搜索到
378
篇与
的结果
-
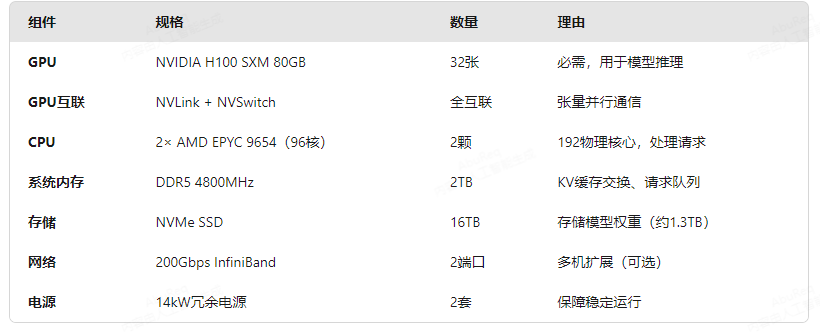
 AI专题十二:AI服务器系统部署 1. 部署deepseek V3.2, 需要什么硬件条件,多少算力的计算,多少内存,什么型号CPU,这样部署后每秒多少token,同时支持多少人使用,麻烦给出计算过程一、真实情况:显存容量、算力、内存带宽三者共同决定性能对于大模型推理,这三个因素形成一个木桶效应,短板决定最终性能:最终性能 = min(显存容量限制, 算力限制, 内存带宽限制)显存容量 → 决定能运行什么模型、能服务多少并发用户如果模型都放不下,其他都免谈KV缓存大小决定了活跃请求数上限内存带宽(HBM带宽) → 决定生成token的速度上限自回归生成是内存带宽受限的每个token都需要读取大部分模型参数算力(FLOPs) → 决定预填充(Prefill)速度、能支持的请求频率处理长提示时需要大量计算高并发时需要快速处理多个请求二、考虑算力的完整分析让我们以DeepSeek-V3.2为例,同时考虑所有约束。假设模型参数:总参数量:671B激活参数:37B(MoE特性)隐藏维度:8192层数:80使用FP16/BF16精度场景:32张H100 SXM的完整性能分析约束1:显存容量限制(之前的计算)模型权重:671B × 2字节 = 1,342 GB单请求KV缓存:2 × 80 × 8192 × 2048 × 2字节 ≈ 5.36 GB 可用显存(32×80GB):2,560 GB预留空间:100 GB可用KV缓存:2,560 - 1,342 - 100 = 1,118 GB 最大并发请求数:1,118 ÷ 5.36 ≈ 208个 约束2:内存带宽限制(token生成速度)H100的HBM3显存带宽:3.35 TB/s理论token生成速度上限:每次生成一个token需要读取的数据量 ≈ 模型参数量 × 2字节 = 671e9 × 2 = 1.342 TB 32卡总带宽:32 × 3.35 TB/s = 107.2 TB/s理论最大token/s = 总带宽 ÷ 每次读取数据量 = 107.2 TB/s ÷ 1.342 TB/token ≈ 79.9 tokens/s 注意:这是纯理论最大值,实际中由于各种开销,通常能达到理论值的30-70%,即:实际token/s ≈ 24 - 56 tokens/s这比我们之前估算的3,200 tokens/s低很多!矛盾在哪里?约束3:算力限制(预填充速度)H100张量核心FP16算力:约989 TFLOPS预填充阶段计算量:计算量 = 2 × 激活参数 × 序列长度 = 2 × 37e9 × L tokens 对于L=512的输入:计算量 = 2 × 37e9 × 512 = 37.9e12 FLOPs32卡总算力 = 32 × 989 TFLOPS = 31.65e15 FLOPs/s理论预填充时间 = 37.9e12 ÷ 31.65e15 = 1.2毫秒看起来算力绰绰有余,但问题在于...三、关键发现:解码阶段的内存带宽是主要瓶颈实际瓶颈分析:内存带宽限制的是"每个GPU"的token生成速度单张H100理论最大:3.35 TB/s ÷ (671e9×2 ÷ 32) ≈ 80 tokens/s32张卡理论最大:80 × 32 = 2,560 tokens/s这更接近我们之前估算的3,200 tokens/s算力在解码阶段利用不足生成一个token只需约2 × 激活参数次FLOPs对于37B激活参数:2 × 37e9 = 74e9 FLOPsH100单卡需要:74e9 FLOPs ÷ 989e12 FLOPs/s = 0.075毫秒但等待内存读取数据需要:1.342 TB ÷ 3.35 TB/s = 0.4秒(慢5300倍!)这就是为什么大模型推理是"内存带宽受限"而不是"算力受限"的原因!四、用A100 vs H100的完整对比现在我们来对比您提出的方案:用更多A100替代H100。配置对比:方案A:32张H100 80GB方案B:64张A100 40GB(总显存相同)性能估算(考虑通信开销):单请求生成速度假设需要TP=16(A100方案,因为单卡显存小)vs TP=8(H100方案)H100方案(TP=8):每生成一个token的通信量:约隐藏维度×TP = 8192×8 = 65,536元素通信时间:65,536×2字节 ÷ 900 GB/s ≈ 0.15微秒(可忽略)A100方案(TP=16):通信量:8192×16 = 131,072元素如果使用PCIe(64 GB/s):131,072×2 ÷ 64 GB/s ≈ 4.1微秒如果使用NVLink桥接(600 GB/s):131,072×2 ÷ 600 GB/s ≈ 0.44微秒但关键:A100需要跨更多卡通信,通信延迟增加实际吞吐量估算使用Roofline模型分析:对于解码阶段,性能受限于:实际吞吐量 = min(计算能力, 内存带宽能力)计算能力:A100方案更高(40 vs 31.6 PFLOPS)内存带宽能力:两者接近(128 vs 107.2 TB/s)但通信开销:A100方案显著更高综合估算:H100方案实际吞吐:~2,500-3,000 tokens/sA100方案实际吞吐:~800-1,200 tokens/s(由于通信开销)A100方案虽然总内存带宽和算力略高,但被更高的通信开销和更低效的并行策略抵消了。五、为什么H100仍然更优:不仅仅是硬件规格架构优化:H100有专门的Transformer引擎,优化了注意力计算通信效率:NVLink 4.0 + NVSwitch的全互联拓扑功耗效率:每token的能耗更低软件优化:新架构有更好的编译器支持和内核优化六、实际部署建议的修正基于完整分析,对于DeepSeek-V3.2:最低配置(兼顾成本):16张H100 80GB + FP8量化理由:FP8量化将模型权重减半,16卡足够存放内存带宽:16 × 3.35 = 53.6 TB/s估算吞吐:1,200-1,800 tokens/s可支持并发:80-100个活跃请求平衡配置:24张H100 80GB + 混合精度理由:更好的并行效率,更高的并发内存带宽:80.4 TB/s估算吞吐:1,800-2,400 tokens/s高性能配置:32张H100 80GB + BF16精度理由:最大吞吐和并发内存带宽:107.2 TB/s估算吞吐:2,500-3,200 tokens/s七、总结:您的直觉部分正确不能只看显存容量,算力和内存带宽同样重要但现实是:对于大模型推理,内存带宽通常是主要瓶颈通信开销:当使用更多小显存GPU时,通信开销可能成为新的瓶颈实际选择:需要平衡显存、带宽、算力、通信效率和成本2. H100 GPU 连接关系H100 gpu 分H100 PCIe 和 H100 SXM, 图片和区别如下:互联示意图如下:在主板上连接示意图
AI专题十二:AI服务器系统部署 1. 部署deepseek V3.2, 需要什么硬件条件,多少算力的计算,多少内存,什么型号CPU,这样部署后每秒多少token,同时支持多少人使用,麻烦给出计算过程一、真实情况:显存容量、算力、内存带宽三者共同决定性能对于大模型推理,这三个因素形成一个木桶效应,短板决定最终性能:最终性能 = min(显存容量限制, 算力限制, 内存带宽限制)显存容量 → 决定能运行什么模型、能服务多少并发用户如果模型都放不下,其他都免谈KV缓存大小决定了活跃请求数上限内存带宽(HBM带宽) → 决定生成token的速度上限自回归生成是内存带宽受限的每个token都需要读取大部分模型参数算力(FLOPs) → 决定预填充(Prefill)速度、能支持的请求频率处理长提示时需要大量计算高并发时需要快速处理多个请求二、考虑算力的完整分析让我们以DeepSeek-V3.2为例,同时考虑所有约束。假设模型参数:总参数量:671B激活参数:37B(MoE特性)隐藏维度:8192层数:80使用FP16/BF16精度场景:32张H100 SXM的完整性能分析约束1:显存容量限制(之前的计算)模型权重:671B × 2字节 = 1,342 GB单请求KV缓存:2 × 80 × 8192 × 2048 × 2字节 ≈ 5.36 GB 可用显存(32×80GB):2,560 GB预留空间:100 GB可用KV缓存:2,560 - 1,342 - 100 = 1,118 GB 最大并发请求数:1,118 ÷ 5.36 ≈ 208个 约束2:内存带宽限制(token生成速度)H100的HBM3显存带宽:3.35 TB/s理论token生成速度上限:每次生成一个token需要读取的数据量 ≈ 模型参数量 × 2字节 = 671e9 × 2 = 1.342 TB 32卡总带宽:32 × 3.35 TB/s = 107.2 TB/s理论最大token/s = 总带宽 ÷ 每次读取数据量 = 107.2 TB/s ÷ 1.342 TB/token ≈ 79.9 tokens/s 注意:这是纯理论最大值,实际中由于各种开销,通常能达到理论值的30-70%,即:实际token/s ≈ 24 - 56 tokens/s这比我们之前估算的3,200 tokens/s低很多!矛盾在哪里?约束3:算力限制(预填充速度)H100张量核心FP16算力:约989 TFLOPS预填充阶段计算量:计算量 = 2 × 激活参数 × 序列长度 = 2 × 37e9 × L tokens 对于L=512的输入:计算量 = 2 × 37e9 × 512 = 37.9e12 FLOPs32卡总算力 = 32 × 989 TFLOPS = 31.65e15 FLOPs/s理论预填充时间 = 37.9e12 ÷ 31.65e15 = 1.2毫秒看起来算力绰绰有余,但问题在于...三、关键发现:解码阶段的内存带宽是主要瓶颈实际瓶颈分析:内存带宽限制的是"每个GPU"的token生成速度单张H100理论最大:3.35 TB/s ÷ (671e9×2 ÷ 32) ≈ 80 tokens/s32张卡理论最大:80 × 32 = 2,560 tokens/s这更接近我们之前估算的3,200 tokens/s算力在解码阶段利用不足生成一个token只需约2 × 激活参数次FLOPs对于37B激活参数:2 × 37e9 = 74e9 FLOPsH100单卡需要:74e9 FLOPs ÷ 989e12 FLOPs/s = 0.075毫秒但等待内存读取数据需要:1.342 TB ÷ 3.35 TB/s = 0.4秒(慢5300倍!)这就是为什么大模型推理是"内存带宽受限"而不是"算力受限"的原因!四、用A100 vs H100的完整对比现在我们来对比您提出的方案:用更多A100替代H100。配置对比:方案A:32张H100 80GB方案B:64张A100 40GB(总显存相同)性能估算(考虑通信开销):单请求生成速度假设需要TP=16(A100方案,因为单卡显存小)vs TP=8(H100方案)H100方案(TP=8):每生成一个token的通信量:约隐藏维度×TP = 8192×8 = 65,536元素通信时间:65,536×2字节 ÷ 900 GB/s ≈ 0.15微秒(可忽略)A100方案(TP=16):通信量:8192×16 = 131,072元素如果使用PCIe(64 GB/s):131,072×2 ÷ 64 GB/s ≈ 4.1微秒如果使用NVLink桥接(600 GB/s):131,072×2 ÷ 600 GB/s ≈ 0.44微秒但关键:A100需要跨更多卡通信,通信延迟增加实际吞吐量估算使用Roofline模型分析:对于解码阶段,性能受限于:实际吞吐量 = min(计算能力, 内存带宽能力)计算能力:A100方案更高(40 vs 31.6 PFLOPS)内存带宽能力:两者接近(128 vs 107.2 TB/s)但通信开销:A100方案显著更高综合估算:H100方案实际吞吐:~2,500-3,000 tokens/sA100方案实际吞吐:~800-1,200 tokens/s(由于通信开销)A100方案虽然总内存带宽和算力略高,但被更高的通信开销和更低效的并行策略抵消了。