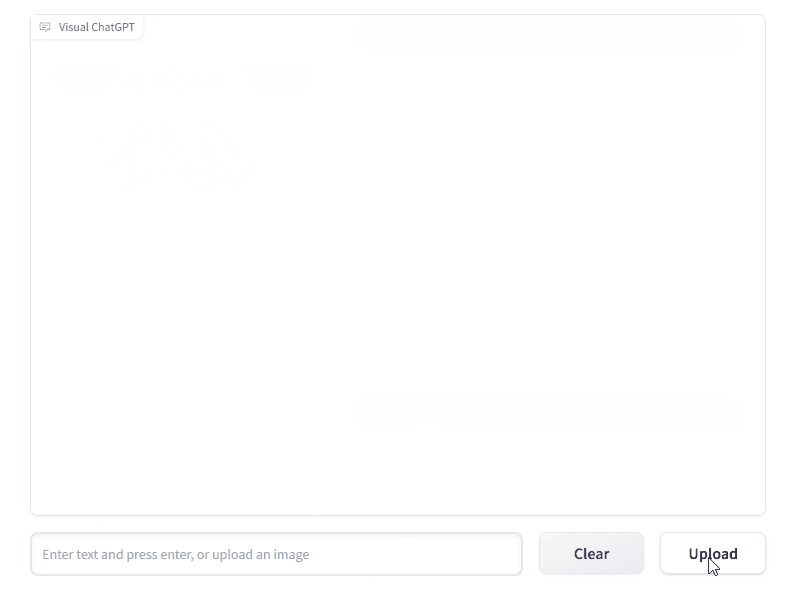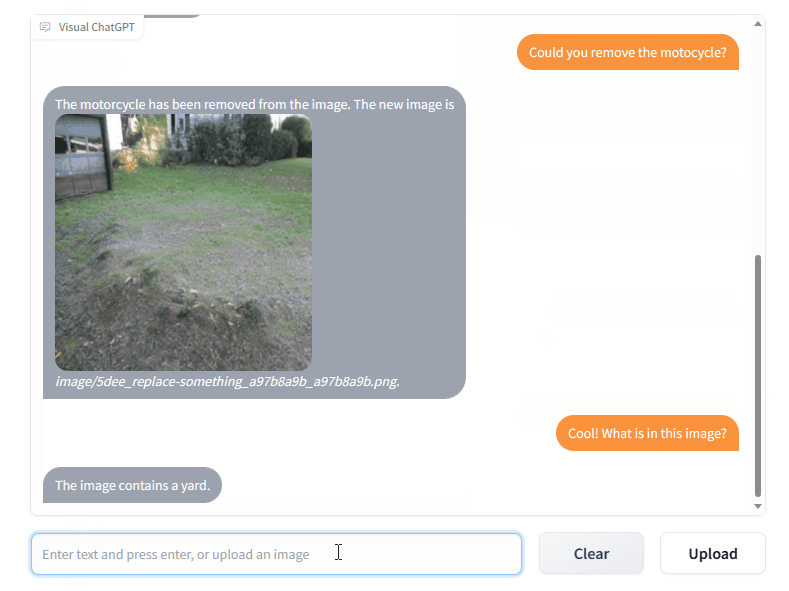
4个令人惊艳的ChatGPT项目,开源了! 1T服务圈儿2023年04月18日17:32江苏来源丨经授权转自 Jack Cui(ID:JackCui-AI)作者丨Jack Cui自从 ChatGPT、Stable Diffusion 发布以来,各种相关开源项目百花齐放,着实让人应接不暇。今天,我将着重挑选几个优质的开源项目,对我们的日常工作、学习生活,都会有很大的帮助。今天整理分享给大家,希望对你有所帮助。一、Visual ChatGPT这个是微软开源的项目,一周多的时间,就斩获了 23.6k+ star。简单概括它,那就是一个多模态的问答系统。支持AI绘画、语言问答、看图问答,将 AI 届近期的 3 大热点集于一身。效果展示:系统实现框架如下:Visual ChatGPT的系统实现框架这是一个“大力出奇迹”的开源项目,集多方研究成果于一身:BLIP、CLIP、ChatGPT、pix2pix、inpainting、vqa 等。说白了,就是教你怎样使用这些项目,搭建一个多模态的问答系统,这个系统架构很有参考价值。项目地址:https://github.com/microsoft/visual-chatgpt二、SadTalker这是一篇 2023 年的 CVPR 论文对应的开源项目。刚刚开源,新鲜热乎~功能就是:根据一张图片、一段音频,合成面部说这段语音的视频。结合 ChatGPT、AIGC、音频文字转换,虚拟二次元 or 三次元形象,就能“活”过来了。此外,还项目还做成了 stable diffusion webui 的插件,也就是直接能在 stable diffusion 里使用。生成的图片,直接配合一段音频,就能生成合成的视频。项目地址:https://github.com/winfredy/sadtalker三、FateZero文本能编辑生成图片?那视频能编辑吗?FateZero:我可以!左图是原图,右图是生成效果,输入的文本是:增加 Pokémon 动漫风格除了视频的风格迁移,也支持修改里面的内容。比如:松鼠是胡萝卜,变成,兔子吃茄子。这个项目也是基于sd做的,离一键生成视频,又进了一步。项目地址:https://github.com/chenyangqiqi/fatezero四、ChatPaperarXiv 想必大家都知道,当下最流行的论文托管网站,上面有来自世界各地的科学家、研究学者。为了提高 arXiv 用户阅读论文的效率,有人开源了一款利用 ChatGPT 总结 arXiv 论文的开源工具 ChatPaper。简而言之,该项目可根据用户关键词下载 arXiv 上的最新论文,利用 ChatGPT3.5 API 强大的归纳能力,将其浓缩成固定格式,文字少且易读。同时,项目支持个人自己部署,或者直接去 Hugge Face 体验。项目地址:https://github.com/kaixindelele/ChatPaperhttps://huggingface.co/spaces/wangrongsheng/ChatPaper来自微信