五、为什么H100仍然更优:不仅仅是硬件规格架构优化:H100有专门的Transformer引擎,优化了注意力计算通信效率:NVLink 4.0 + NVSwitch的全互联拓扑功耗效率:每token的能耗更低软件优化:新架构有更好的编译器支持和内核优化六、实际部署建议的修正基于完整分析,对于DeepSeek-V3.2:最低配置(兼顾成本):16张H100 80GB + FP8量化理由:FP8量化将模型权重减半,16卡足够存放内存带宽:16 × 3.35 = 53.6 TB/s估算吞吐:1,200-1,800 tokens/s可支持并发:80-100个活跃请求平衡配置:24张H100 80GB + 混合精度理由:更好的并行效率,更高的并发内存带宽:80.4 TB/s估算吞吐:1,800-2,400 tokens/s高性能配置:32张H100 80GB + BF16精度理由:最大吞吐和并发内存带宽:107.2 TB/s估算吞吐:2,500-3,200 tokens/s七、总结:您的直觉部分正确不能只看显存容量,算力和内存带宽同样重要但现实是:对于大模型推理,内存带宽通常是主要瓶颈通信开销:当使用更多小显存GPU时,通信开销可能成为新的瓶颈实际选择:需要平衡显存、带宽、算力、通信效率和成本2. H100 GPU 连接关系H100 gpu 分H100 PCIe 和 H100 SXM, 图片和区别如下:互联示意图如下:在主板上连接示意图 -
AI专题十一:AI系统全景概述 部分内容来自:https://www.cnblogs.com/ZOMI/articles/18555010AI 系统:AI 时代连接硬件和上层应用的中间层软硬件基础设施。因此在部分语境中,又有人称为 AI Infra 人工智能的基础设施,但是因为基础设施更偏向于底层硬件、集群等内容,而 AI 系统是多的是强调让 AI 执行起来的系统体系结构,因此更愿意称包括软硬件的内容为 AI 系统。传统本地部署时代,三大基础软件(数据库、操作系统、中间件)实现控制硬件交互、存储管理数据、网络通信调度等共性功能,抽象并隔绝底层硬件系统的复杂性,让上层应用开发者能够专注于业务逻辑和应用功能本身的创新实现。云时代同理,形成了 IaaS、PaaS、SaaS 三层架构,其中 PaaS 层提供应用开发环境和基础的数据分析管理服务。类比来看,我们认为,进入 AI 时代也有承担类似功能的、连接算力和应用的基础设施中间层即 AI 系统,提供基础模型服务、赋能模型微调和应用开发。包括了如下图几个方面:大模型(算法应用)-AI训练和推理框架-AI编译和计算架构-AI硬件体系这四大体系的主要技术栈:下面分开简述这四大体系:AI 大模型AI 大模型框架实现解析:以 DeepSeek 系列为例目前主流 AI 大模型(包括 DeepSeek 系列)的底层实现主要依托于 PyTorch 生态,但在此基础上构建了高度定制化的训练与推理基础设施。具体的技术栈通常不对外完全公开,但通过开源模型结构与行业惯例可以推断其核心架构。以下是关于 AI 大模型实现框架的核心要点分析:.基础深度学习框架:PyTorch 主导 绝大多数现代大模型(包括 DeepSeek、Llama 系列)均使用 PyTorch 作为基础开发框架。PyTorch 的动态图机制便于模型调试与研究,其丰富的生态库(如 torch.nn、torch.distributed)为构建复杂的 Transformer 架构提供了标准接口。..分布式训练基础设施:定制化加速 为了支撑千亿参数规模的训练,团队通常会在 PyTorch 之上集成 DeepSpeed 或 Megatron-LM 等分布式库,甚至开发内部专有系统。针对 DeepSeek 特有的 MoE(混合专家)架构,训练框架需专门优化专家路由与负载均衡算法,以实现高效的稀疏计算。..推理引擎与部署优化:高性能运行时 模型部署阶段通常不再直接使用原生 PyTorch,而是转换为高性能推理引擎。常见的方案包括 vLLM、TensorRT-LLM 或自研推理后端,通过算子融合、量化(INT8/FP8)及显存优化技术,显著降低延迟并提升吞吐率。..模型互操作性与开源生态 为了兼容不同硬件与框架,大模型权重常支持导出为 ONNX 或 Safetensors 格式。DeepSeek 等开源模型允许社区在 Hugging Face 等平台直接加载,这意味着其结构定义遵循通用的 Transformers 库规范,便于跨框架迁移与二次开发。.综上所述,虽然具体的内部工程细节属于企业机密,但基于 PyTorch 的开源生态配合定制化分布式训练与推理引擎,是目前包括 DeepSeek 在内的大模型行业通用技术路径。这种架构既保证了研发的灵活性,又满足了生产环境对性能与稳定性的严苛要求。AI 训练与推理框架AI 训练和推理框架是深度学习生态系统中的基础设施,主要用于简化模型的开发、优化及部署流程。PyTorch 和 TensorFlow 确实属于这类框架,它们不仅支持模型的训练过程,也提供了推理能力,但在实际生产环境中,二者往往配合专用的推理引擎使用。框架的核心职能:从算法到算力的桥梁AI 框架的核心价值在于屏蔽底层硬件差异,让开发者专注于算法逻辑。它们通过自动微分机制计算梯度,利用计算图优化技术调度资源,从而实现高效的模型迭代。训练阶段:负责数据加载、前向传播、损失计算、反向传播及参数更新,支持分布式训练以加速大规模模型收敛。推理阶段:加载训练好的权重,对新数据进行预测计算,注重低延迟、高吞吐及内存占用优化。PyTorch 与 TensorFlow 的定位与差异这两款主流框架均覆盖了训练与推理的全链路,但设计哲学略有不同。PyTorch 以其动态图机制和灵活的 Python 接口著称,深受学术界和研发人员喜爱;TensorFlow 则拥有成熟的静态图优化能力和强大的服务端部署生态(如 TF Serving),在企业级生产中应用广泛。通用性:两者均支持构建复杂的神经网络结构,并提供丰富的预训练模型库。部署能力:虽然都支持直接推理,但为了极致性能,通常会将模型导出为中间格式(如 ONNX)或使用专用编译器(如 TorchScript、TFLite)进行加速。训练框架与推理引擎的生态协同在实际工程落地中,"训练框架"与"推理引擎"常有分工。训练框架侧重灵活性与易用性,而推理引擎侧重性能与资源管控。模型导出:训练完成后,模型常被转换为特定格式(如 .pt、.pb、.onnx),以便在不同硬件上运行。专用加速:生产环境常使用 TensorRT、OpenVINO 等推理引擎加载框架导出的模型,以充分发挥 GPU 或 NPU 的算力,实现比原生框架推理更高的效率。核心能力总结为了更清晰地理解这两类框架的功能边界,以下列举其关键能力:自动微分系统:自动计算梯度,免除手动推导公式的繁琐,是训练深度学习模型的基础。计算图优化:通过算子融合、内存复用等技术,减少计算开销并提升执行效率。硬件抽象层:统一接口支持 CPU、GPU 及各类 AI 加速芯片,实现代码的跨平台运行。生态工具链:提供数据预处理、模型可视化、调试及部署服务的一站式解决方案。动态与静态模式:支持动态图便于调试研发,支持静态图便于生产部署优化。综上所述,PyTorch 和 TensorFlow 是典型的 AI 训练与推理框架,它们构成了现代人工智能开发的主干。但在高性能部署场景下,通常会结合专用的推理引擎或编译器,以实现从算法研发到终端落地的最佳性能平衡。类似验证中的UVM、OVMAI编译器概述编译器可以将整个程序转换为目标代码(object code),这些目标代码通常存储在文件中。目标代码也被称为二进制代码,在进行链接后可以被机器直接执行。典型的编译型程序语言有 C 和 C++。当前,AI 编译器的发展阶段似乎回到了 GCC 出现之前的时代。每家 AI 芯片公司都在推出自己的 AI 编译器、框架 甚至软件栈,市场上出现了极度碎片化的现象。这种理解抓住了 AI 编译器的核心流向,但在具体的技术实现细节上存在简化。AI 编译器的工作流程比“直接编译 Python 到二进制”更为复杂,涉及多层抽象与优化。以下是对其输入输出机制的详细解析:输入层面:计算图与中间表示(IR)而非纯 Python 代码AI 编译器的直接输入通常不是原始的 Python 脚本,而是由深度学习框架(如 PyTorch、TensorFlow)生成的计算图(Computational Graph)或中间表示(IR)。技术细节:Python 在此过程中主要充当“宿主语言”,用于定义模型结构。编译器前端会通过追踪(Tracing)或图捕获(Graph Capture)技术,将 Python 代码转换为与语言无关的中间表示(如 ONNX、TorchScript、HLO 等)。原因:直接编译动态类型的 Python 代码效率极低,转换为静态 IR 后,编译器才能进行算子融合、内存优化等高级变换。输出层面:运行时引擎与集成库而非单一 Kernel 文件编译后的产出物通常不是一个独立的 GPU Kernel 二进制文件,而是一个包含多个优化算子、内存管理逻辑及调度策略的运行时库或模型引擎。技术细节:最终产物可能是动态链接库(.so/.dll)、序列化模型文件(如 TensorRT 的 .engine 或 TVM 的 .tar),其中封装了多个针对特定硬件优化的 Kernel 代码(如 CUDA PTX 或机器码)。原因:深度学习模型由成百上千个算子组成,编译器需要生成完整的执行计划,处理数据搬运、内核启动及同步,单一二进制文件无法承载完整的推理逻辑。Python 的角色:接口调度而非计算主体在整个编译与部署链路中,Python 主要承担接口调用与数据调度的角色,而非实际计算负载的承担者。技术细节:在推理阶段,Python 脚本负责加载编译好的二进制引擎,将输入数据张量传递给底层运行时,由编译后的 native 代码在 GPU 上执行密集计算。补充信息:这种架构设计实现了“开发效率”与“运行性能”的解耦,开发者使用友好的 Python 生态,而机器执行高效的底层二进制指令。综上所述,AI 编译器实质上是一个将高层模型描述转换为硬件专属高效指令集的翻译与优化系统,其核心价值在于屏蔽硬件差异并最大化算力利用率。AI硬件架构AI硬件架构主要包括CPU、GPU、TPU、NPU和LPU五大类型,并通过系统级协同和混合部署实现高效算力支撑。核心硬件类型与特点CPU(中央处理器)CPU专为通用计算设计,适合处理复杂逻辑、分支和系统级任务,严格遵循冯·诺依曼结构,核心包括控制单元和算术逻辑单元(ALU)。在AI系统中,CPU负责任务调度、队列管理、资源分配以及强化学习(RL)环境的仿真和多智能体控制。 GPU(图形处理器)GPU擅长大规模并行浮点运算,适合深度学习训练和推理。现代GPU通过CUDA、Tensor Core等技术支持通用计算,成为AI计算的核心加速器。 TPU(张量处理单元)TPU是Google开发的专用AI加速器,针对矩阵运算和深度学习优化,提供高吞吐量和低延迟,适合大规模模型训练和推理。NPU(神经网络处理器)NPU面向边缘设备和移动端AI应用,优化低功耗、高效推理,支持语音识别、图像处理等任务。LPU(逻辑处理单元)LPU用于特定逻辑加速场景,如AI推理中的规则计算和控制逻辑,通常与NPU或GPU协同工作。来源系统级协同与混合部署CPU-GPU协同:在多智能体、强化学习和复杂仿真场景中,CPU负责环境步进、控制逻辑和数据管理,GPU负责梯度计算和模型训练。提高CPU:GPU比值可优化GPU利用率,降低空转和延迟。 混合算力架构:结合本地GPU与云端租用GPU,形成“本地核心算力池+云端弹性算力池”,既保证数据安全和低延迟,又能应对突发峰值需求,实现成本和效率的平衡。 AI应用解决方案中的硬件架构成熟的AI应用通常由三大模块构成:智能硬件终端:支持多模态交互,如语音、人脸、触觉等。AI技术中台:提供核心算力和模块化能力,快速响应定制化需求。数据服务体系:收集用户行为数据,进行分析和策略输出,实现全链路闭环的智能决策。 发展趋势AI芯片市场持续增长,专用推理芯片和系统级性能优化成为核心竞争力。CPU与GPU的协同效率将成为数据中心设计重点,系统级优化取代单芯片性能。混合部署和垂直整合将加速,满足大模型训练、实时推理和多任务并发需求。 通过理解这些硬件架构及其协同方式,开发者可以根据应用场景选择合适的算力方案,实现AI系统的高效运行。
-
AI专题十:算力芯片对比与算力芯片指标 一、NVIDIA GPU系列型号架构显存内存带宽FP8算力FP4算力TDP定位A100Ampere80GB HBM2e2 TB/s--400W上一代通用H100 SXMHopper80GB HBM33.35 TB/s3,958 TFLOPS-700W当前训练主力H200 SXMHopper141GB HBM3e4.8 TB/s3,958 TFLOPS-700W大模型推理优化B200Blackwell192GB HBM3e8 TB/s9,000 TFLOPS18,000 TFLOPS1000W2025旗舰关键洞察:• H200与H100计算性能相同(3,958 TFLOPS FP8),但内存容量提升76%(141GB vs 80GB),带宽提升43%(4.8 vs 3.35 TB/s)spheron.networkspheron.netw…• B200采用双die封装,FP8算力是H100的2.3倍,内存带宽是H200的1.7倍 GPU Cloud• B200的180-192GB显存可单卡容纳70B-180B参数模型,无需张量并行 二、华为昇腾系列(国产)型号工艺显存内存带宽FP16算力设计特点出货情况昇腾910B中芯N+1(7nm)64GB HBM2e400GB/s → 1.2TB/s(910B3)320 TFLOPS达芬奇架构,受限工艺2024年出货约40万颗昇腾910C中芯N+2(7nm)HBM2e/HBM3~1.2TB/s800 TFLOPS双die合封(类似B200)2025年预计70-80万颗关键洞察:910C采用双die封装设计,将两颗910B整合,FP16算力达800 TFLOPS,约为H100的80% 910C芯片逻辑面积比H100多60%,架构效率仍有差距 中芯国际N+2工艺良率从2024年20%提升至2025年40-50% 910B均价约11万元/片,910C约18-20万元/片,远低于H100的2.5-3万美元 未来路线图(2025-2028):昇腾950:引入FP8/FP4,算力达1 PFLOPS(FP8),支持SIMT编程模型昇腾960/970:每代算力翻倍,970达8 PFLOPS(FP4),能效比提升30%三、AMD GPGPU系列型号架构显存内存带宽FP8算力特点发布时间MI300XCDNA 3192GB HBM35.3 TB/s2,614 TFLOPS内存容量领先H100已发布MI325XCDNA 3256GB HBM3E6 TB/s-内存进一步提升2024年底MI350XCDNA 4 (3nm)288GB HBM3E8 TB/s-FP4/FP6支持,推理性能提升35倍2025年中关键洞察:MI300X的192GB HBM3容量超过H100(80GB),带宽5.3 TB/s也高于H100的3.35 TB/s AMD软件生态(ROCm)仍是最大短板,CUDA代码移植困难 MI350X将支持FP4/FP6,与NVIDIA B200直接竞争四、Google TPU系列型号定位峰值性能内存互联特点发布时间TPU v5e推理优化393 TOPS (INT8)-256芯片Pod2.5倍推理性价比2023TPU v5p训练100 Peta-OPS INT8 (Pod)--训练导向2023TPU v6e (Trillium)训练+推理4.7倍v5峰值2倍v5容量Jupiter: 100K芯片/Pod训练Gemini 2.0,能效提升67%2024TPU v7x (Ironwood)推理优先~4,614 TFLOPS/芯片 ( rumored)192GB~9,216芯片/Pod专为LLM调优,30倍能效提升2025预览五、综合对比表厂商旗舰型号显存容量内存带宽FP8算力制程核心优势主要短板NVIDIAB200192GB8 TB/s9 PFLOPS4NP生态垄断(CUDA)、性能最强价格极高、供应受限NVIDIAH200141GB4.8 TB/s3.96 PFLOPS4N内存升级、软件兼容算力与H100相同AMDMI350X288GB8 TB/s-3nm内存容量最大、性价比高软件生态(ROCm)弱AMDMI300X192GB5.3 TB/s2.6 PFLOPS5nm大显存、成本较低软件支持不足华为910C-~1.2 TB/s0.8 PFLOPS (FP16)7nm(N+2)国产自主、供应链安全单卡性能落后1-2代华为910B64GB1.2 TB/s0.32 PFLOPS7nm(N+1)国产替代首选性能落后、生态建设中GoogleTPU v6e--4.7倍v5-与云深度整合、能效高仅云可用、灵活性差GoogleTPU v7x192GB-~4.6 PFLOPS-推理优化、超大规模Pod尚未正式发布六、关键趋势总结维度趋势内存容量竞赛从80GB(H100) → 192GB(B200/MI300X) → 288GB(MI350X),大模型单卡部署成关键内存带宽瓶颈推理阶段带宽比算力更重要,8 TB/s成为新标杆精度降低FP8→FP4普及,B200支持FP4实现18 PFLOPS国产替代加速华为昇腾910C大规模出货(70-80万颗/年),性能达H100 80%软件生态分化CUDA仍垄断,但ROCm、CANN、XLA/JAX多极竞争Chiplet架构B200、910C、MI300X均采用多die封装,提升良率和扩展性七、核心算力单位:TOPS vs TFLOPSTOPS:整数算力的代表TOPS 的全称是Tera Operations Per Second,拆解来看:OPS:Operations Per Second,即每秒完成的计算操作次数;T:Tera,代表 1 万亿(10¹²)。所以1 TOPS = 每秒完成 1 万亿次整数运算。它主要用于衡量AI 推理场景的算力,比如图像识别、目标检测、分类等边缘 AI 任务,像 Jetson 系列边缘开发板,标注算力时就常用 TOPS。简单记:TOPS = 整数算力,看 AI 推理快不快。TFLOPS:浮点算力的代表TFLOPS 的全称是Tera Floating-point Operations Per Second,拆解来看:FLOPS:Floating-point Operations Per Second,即每秒完成的浮点运算(带小数点的数)次数;T:同样代表 1 万亿。所以1 TFLOPS = 每秒完成 1 万亿次浮点运算。它主要用于衡量深度学习训练、科学计算场景的算力,比如显卡、大型训练集群标注算力时,就常用 TFLOPS。简单记:TFLOPS = 小数算力,看训练 / 科学计算强不强。八、关键数据类型:FP32、FP16、INT8 详解INT8:8 位整数存储规则:用 8 位二进制存储,只能表示整数,范围是 - 128~127,没有小数点,不存在 “小数点后几位” 的概念;通俗举例:只能存 1、5、-10 这类整数,存不了 1.5、3.14 这类小数;核心特点:占用空间最小,计算速度最快,精度最低(仅支持整数运算);对应算力单位:TOPS;适用场景:AI 推理(模型量化后常用,在保证精度损失极小的前提下,大幅提升推理速度、降低内存占用)。FP16:16 位浮点存储规则:用 16 位二进制存储小数,其中1 位符号位、5 位指数位、10 位尾数位,小数点后能保留约 3~4 位有效数字;通俗举例:能存 3.14、0.005、-2.7 这类小数,但如果是 3.1415926,会近似存为 3.1416,小数点后第 5 位会四舍五入;核心特点:速度快,显存 / 内存占用小,平衡了速度与精度;对应算力单位:TFLOPS;适用场景:深度学习训练、推理都常用(混合精度训练的核心数据类型,既能保证训练效果,又能提升速度)。FP32:32 位浮点存储规则:用 32 位二进制存储小数,其中1 位符号位、8 位指数位、23 位尾数位,小数点后能保留约 6~7 位有效数字;通俗举例:能精准存 3.1415926、0.0001234、-5.678901 这类小数,小数点后前 7 位基本不会丢失精度;核心特点:精度最高,但计算速度最慢,占用空间最大(是 FP16 的 2 倍、INT8 的 4 倍);对应算力单位:TFLOPS;适用场景:科学计算、部分对精度要求极高的训练 / 推理任务(比如医学影像分析、高精度数值模拟)。三者核心区别与算力影响总结对算力的核心影响:数据类型位数越少,芯片一次能并行处理的计算次数越多,算力自然越高。比如同一块芯片,INT8 算力通常是 FP16 的 2 倍、FP32 的 4 倍 —— 因为 INT8 占 8 位,芯片一次能处理 4 个 INT8 数据,而 FP32 占 32 位,一次只能处理 1 个,算力差距就此拉开。九、数据类型与算力的关系:越小越快,算力越高很多新人会疑惑:为什么同一块芯片,INT8 算力比 FP32 高这么多?核心原因就在于数据类型的位数。数据类型的位数越少,芯片一次能并行处理的计算次数就越多,算力自然越高。同一块芯片的算力规律是:INT8 算力 > FP16 算力 > FP32 算力。举个直观的例子:算 INT8(8 位):芯片一次能处理 8 个数据,算力达到峰值;算 FP16(16 位):芯片一次只能处理 4 个数据,算力减半;算 FP32(32 位):芯片一次仅能处理 2 个数据,算力最低。这也是为什么 AI 推理 常用 INT8,训练常用 FP16,高精度计算才用 FP32 的原因。十、实战结合:从硬件算力到模型推理速度我们先来看这张 YOLO26 系列模型的性能对比表,它直观展示了不同尺寸模型在精度、速度、计算量上的差异,是我们理解 “硬件算力” 和 “模型计算量” 关系的绝佳例子:这张表是 YOLO26 系列(n/s/m/l/x 从最小到最大)在 COCO 数据集上的实测结果,其中最关键的一列是 FLOPs(B),它代表每个模型完成一次推理(输入一张 640×640 图片)需要的浮点运算次数(单位是十亿次)。先看 Jetson AGX Orin 的硬件算力(FLOPS)Jetson AGX Orin 作为边缘 AI 硬件,它的算力是硬件本身的 “速度指标”,表示每秒能完成多少次浮点运算,官方参数如下:FP16(半精度浮点)算力:约 6.666 TFLOPS(每秒 6.666 万亿次浮点运算)FP32(单精度浮点)算力:约 3.333 TFLOPS(每秒 3.333 万亿次浮点运算)INT8(整数)算力:200~275 TOPS(对应边缘 AI 推理场景)简单记:硬件算力(FLOPS)就像你的 “跑步速度”,比如每秒能跑 10 米。再看模型计算量(FLOPs)表中的 FLOPs(B) 是模型的 “工作量指标”,表示完成一次推理需要多少次浮点运算。比如:YOLO26n(最小模型):5.4B → 一次推理需要 5.4 十亿次浮点运算YOLO26s(中等模型):20.7B → 一次推理需要 20.7 十亿次浮点运算YOLO26x(最大模型):193.9B → 一次推理需要 193.9 十亿次浮点运算简单记:模型计算量(FLOPs)就像你要跑的 “路程”,比如跑 100 米需要 100 步。两者的核心区别:速度 vs 工作量两者的关系:硬件算力 × 时间 = 模型计算量就像 “跑步速度 × 跑步时间 = 跑步距离”,硬件算力和模型计算量的关系可以用公式表示:理论推理速度(FPS,每秒处理图片数)= 硬件算力(FLOPS) ÷ 模型计算量(FLOPs)用 Jetson AGX Orin + YOLO26 系列举例:我们用 Orin 的 FP16 算力(6.666 TFLOPS = 6.666×10¹² 次 / 秒)来计算不同模型的理论 FPS :实际意义:选模型、配硬件的核心逻辑• 如果你的硬件算力(FLOPS)固定(比如用 Jetson AGX Orin),模型计算量(FLOPs)越小,推理速度越快,越适合边缘场景;• 如果你的模型计算量(FLOPs)固定(比如选 YOLO26x),硬件算力(FLOPS)越高,推理速度越快,越适合高性能场景。这也是为什么表格中 YOLO26n 速度最快、YOLO26x 速度最慢的原因 —— 计算量直接决定了硬件需要 “跑多远”。时、总结:核心要点最后把所有知识点浓缩成 7 句话,记牢这几句就够:算力 = 芯片每秒完成的计算次数;TOPS 是整数算力,对应 INT8,主打 AI 推理;TFLOPS 是浮点算力,对应 FP16/FP32,主打训练 / 科学计算;INT8:8 位整数,无小数点,最快、最小、精度最低;FP16:16 位浮点,小数点后约 3~4 位精度,速度与精度平衡,最常用;FP32:32 位浮点,小数点后约 6~7 位精度,精度最高、最慢、占用最大;同芯片算力:INT8 > FP16 > FP32。十一:TFLOPS 是是指计算fp32、fp16, 还是fp8?TFLOPS 的定义术语全称含义TFLOPSTera Floating Point Operations Per Second每秒万亿次浮点运算TOPSTera Operations Per Second每秒万亿次运算(含整数) 不同精度的算力关系(以NVIDIA H100为例)精度算力相对FP32倍数应用场景FP64(双精度)67 TFLOPS0.5x科学计算(气象/物理模拟)FP32(单精度)134 TFLOPS1x通用计算、传统深度学习TF32 Tensor Core989 TFLOPS7.4x训练默认精度(接近FP32范围+FP16精度)BF16 Tensor Core1,979 TFLOPS14.8x训练主流(与FP32相同范围)FP16 Tensor Core1,979 TFLOPS14.8x混合精度训练FP8 Tensor Core3,958 TFLOPS29.5x大模型训练/推理主流INT83,958 TOPS-量化推理规律:每降低一档精度,理论算力翻倍(利用Tensor Core的并行度提升)。厂商宣传惯例场景通常引用的精度原因科学计算/数据中心通用FP64/FP32传统HPC领域标准AI训练(2020年前)FP16/TF32混合精度训练时代AI训练/推理(当前)FP8大模型时代主流,数字最大最好看极致量化推理FP4/INT8边缘部署、极致压缩为什么大模型用FP8?因素说明Transformer特性Attention计算对数值精度不敏感,FP8足够内存带宽节省FP8比FP16省50%带宽,缓解内存墙训练稳定性配合Transformer Engine的动态缩放,FP8训练已成熟硬件支持H100/B200原生FP8 Tensor Core,无额外开销实际工程中的算力计算示例:H100 SXM5官方标称:FP8: 3,958 TFLOPS(宣传用,数字最大)FP16: 1,979 TFLOPSFP32: 134 TFLOPS(无Tensor Core)FP64: 67 TFLOPS实际大模型训练:使用FP8 + Transformer Engine有效算力通常为理论值的10-30%(内存带宽、通信、算法效率限制)实际约 400-1,200 TFLOPS一句话总结TFLOPS是单位,必须带精度才有意义。当前大模型领域默认指FP8 TFLOPS,但看实际性能时,内存带宽(GB/s)和显存容量(GB)往往比算力数字更重要。对比芯片时,务必确认:同精度对比(都用FP8或都用FP16)看内存带宽(推理瓶颈)看显存容量(模型能不能放下)看互联带宽(多卡扩展能力)
-
AI专题九:大模型与算力芯片 一 运行大模型的算力芯片分类目前大模型运行芯片类型多样,各有侧重。以下是系统梳理:芯片类型代表厂商/产品核心定位大模型场景GPUNVIDIA H100/B200/RTX、AMD MI300X通用并行计算训练+推理主力GPGPUNVIDIA A100/H100、AMD Instinct通用计算GPU(去掉图形管线)数据中心AI训练TPUGoogle Cloud TPU v5p专用AI加速器Google生态训练NPU苹果Neural Engine、高通Hexagon端侧AI推理手机/PC本地大模型DPUNVIDIA BlueField、AMD Pensando数据处理器(卸载网络/存储)数据中心基础设施IPUGraphcore(已被收购)图处理器曾用于GNN/稀疏计算LPUGroq语言处理器(SRAM架构)低延迟推理NPU(国产)华为昇腾910B、寒武纪MLU370国产AI训练/推理国产替代方案DSA百度昆仑芯、阿里含光800领域专用架构特定场景优化FPGAAMD/Xilinx Versal、Intel Agilex可编程逻辑原型验证、低量产场景CPUIntel Xeon、AMD EPYC通用处理器小模型推理、预处理存算一体知存科技、后摩智能存储内计算边缘低功耗推理二、核心概念辨析对比项GPU(图形处理器)GPGPU(通用计算GPU)设计初衷图形渲染(游戏/显示)科学计算、AI、数据分析功能完整性含图形管线(光栅化、纹理等)去掉图形专用单元,专注计算典型产品NVIDIA RTX 4090、AMD RX 7900NVIDIA A100/H100、AMD MI300X使用场景游戏、内容创作、轻量AI数据中心大模型训练DPU的特殊定位特性说明核心功能卸载CPU的网络、存储、安全任务(SmartNIC进化版)与GPU关系协同工作,不是替代。DPU管"数据搬运",GPU管"计算"大模型作用优化多卡通信(RDMA、集合通信加速)、存储虚拟化典型架构ARM核心 + 硬件加速引擎(加密/压缩/网络)+ PCIe交换CPU(控制) ←→ DPU(网络/存储卸载) ←→ GPU(计算) ↓ 高速互联(NVLink/InfiniBand)三、各类芯片深度对比训练场景芯片对比芯片架构特点优势劣势NVIDIA H100/B200Transformer Engine、FP8支持、NVLink 4.0生态垄断(CUDA)、性能最强价格极高、供应受限AMD MI300X192GB HBM3、统一内存架构显存大、性价比高软件生态(ROCm)弱于CUDAGoogle TPU v5p脉动阵列、BF16优化与Google云深度整合、大规模Pod灵活性差、仅云可用华为昇腾910B达芬奇架构、HBM2e国产自主、政府/金融首选单卡性能落后1-2代、软件生态建设中Intel Gaudi3张量处理器 + 以太网互联成本较低、开放以太网生态弱、市场份额小推理场景芯片对比芯片类型优势场景代表产品关键指标高端GPU高吞吐、大batch推理NVIDIA H100/L4吞吐量(tokens/sec)LPU(Groq)超低延迟、确定性延迟Groq Chip延迟<1ms、无HBM瓶颈NPU(端侧)低功耗、本地隐私苹果M4 Neural Engine、高通X Elite能效比(TOPS/Watt)DSA(定制)特定模型极致优化百度昆仑芯、阿里含光特定模型性价比存算一体超边缘、TinyML知存科技WTM-8功耗<1mW四、架构演进趋势从通用到专用 2012-2017:CPU → GPU(通用并行)2017-2022:GPU → TPU/IPU(AI专用)2022-现在:GPU → DPU+GPU协同(系统级优化)未来:存算一体、光子计算、神经形态芯片关键技术创新方向技术原理代表近存计算计算靠近存储,减少数据搬运阿里含光800、GroqChiplet/芯粒模块化封装,灵活组合AMD MI300X、Intel Ponte VecchioHBM高带宽存储3D堆叠内存,突破带宽墙HBM3e(1.2TB/s)CPO光电共封装光互连替代电互连NVIDIA、Broadcom研发中稀疏计算加速利用MoE等稀疏性NVIDIA Transformer Engine五、选型决策框架场景首选芯片关键考量大模型训练(100B+)NVIDIA H100/B200集群CUDA生态、NVLink互联、FP8支持训练(预算敏感)AMD MI300X、华为昇腾910B集群性价比、国产合规云端高吞吐推理NVIDIA L4/L40S、自研DSA成本($/token)、功耗超低延迟推理Groq LPU、高端GPU+优化首token延迟(TTFT)端侧(手机/PC)NPU(苹果/高通/联发科)能效比、隐私保护边缘/嵌入式存算一体芯片、FPGA功耗<1W、成本<$10国产替代华为昇腾、寒武纪、百度昆仑芯供应链安全、政策支持六、芯片算力是怎么计算的?基本公式精度算力公式说明FP32(单精度浮点)算力 = 频率 × CUDA核心数 × 2每个核心每周期2次FMA运算FP16/BF16(半精度)算力 = FP32算力 × 2张量核心支持2倍吞吐FP8/INT8算力 = FP32算力 × 4更低精度4倍吞吐稀疏化(2:4)算力 = dense算力 × 2利用稀疏性再翻倍H100 SXM5 规格:GPU频率:约1.98 GHz(动态调整)CUDA核心数:16896个(但张量核心更重要)张量核心:528个第四代Tensor CoreFP8算力计算:= 频率 × Tensor Core数量 × 每周期操作数 × 稀疏加速= ~1.98GHz × 528 × 2048 × 2(稀疏)≈ 3958 TFLOPS(与官方3958 TFLOPS FP8一致)关键:现代GPU算力主要来自Tensor Core,非CUDA Core实际有效算力 vs 理论峰值因素影响典型效率内存带宽瓶颈数据供给跟不上计算10-30%(HBM瓶颈)算法效率无法利用全部并行度30-60%通信开销多卡同步等待20-50%(大规模集群)实际有效算力理论峰值 × 综合效率通常5-20%案例:H100理论3958 TFLOPS FP8,大模型训练实际可能只有200-400 TFLOPS(5-10%效率)。七、芯片算力与大模型参数的关系训练阶段:算力需求估算指标公式示例(GPT-3 175B)训练token数通常2-10倍参数量300B tokens总计算量≈ 6 × 参数量 × token数6 × 175B × 300B = 3.15e23 FLOPs所需GPU小时总FLOPs / (GPU算力 × 效率)约3648 GPU小时(1024张H100,3.5天)Transformer前向+反向计算量 ≈ 6 × P × DP: 参数量D: token数系数6: 前向2次,反向4次(梯度计算)推理阶段:算力与内存的博弈阶段瓶颈关键公式Prefill(首token)计算密集型时间 ∝ (参数 × 序列长度) / 算力Decode(生成token)内存带宽密集型时间 ∝ 参数 / 内存带宽关键洞察:推理瓶颈转移点:短序列(<1K):Prefill主导,算力重要长序列(>4K):Decode主导,内存带宽重要超长序列(>32K):KV Cache容量成为瓶颈参数-算力-内存三角关系 参数量(P) ↑ / \ / \ / \ / △ \ / 优化 \ /____________\ 算力(FLOPS) ←→ 内存带宽(GB/s)场景瓶颈维度优化方向训练大模型算力 + 互联带宽更多GPU + NVLink/InfiniBand长上下文推理内存带宽 + 容量HBM3e + KV Cache压缩(MQA/GQA)低延迟推理算力密度 + 片上SRAMGroq LPU(230MB SRAM,无HBM)端侧部署内存容量 + 功耗量化(INT4)+ 剪枝 + NPU专用八、大模型参数设计的芯片约束参数规模 vs 硬件匹配参数规模典型模型单卡显存需求训练配置7BLLaMA-2-7B~14GB(FP16)单卡RTX 4090可推理13BLLaMA-2-13B~26GB单卡A100或双卡409070BLLaMA-3-70B~140GB8×A100(80GB)或2×H100175BGPT-3~350GB数百张V100/A100405BLLaMA-3.1-405B~810GB16K+ H100 GPU集群1T+GPT-4/文心5.0~2TB+万卡集群 + 专家并行MoE架构:参数与算力的解耦架构总参数激活参数显存占用计算量Dense(密集)100B100B200GB100B × tokenMoE(稀疏)1T100B(10%)~400GB(共享+专家)100B × token九、实际工程计算示例场景:用H100训练LLaMA-3-70B已知:模型:70B参数数据:1.4T tokens(约20倍参数,较充分训练)硬件:H100 SXM5(80GB HBM3,FP8 3958 TFLOPS)并行策略:张量并行8路 + 流水线并行4路 = 32卡计算:总计算量 = 6 × 70B × 1.4T = 5.88e20 FLOPs单卡有效算力(假设10%效率)= 3958 × 0.1 = 395 TFLOPS32卡集群总有效算力 = 32 × 395 = 12640 TFLOPS = 1.264e13 FLOPS训练时间 = 5.88e20 / 1.264e13 = 4.65e7秒 ≈ 540小时 ≈ 22.5天实际:配合 checkpoint、故障恢复,通常需3-4周场景:H100推理LLaMA-3-70B,batch=1 已知:模型:70B参数,FP16序列:4K上下文硬件:H100(3.35TB/s HBM带宽)计算:加载权重时间:140GB / 3.35TB/s ≈ 42ms(可忽略,常驻显存)Prefill阶段(4K tokens):计算量 ≈ 2 × 70B × 4K = 5.6e14 FLOPs时间 ≈ 5.6e14 / 3958e12 ≈ 141ms(若算力瓶颈)实际受内存带宽限制,可能更长Decode阶段(每生成1 token):需加载全部70B参数:140GB时间 = 140GB / 3.35TB/s ≈ 42ms(纯带宽瓶颈)实际约30-50ms/token优化后(vLLM/PagedAttention,batch增大):batch=16时,吞吐可达~2000 tokens/s十、关键结论关系核心洞察算力≠性能内存带宽、互联带宽、软件效率同样关键参数≠能力MoE架构解耦参数与计算,效率优先训练看算力算力决定训练速度,集群规模决定模型上限推理看带宽生成阶段内存带宽是瓶颈,非算力端侧看能效功耗约束下,专用NPU比通用GPU优10-100倍
-
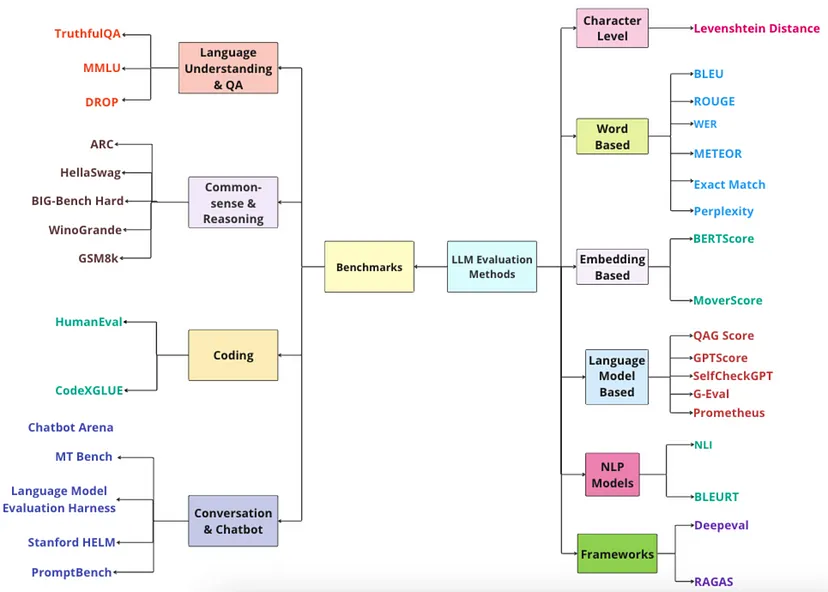
AI专题八:大模型的指标与评估方法 来自:https://zhuanlan.zhihu.com/p/26098146564首先,通过下面的表格来了解传统机器学习、深度学习和大语言模型之间的区别。大语言模型的出现为解决以往被认为不可能的问题开辟了新途径。但有一个问题仍待解答:如何有效地评估基于大模型的应用程序呢?在本文中,我们将试图揭开这个谜题,了解用于基准测试大语言模型的方法,讨论最前沿(SOTA)的方法、可用的框架,以及评估基于大语言模型的应用程序时面临的挑战。评估大语言模型的基本思路从哪里开始评估大语言模型?模型选择至关重要,因为它会影响项目的最终结果。在选定模型后,下一步就是思考如何评估它。许多从业者最初会依赖提示工程来评估模型的选择,但这不足以全面评估大语言模型的有效性,我们需要一个更全面的评估策略。模型评估是复杂的,涉及各种指标,这些指标因优先事项而异,无论是优先考虑准确性、成本效益还是性能。你选择的方向应与特定需求保持一致,确保所选模型不仅适用,还能优化你的应用场景。在为应用选择最佳大语言模型时,可参考以下简化方法(上图中有更多详细信息):是否有标准答案?是:如果模型提供离散输出,可使用传统的准确率指标。若不是,则考虑其他相似性指标,如ROUGE。否:进入步骤2。是否需要自动化评估?是:使用大语言模型评判器或评估器。否:进入步骤3。是否面临时间限制?是:选择独立指标,如文本质量、可读性或困惑度。否:黄金标准是人工评估。虽然它速度较慢且成本较高,但由于需要大量人力投入,能提供最可靠的反馈。接下来,我们将详细讨论这些技术。大语言模型基准测试与评估的差异虽然大语言模型的基准测试和评估紧密相关,但它们的目的存在细微差别:基准测试主要是标准化测试。它使用预定义的数据集和指标,评估大语言模型在特定任务上的表现。可以把它想象成给语言模型进行阅读、写作和数学测试(只不过是针对语言的测试!)。基准测试的优势如下:便于比较:研究人员可以通过基准测试,比较不同大语言模型在相同任务上的性能,有助于确定哪些模型在特定领域表现出色。量化结果:基准测试提供数值分数,清晰展示大语言模型的优势和劣势。评估的范围则更为广泛。它不仅仅是运行测试,还包括对大语言模型能力更全面的评估。在评估时,研究人员会考虑以下方面:实际适用性:大语言模型在模拟现实应用场景中的表现如何?公平性和偏差:大语言模型的输出是否存在偏差?可解释性:研究人员能否理解大语言模型得出答案的过程?评估通常以基准测试为基础。研究人员可能会将基准测试分数作为起点,但也会深入探究基准测试未涵盖的方面。简单来说,基准测试通过标准化测试进行定量评估,而评估则能让我们更定性地了解大语言模型的整体优势、劣势以及对现实应用的适用性。大语言模型基准测试大语言模型基准测试框架大语言模型基准测试是一组标准化测试,旨在评估大语言模型在各种技能(如推理和理解能力)上的表现,并使用特定的评分器或指标来衡量这些能力。根据不同的基准测试,指标范围可以从基于统计的度量(如精确匹配的比例),到由其他大语言模型评估的更复杂的指标。不同的基准测试评估模型能力的不同方面,包括:推理和常识:这些基准测试大语言模型运用逻辑和日常知识解决问题的能力。语言理解和问答(QA):评估模型解释文本和准确回答问题的能力。编码:该类别基准测试评估大语言模型解释和生成代码的能力。对话和聊天机器人:测试大语言模型参与对话并提供连贯、相关回复的能力。翻译:评估模型将文本从一种语言准确翻译成另一种语言的能力。数学:聚焦于模型解决数学问题的能力,从基础算术到微积分等更复杂的领域。逻辑:逻辑基准测试评估模型应用逻辑推理技能(如归纳和演绎推理)的能力。标准化测试:学术水平测试(如SAT、ACT)或其他教育评估也用于评估和基准测试模型的性能。有些基准测试可能只有几十项测试,而其他的可能包含数百甚至数千个任务。重要的是,大语言模型基准测试为跨不同领域和任务评估大语言模型的性能提供了标准化框架。为项目选择合适的基准测试意味着:• 目标一致:确保基准测试与大语言模型需要出色完成的特定任务相匹配。• 任务多样:选择具有广泛任务的基准测试,能全面评估大语言模型。• 贴合领域:选择与应用相关领域的基准测试,无论是理解语言、生成文本还是编码。可以把它们想象成高中生的学术水平测试,只不过是针对大语言模型的。虽然它们无法评估模型能力的方方面面,但确实能提供有价值的见解。下面是Claude 3在多个基准测试中与其他最前沿模型的性能对比。在接下来的部分,我们将讨论4个关键领域(语言理解、推理、编码和对话)的主要大语言模型基准测试。这些基准测试在行业应用中广泛使用,并经常在技术报告中被引用,包括:语言理解和问答基准测试3.1.1 TruthfulQA发布时间:2022年论文代码数据集点击可查看,或者文末在参考文献中查找目标:基于模型提供准确和真实答案的能力对其进行评估。这对于打击错误信息和促进人工智能的道德使用至关重要。• 数据集:原始数据集包含38个类别的817个问题,涵盖健康、法律、金融和政治等类别。问题聚焦于人类可能因错误信念或误解而给出错误答案的领域。• 性能:原始论文中表现最佳的模型GPT-3,成功率仅为58%,而人类基线为94%。• 评分:最终分数基于模型生成的真实输出的比例计算。经过微调的GPT-3(称为“GPT-Judge”)用于判断答案的真实性。3.1.2 MMLU(大规模多任务语言理解)• 发布时间:2021年• 论文代码数据集点击可查看,或者文末在参考文献中查找目标:基于模型的预训练知识评估模型,专注于零样本和少样本设置。基准测试:综合基准测试,通过涵盖57个学科(包括STEM、人文、社会科学等)的选择题评估模型,难度级别从基础到高级不等。该基准测试能很好地识别模型在特定领域的知识差距。评分:MMLU根据正确答案的比例对大语言模型进行评分。输出必须完全匹配才被视为正确(如上述示例中的“D”)。如果觉得MMLU难以使用,有个好消息。有人在开源大语言模型评估框架DeepEval中实现了几个关键基准测试,这样我们只需几行代码就能轻松对任何选定的大语言模型进行基准测试。首先,安装DeepEval:pip install deepeval然后,运行基准测试:from deepeval.benchmarks import MMLU from deepeval.benchmarks.tasks import MMLUTask benchmark = MMLU( tasks=[MMLUTask.HIGH_SCHOOL_COMPUTER_SCIENCE, MMLUTask.ASTRONOMY], n_shots=3 ) benchmark.evaluate(model=mistral_7b) print(benchmark.overall_score)更多实现细节,请访问DeepEval MMLU文档。3.1.3 DROP描述:DROP要求大语言模型对段落进行离散推理。这涉及解析问题中的引用,并执行加法、计数或排序等操作,需要对段落内容有全面的理解。评估设置:3次示例指标:在9536个段落理解问题上的F1分数论文:DROP: A Reading Comprehension Benchmark Requiring Discrete Reasoning Over Paragraphs以上就是开源大语言模型排行榜的七个主要基准测试任务。这些测试不仅评估大语言模型的知识,还评估它们的推理、理解和解决问题的能力。其他值得注意的语言理解和问答基准测试:GLUE、SuperGLUE、SQuAD和GPT任务、CoQA、QuAC、TriviaQA。常识和推理基准测试3.2.1 ARC(AI2推理挑战)发布时间:2018年论文代码点击可查看,或者文末在参考文献中查找描述:AI2推理挑战(ARC)使用小学水平的选择题科学问题测试大语言模型,问题难度从简单到复杂不等。例如,“光合作用产生什么帮助植物生长?”,选项为(a)水 (b)氧气 ©蛋白质 (d)糖。评估设置:25次示例指标:在3548个问题上的准确率,其中33%被指定为具有挑战性的问题。论文:Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge数据集:数据集大小为681MB,分为两组问题:ARC-Easy和ARC-Challenge。3.2.2 HellaSwag• 发布时间:2019年• 论文代码数据集描述:HellaSwag通过句子补全评估大语言模型的常识推理能力。它测试大语言模型是否能从10,000个句子的4个选项中选择合适的结尾。在预训练阶段,当时的最前沿模型得分很难超过50%,而2023年GPT-4通过10次示例提示达到了创纪录的95.3%。与MMLU类似,HellaSwag根据模型给出的完全正确答案的比例进行评分。使用方法:通过DeepEval使用HellaSwag基准测试的方法如下:from deepeval.benchmarks import HellaSwagfrom deepeval.benchmarks.tasks import HellaSwagTaskbenchmark = HellaSwag(tasks=[HellaSwagTask.TRIMMING_BRANCHES_OR_HEDGES, HellaSwagTask.BATON_TWIRLING], n_shots=5)benchmark.evaluate(model=mistral_7b)print(benchmark.overall_score)更多信息,请访问DeepEval的HellaSwag文档页面。3.2.3 BIG-Bench Hard(超越模仿游戏基准测试)发布时间:2022年、代码、数据集:论文代码数据集描述:BIG-Bench Hard(BBH)从最初的BIG-Bench套件中选择了23个具有挑战性的任务,该套件包含204个任务,这些任务在当时超出了大多数语言模型的能力范围。评估方式对比:标准(少样本)提示与思维链(CoT)提示(Wei等人)。在BIG-Bench发布时,没有一个最前沿的语言模型能够在这23个任务中的任何一个上超过平均人类评估者的表现。有趣的是,BBH的作者使用思维链提示,在其中17个任务上超越了人类表现。评分方式:虽然BBH的预期输出比其他基于选择题的基准测试更加多样化,但它同样基于精确匹配的比例对模型进行评分。思维链提示有助于使模型输出符合预期格式。使用方法:使用BBH基准测试的方法如下:from deepeval.benchmarks import BigBenchHard from deepeval.benchmarks.tasks import BigBenchHardTask benchmark = BigBenchHard( tasks=[BigBenchHardTask.BOOLEAN_EXPRESSIONS, BigBenchHardTask.CAUSAL_JUDGEMENT], n_shots=3, enable_cot=True ) benchmark.evaluate(model=mistral_7b) print(benchmark.overall_score)3.2.4 WinoGrande描述:WinoGrande测试人工智能的常识推理能力,要求模型解决Winograd Schema Challenge(WSC)。例如,完成句子:“门打开的声音比窗户大,因为___(选项:门或窗户)的铰链上有更多油脂。”评估设置:5次示例指标:在1267个问题上的准确率论文:WinoGrande: An Adversarial Winograd Schema Challenge at Scale3.2.5 GSM8k描述:GSM8K提供小学数学应用题,测试大语言模型的多步数学推理能力。例如:“一件长袍需要2卷蓝色纤维和蓝色纤维数量一半的白色纤维。总共需要多少卷纤维?”答案是3卷。评估设置:5次示例指标:在1319个问题上的准确率论文:Training Verifiers to Solve Math Word Problems其他值得注意的常识和推理基准测试:CommonsenseQA、COPA、SNLI、MultiNLI、RACE、ANLI、PIQA、COSMOS QA。编码基准测试3.3.1 HumanEval发布时间:2021年论文代码数据集描述:HumanEval由164个独特的编程任务组成,旨在评估模型的代码生成能力。这些任务涵盖从算法到编程语言理解的广泛领域。3.3.2 CodeXGLUE发布时间:2021年论文代码数据集![mnsif8描述:CodeXGLUE提供10个不同任务的14个数据集,用于在各种编码场景(如代码补全、代码翻译、代码摘要和代码搜索)中直接测试和比较模型。它是由微软开发部门和必应合作开发的。评估指标:CodeXGLUE的评估指标因编码任务而异,从精确匹配到BLEU分数不等。其他值得注意的编码基准测试:CodeBLEU、MBPP、Py150、MathQA、Spider、DeepFix、Clone Detection、CodeSearchNet。生成式人工智能模型根据其在4个数据集上的平均性能进行排名:ARC(25次示例)HellaSwag(10次示例)MMLU(5次示例)TruthfulQA(零样本)25次示例意味着在每个问题的提示中插入数据集中的25对(问题,解决方案)。3.4对话和聊天机器人基准测试3.4.1 Chatbot Arena(由LMSys开发)发布时间:2024年论文 代码Chatbot Arena是一个使用超过20万个人类投票对语言模型进行排名的开放平台。用户可以匿名向ChatGPT或Claude等人工智能模型提问并进行评判,且只有在模型身份保持隐藏的情况下,投票才会计入排名。所以它不是一个使用指标客观评分的传统基准测试!分数本质上就是 “点赞” 的数量。3.4.2 MT Bench发布时间:2021年论文 代码 数据集MT-bench通过向聊天助手提出一系列多轮开放式问题来评估其质量,并利用大语言模型作为评判者。这种方法测试了聊天助手处理复杂交互的能力。MT-Bench使用GPT-4对对话进行10分制评分,并计算所有轮次的平均分数以得到最终得分。所有这些基准测试在评估特定技能方面都非常有用,但是如果现有的基准测试与我们项目的独特需求不太匹配呢?3.4.3 语言模型评估工具包(由EleutherAI开发)语言模型评估工具包(Language Model Evaluation Harness)提供了一个统一的框架,用于在大量评估任务上对大语言模型进行基准测试。我特意强调 “任务” 这个词,因为在Harness(我将用Harness代替语言模型评估工具包)中没有 “场景” 这个概念。在Harness中,我们可以看到许多任务,每个任务包含不同的子任务。每个任务或一组子任务在不同领域评估大语言模型,比如生成能力、在不同领域的推理能力等。每个任务下的子任务(甚至有时任务本身)都有一个基准数据集,并且这些任务通常与一些在评估方面的重要研究相关。Harness致力于将所有这些数据集、配置和评估策略(比如与评估基准数据集相关的指标)统一并整合在一个地方。不仅如此,Harness还支持不同类型的大语言模型后端(例如:VLLM、GGUF等)。它在更改提示和进行实验方面具有很大的可定制性。下面是一个如何在HellaSwag任务(一个判断大语言模型常识能力的任务)上轻松评估Mistral模型的小例子:lm_eval --model hf \ --model_args pretrained=mistralai/Mistral-7B-v0.1 \ --tasks hellaswag \ --device cuda:0 \ --batch_size 8受语言模型评估工具包的启发,BigCode项目开发了另一个框架,名为BigCode Evaluation Harness,它试图提供类似的API和命令行界面方法,专门用于评估代码生成任务的大语言模型。3.4.4 斯坦福HELMHELM(语言模型整体评估,Holistic Evaluation of Language Model)使用 “场景” 来概述大语言模型的应用场景,并使用 “指标” 来明确在基准测试中我们希望大语言模型完成的任务。一个场景包括:• 一个任务(与场景相关)• 一个领域(包括文本的类型、作者以及创作时间)• 语言(即任务所使用的语言)然后,HELM会根据社会相关性(例如,考虑面向用户应用程序的可靠性的场景)、覆盖范围(多语言)和可行性(即选择任务的计算最优重要子集进行评估,而不是逐一运行所有数据点)来优先选择场景和指标的子集。HELM的评估分类结构不仅如此,HELM试图为几乎所有场景涵盖7个指标(准确性、校准度、稳健性、公平性、偏差、毒性和效率),因为仅仅依靠准确性并不能完全保证大语言模型性能的可靠性。3.4.5 PromptBench(微软开发)微软Prompt BenchPromptBench是另一个用于大语言模型基准测试的统一库。它与HELM和语言模型评估工具包(Harness)非常相似,支持不同的大语言模型框架(例如:Hugging Face、VLLM等)。它与其他框架的不同之处在于,除了评估任务之外,它还支持评估不同的提示工程方法,并在不同的提示级对抗攻击下评估大语言模型。我们还可以构建不同评估的管道,这使得生产级用例更易于实现。大语言模型基准测试的局限性虽然基准测试对于评估大语言模型的能力至关重要,但它们也有自身的局限性:• 领域相关性:基准测试往往难以与大语言模型应用的独特领域和上下文相匹配,缺乏法律分析或医学解读等任务所需的特定性。这一差距凸显了创建能够准确评估大语言模型在广泛专业应用中性能的基准测试所面临的挑战。• 生命周期短:在基准测试刚推出时,通常模型的表现都不太能达到人类基线水平。但过一段时间,比如1 - 3年,先进的模型会让最初的挑战变得轻而易举(就是例证)。当这些指标不再具有挑战性时,就有必要开发新的、有用的基准测试。不过,也并非毫无希望。通过合成数据生成等创新方法,克服这些局限性是有可能的。大语言模型评估指标大语言模型评估指标根据我们关心的标准对大语言模型的输出进行评分。例如,如果我们的大语言模型应用旨在总结新闻文章页面,我们就需要一个基于以下方面进行评分的评估指标:总结是否包含了原文中足够的信息。总结是否包含与原文相矛盾或凭空虚构的内容。此外,如果我们的大语言模型应用采用基于检索增强生成(RAG)的架构,我们可能还需要对检索上下文的质量进行评分。关键在于,大语言模型评估指标是根据其设计要完成的任务来评估大语言模型应用的(注意,大语言模型应用可以仅仅就是大语言模型本身!)。优秀的评估指标具有以下特点:可量化:指标在评估手头任务时,应该始终计算出一个分数。这种方法使我们能够设定一个最低通过阈值,以确定我们的大语言模型应用是否 “足够好”,并且让我们能够在迭代和改进实现的过程中,监测这些分数随时间的变化。可靠:鉴于大语言模型的输出可能不可预测,我们最不希望的就是评估指标同样不稳定。因此,尽管使用大语言模型评估的指标(如G-Eval)比传统评分方法更准确,但它们往往不一致,这也是大多数基于大语言模型评估指标的不足之处。准确:如果可靠的分数不能真正代表我们大语言模型应用的性能,那么它们就毫无意义。要使一个好的大语言模型评估指标变得更出色,秘诀在于尽可能使其符合人类的预期。那么问题来了,大语言模型评估指标如何计算出可靠且准确的分数呢?计算指标分数的不同方法有许多成熟的方法可用于计算指标分数,其中一些方法利用包括嵌入模型和大语言模型在内的神经网络,而另一些则完全基于统计分析。6.1 统计评分器6.1.1 词错误率(WER)词错误率(WER)是一类基于WER的指标,用于测量编辑距离 ,即把候选文本转换为参考文本所需的插入、删除、替换以及可能的换位操作的数量。6.1.2 精确匹配它通过将生成的文本与参考文本进行匹配来衡量候选文本的准确性。与参考文本的任何偏差都会被视为错误。这只适用于抽取式和短格式答案的情况,因为这种情况下期望生成的文本与参考文本的偏差最小或没有偏差。6.1.3 困惑度困惑度(PPL)是评估语言模型最常用的指标之一。在深入了解之前,我们应该注意,这个指标特别适用于经典语言模型(有时称为自回归或因果语言模型),对于像BERT这样的掩码语言模型并不适用。这也等同于数据和模型预测之间交叉熵的指数化。想要深入理解困惑度及其与每字符比特数(BPC)和数据压缩的关系,可以查看The Gradient上的这篇精彩博客文章。6.1.4 BLEUBLEU(双语评估替补,BiLingual Evaluation Understudy)分数是一种广泛用于评估机器翻译文本(候选文本)与参考译文(参考文本)质量的指标。由IBM研究人员开发,BLEU通过测量机器生成的文本与一组高质量参考译文之间的n元语法重叠来评估翻译的准确性,它主要侧重于精确率。BLEU以其简单性和有效性而闻名,是机器翻译领域的标准基准。然而,它主要评估的是表面层次的词汇相似性,常常忽略语言更深层次的语义和上下文细微差别。候选文本:这是我们想要评估的翻译系统的输出。参考文本:这些是高质量的翻译(通常由人工完成),我们将候选文本与之进行比较。为了保证稳健性,参考译文可以不止一个。计算方法from nltk.translate.bleu_score import sentence_bleu reference = [["A", "fast", "brown", "fox", "jumps", "over", "a", "lazy", "dog", "."]] generated = [["The", "quick", "brown", "fox", "jumps", "over", "the", "lazy", "dog", "."]] bleu_score = sentence_bleu(reference, generated) print('BLEU Score:', bleu_score)6.1.5 ROUGEROUGE(面向摘要评估的召回率替代指标,Recall-Oriented Understudy for Gisting Evaluation)是一组用于评估自动摘要和机器翻译的指标。它将自动生成的摘要或翻译与一组参考摘要(通常是人工撰写的)进行比较。ROUGE通过计算模型生成的文本与参考文本之间重叠的单元数量(如n元语法、单词序列和单词对)来衡量摘要的质量。ROUGE最常见的变体有:ROUGE-N:侧重于n元语法(N个单词的短语)。ROUGE-1和ROUGE-2(分别是一元语法和二元语法)最为常用。ROUGE-L:基于最长公共子序列(LCS),它自然地考虑了句子级别的结构相似性,并自动识别最长的共同出现的连续n元语法。ROUGE通常报告三个指标:精确率:模型生成的摘要中的n元语法在参考摘要中也出现的比例。召回率:参考摘要中的n元语法在模型生成的摘要中也出现的比例。F分数(F1分数):精确率和召回率的调和平均数,平衡了这两个指标。ROUGE分数的范围是从0到1,0表示机器生成的文本与参考文本没有重叠,1表示与参考文本完全匹配。from nltk.translate.bleu_score import corpus_rouge reference_summaries = [['A fast brown fox jumps over a lazy dog.']] generated_summaries = [['The quick brown fox jumps over the lazy dog.']] rouge_score = corpus_rouge(reference_summaries, generated_summaries) print('ROUGE Score:', rouge_score)6.1.6 METEORMETEOR(带显式排序的翻译评估指标,Metric for Evaluation of Translation with Explicit Ordering)是一种先进的机器翻译评估指标,旨在解决BLEU分数的一些局限性。与BLEU不同,METEOR不仅考虑精确的单词匹配,还纳入词干提取和同义词来评估翻译,从而捕捉更广泛的语言相似性。它在评估中独特地平衡了精确率和召回率,并引入了对词序差异的惩罚,以评估翻译的流畅性。METEOR与人类判断的相关性更高,尤其是在句子层面,使其成为一个细致全面的翻译质量评估指标。然而,它的复杂性也意味着它比BLEU等简单指标的计算成本更高。基于对齐:METEOR在候选翻译和参考翻译的单词之间创建对齐,关注精确匹配、词干匹配、同义词匹配和释义匹配。召回率和精确率:与仅考虑精确率的BLEU不同,METEOR同时计算精确率和召回率,这种双重关注有助于平衡评估。调和平均数:METEOR使用召回率和精确率的调和平均数,并且对召回率的权重更高(修改后的调和平均数,使召回率比精确率更重要),这与使用修改后的精确率的BLEU不同。词序差异惩罚:METEOR对错误的词序进行惩罚,这使得它对翻译的流畅性很敏感。语言无关:虽然METEOR最初是为英语开发的,但已经扩展到支持多种语言,并配备了特定语言的参数和资源。计算方法编辑距离(Levenshtein distance)评分器计算将一个单词或文本字符串转换为另一个所需的最少单字符编辑(插入、删除或替换)次数,这对于评估拼写纠正或其他对字符精确对齐至关重要的任务很有用。from meteor import meteor_score reference_sentence = 'A fast brown fox jumps over a lazy dog.' generated_sentence = 'The quick brown fox jumps over the lazy dog.' meteor_score = meteor_score.meteor_score([reference_sentence], generated_sentence) print('METEOR Score:', meteor_score)6.2 基于模型的评分器纯粹基于统计的评分器虽然可靠但不准确,因为它们难以考虑语义。在本节中,情况则恰恰相反,纯粹依赖自然语言处理(NLP)模型的评分器相对更准确,但由于其概率性质,也更不可靠。不出所料,非大语言模型的评分器比基于大语言模型评估(LLM-Evals)的评分器表现更差,原因与统计评分器相同。非大语言模型评分器包括:6.2.1 蕴含分数蕴含分数:这种方法利用语言模型的自然语言推理能力来评判自然语言生成(NLG)。这种方法有不同的变体,但基本概念是使用自然语言推理(NLI)模型针对参考文本生成蕴含分数,以此对生成的内容进行评分。这种方法对于确保像文本摘要这样基于文本的生成任务的忠实度非常有用。6.2.2 BLEURTBLEURT(基于Transformer表示的双语评估替补,Bilingual Evaluation Understudy with Representations from Transformers)是一种新颖的、基于机器学习的自动评估指标,能够捕捉句子之间细微的语义相似性。它在公开的评分数据集(WMT Metrics Shared Task数据集)以及用户提供的额外评分上进行训练。创建一个基于机器学习的指标面临一个基本挑战:该指标应该在广泛的任务和领域中始终表现良好,并且要经得起时间的考验。然而,训练数据的数量是有限的。实际上,公开数据很稀少 —— 在撰写本文时,最大的人类评分数据集WMT Metrics Task数据集仅包含约26万个涵盖新闻领域的人类评分。这对于训练一个适合评估未来自然语言生成系统的指标来说太有限了。为了解决这个问题,我们采用迁移学习。首先,我们使用BERT的上下文单词表示,BERT是一种最先进的无监督表示学习方法,用于语言理解,并且已经成功应用于自然语言生成评估指标(例如,YiSi或BERTscore)。其次,我们引入一种新颖的预训练方案来提高BLEURT的稳健性。我们的实验表明,直接在公开可用的人类评分上训练回归模型是一种不稳定的方法,因为我们无法控制该指标将在什么领域以及跨多长时间范围内使用。在存在领域漂移的情况下,即当使用的文本来自与训练句子对不同的领域时,准确性可能会下降。当要预测的评分高于训练期间使用的评分时,准确性也可能下降 —— 这本该是个好消息,因为这表明机器学习研究正在取得进展。BLEURT的成功依赖于在对人类评分进行微调之前,使用数百万个合成句子对来 “预热” 模型。我们通过对维基百科中的句子进行随机扰动来生成训练数据。我们没有收集人类评分,而是使用文献中的一系列指标和模型(包括BLEU),这使得训练示例的数量能够以极低的成本进行扩展。6.2.3 QA-QG问答 - 问题生成(QA-QG)(Honovich等人):这种范式可用于衡量任何候选文本与参考文本的一致性。该方法的工作原理是首先从候选文本中形成(候选答案,问题)对,然后比较并验证针对参考文本中相同问题集生成的答案。除了评分不一致之外,这些方法实际上还存在一些缺点。例如,自然语言推理评分器在处理长文本时准确性也会受到影响,而BLEURT则受其训练数据的质量和代表性的限制。6.3.1 G-EvalG-Eval是一篇题为《使用与人类判断更一致的GPT-4进行自然语言生成评估》的论文中最近开发的一个框架,它使用大语言模型来评估大语言模型的输出(也就是LLM-Evals)。G-Eval首先使用思维链(CoTs)生成一系列评估步骤,然后通过填空范式使用生成的步骤来确定最终分数(这只是一种花哨的说法,意思是G-Eval需要几个信息才能工作)。例如,使用G-Eval评估大语言模型输出的连贯性时,需要构建一个包含评估标准和待评估文本的提示,以生成评估步骤,然后使用大语言模型根据这些步骤输出1到5分的分数。让我们通过这个例子来梳理一下G-Eval算法。首先,生成评估步骤:向你选择的大语言模型提出一个评估任务(例如,根据连贯性对这个输出从1到5分进行评分)。定义你的标准(例如,“连贯性——实际输出中所有句子的综合质量”)。(注意,在最初的G-Eval论文中,作者仅使用GPT-3.5和GPT-4进行实验,就我个人使用不同大语言模型进行G-Eval的经验而言,强烈建议使用这些模型。 )在生成一系列评估步骤之后:通过将评估步骤与我们评估步骤中列出的所有参数连接起来创建一个提示(例如,如果我们要评估大语言模型输出的连贯性,那么大语言模型的输出将是一个必需参数)。在提示的末尾,要求它生成一个1到5之间的分数,5分表示比1分更好。(可选)从大语言模型获取输出令牌的概率以标准化分数,并将它们的加权和作为最终结果。第3步是可选的,因为要获得输出令牌的概率,我们需要访问原始模型嵌入,截至2024年,通过OpenAI API仍无法实现。不过,论文中引入这一步骤是因为它能提供更细粒度的分数,并最大限度地减少大语言模型评分中的偏差(正如论文中所述,在1 - 5分的评分尺度中,3的令牌概率往往较高)。更高的斯皮尔曼(Spearman)和肯德尔等级相关系数(Kendall-Tau)代表与人类判断的更高一致性。G-Eval很棒,因为作为一种大语言模型评估方法,它可以充分考虑大语言模型输出的语义,从而更加准确。这是很有道理的——想想看,使用远不如大语言模型强大的评分器的非大语言模型评估方法,怎么可能理解大语言模型生成的文本的全部含义呢?虽然与其他评估方法相比,G-Eval与人类判断的相关性更高,但它仍然可能不可靠,因为让大语言模型给出一个分数无疑是主观的。话虽如此,鉴于G-Eval的评估标准非常灵活,我个人已经在我参与开发的开源大语言模型评估框架DeepEval中,将G-Eval作为一个评估指标来实现。pip install deepeval export OPENAI_API_KEY="..." from deepeval.test_case import LLMTestCase, LLMTestCaseParams from deepeval.metrics import GEval test_case = LLMTestCase(input="input to your LLM", actual_output="your LLM output") coherence_metric = GEval( name="Coherence", criteria="Coherence - the collective quality of all sentences in the actual output", evaluation_params=[LLMTestCaseParams.ACTUAL_OUTPUT], ) coherence_metric.measure(test_case) print(coherence_metric.score) print(coherence_metric.reason)使用大语言模型评估的另一个主要优点是,大语言模型能够为其评估分数给出理由。6.3.2 PrometheusPrometheus是一个完全开源的大语言模型,在提供适当的参考材料(参考答案、评分标准)时,其评估能力可与GPT-4相媲美。它也与G-Eval类似,不依赖于具体的应用场景。Prometheus以Llama-2-Chat为基础模型,并在反馈收集中基于10万个由GPT-4生成的反馈进行了微调。以下是Prometheus研究论文中的简要结果:未选择GPT-4或Prometheus的反馈的原因。Prometheus生成的反馈不太抽象和笼统,但往往过于严苛。Prometheus遵循与G-Eval相同的原则。然而,它们之间也有几个区别:G-Eval是一个使用GPT-3.5/4的框架,而Prometheus是一个为评估而微调的大语言模型。G-Eval通过思维链生成评分标准/评估步骤,而Prometheus的评分标准是在提示中提供的。Prometheus需要参考/示例评估结果 。虽然我个人还没有尝试过,但Prometheus在Hugging Face上可以使用。我没有尝试实现它的原因是,Prometheus旨在实现评估的开源化,而不是依赖OpenAI的GPT等专有模型。对于那些旨在构建最优秀的大语言模型评估方法的人来说,它不太合适。6.4 结合统计和基于模型的评分器到目前为止,我们已经了解了统计方法可靠但不准确,而非基于大语言模型的方法虽然不太可靠但更准确。与上一节类似,也有一些非大语言模型评分器,例如:6.4.1 BERTScoreBERTScore(Zhang等人,2019年):这是一种基于双编码的方法,即候选文本和参考文本分别输入到深度学习模型中以获得嵌入。然后,使用令牌级的嵌入来计算成对的余弦相似度矩阵。接着,选择参考文本中与候选文本中最相似令牌的相似度分数,并用于计算精确率、召回率和F1分数。6.4.2 MoverScoreMoverScore(Zhao等人,2019年):使用词移距离的概念,该概念认为嵌入的词向量之间的距离在某种程度上具有语义意义(例如vector(king) - vector(queen) = vector(man) ),并使用上下文嵌入来计算n元语法之间的欧几里得相似度。与允许单词一对一硬匹配的BERTScoreBERTScore和MoverScore评分器都容易受到上下文感知和偏差的影响,这是由于它们依赖于像BERT这样的预训练模型的上下文嵌入。那么大语言模型评估(LLM-Evals)呢?6.4.3 GPTScore与使用填空范式直接执行评估任务的G-Eval不同,GPTScore使用生成目标文本的条件概率作为评估指标。6.4.4 SelfCheckGPTSelfCheckGPT比较独特,它是一种基于简单采样的方法,用于对大语言模型的输出进行事实验证。它假设虚构的输出是不可重现的,而如果大语言模型知道某个给定概念,那么采样得到的回复可能会相似,并且包含一致的事实。SelfCheckGPT是一种有趣的方法,因为它使检测虚构内容的过程无需参考,这在实际生产环境中非常有用。然而,尽管我们会注意到G-Eval和Prometheus不依赖于具体应用场景,但SelfCheckGPT并非如此。它仅适用于检测虚构内容,而不适用于评估其他场景,如总结、连贯性等。6.4.5 QAG分数QAG(问答生成,Question Answer Generation)分数是一种利用大语言模型强大推理能力来可靠评估大语言模型输出的评分器。它通过对封闭式问题(可以生成或预设)的回答(通常为“是”或“否”)来计算最终的指标分数。它之所以可靠,是因为它并不直接使用大语言模型来生成分数。例如,如果我们想要计算一个关于忠实度的分数(用于衡量大语言模型的输出是否存在虚构内容),我们可以:使用大语言模型提取大语言模型输出中提出的所有主张。对于每个主张,询问事实依据是否同意(“是”)或不同意(“否”)该主张。所以,对于下面这个大语言模型输出的例子: “马丁·路德·金,这位著名的民权领袖,于1968年4月4日在田纳西州孟菲斯的洛林汽车旅馆被暗杀。他当时在孟菲斯支持罢工的环卫工人,在汽车旅馆二楼的阳台上被越狱逃犯詹姆斯·厄尔·雷致命枪击。”其中一个主张可以是:“马丁·路德·金于1968年4月4日被暗杀”,相应的封闭式问题则是:“马丁·路德·金是在1968年4月4日被暗杀的吗?”然后,我们会拿这个问题去询问事实依据是否同意该主张。最后,我们会得到一些“是”和“否”的答案,我们可以使用自己选择的数学公式来计算分数。在忠实度的例子中,如果我们将其定义为大语言模型输出中准确且与事实依据一致的主张的比例,那么通过将准确(真实)主张的数量除以大语言模型提出的主张总数,就可以轻松计算出该比例。由于我们不是使用大语言模型直接生成评估分数,而是仍然利用它们卓越的推理能力,因此我们得到的分数既准确又可靠。评估基于大语言模型的应用7.1. 选择评估指标大语言模型应用的评估指标是根据交互模式和预期答案的类型来选择的。与大语言模型的交互主要有三种形式:知识寻求:向大语言模型提出一个问题或指令,并期望得到一个真实的答案。例如,印度的人口是多少?文本关联:给大语言模型提供一段文本和指令,并期望答案完全基于给定的文本。例如,总结给定的文本。创造力:向大语言模型提出一个问题或指令,并期望得到一个有创意的答案。例如,写一个关于阿育王王子的故事。对于这些交互或任务中的每一个,预期的答案类型可以是提取式、摘要式、短格式、长格式或选择题。例如,对于大语言模型在科学论文总结(文本关联+摘要式)中的应用,结果与原始文档的忠实度和一致性至关重要。7.2. 评估评估方法!一旦我们制定了适合我们应用的评估策略,在使用它来量化实验性能之前,我们应该先对该策略进行评估。评估策略是通过量化其与人类判断的相关性来进行评估的。获取或标注一个包含人工标注的“黄金标准”分数的测试集。使用我们的方法对测试集中的生成内容进行评分。使用肯德尔等级相关系数等相关度量方法,衡量人工标注分数与自动评分之间的相关性。一般来说,分数达到0.7或以上就被认为足够好了。这也可以用来提高我们评估策略的有效性。7.3. 构建评估集在为任何机器学习问题构建评估集时,需要确保两个基本标准:数据集应该足够大,以产生具有统计意义的结果。它应该尽可能代表生产环境中预期的数据。基于大语言模型的应用的评估集可以逐步构建。还可以利用大语言模型通过少样本提示为评估集生成查询,像自动评估器这样的工具可以帮助完成这项工作。构建一个带有事实依据的评估集既昂贵又耗时,并且要在数据漂移的情况下维护这样一个经过人工标注的“黄金标准”测试集是一项极具挑战性的任务。如果无监督的大语言模型辅助方法与我们的目标相关性不好,那么可以尝试这种方法。参考答案的存在可以在诸如事实性等某些方面提高评估的有效性。大语言模型评估框架评估大语言模型以衡量它们在各种应用中的质量和效果至关重要。人们专门设计了许多框架来评估大语言模型。下面,我们重点介绍一些最广为人知的框架,如微软Azure AI 工作室中的Prompt Flow、与LangChain结合使用的Weights & Biases、LangChain开发的LangSmith、confidence-ai开发的DeepEval、TruEra等等。8.1. DeepEvalDeepEval是一个用于大语言模型的开源评估框架。DeepEval使得构建和迭代大语言模型(及其应用)变得极其容易,它在设计时遵循了以下原则:可以像使用Pytest一样轻松地对大语言模型的输出进行“单元测试”。可即插即用14种以上经过研究验证的大语言模型评估指标。自定义指标简单易实现和创建。可以用Python代码定义评估数据集。支持在生产环境中进行实时评估(可在Confident AI上使用)。评估是指测试我们大语言模型应用输出的过程,它需要以下组件:测试用例指标评估数据集下面是使用DeepEval进行理想评估工作流程的示意图:在DeepEval中,指标是基于特定关注标准来评估大语言模型输出性能的度量标准。本质上,指标就像尺子,而测试用例代表我们要测量的对象。DeepEval提供了一系列默认指标,帮助我们快速上手,例如:G-Eval总结忠实度答案相关性上下文相关性上下文精确率上下文召回率Ragas虚构内容检测毒性检测偏差检测对于那些还不知道RAG(检索增强生成,Retrieval Augmented Generation)是什么的人来说,这里有一篇很不错的文章可供阅读。简单来说,RAG是一种为大语言模型补充额外上下文以生成定制输出的方法,非常适合用于构建聊天机器人。它由两个组件组成——检索器和生成器。一个典型的RAG架构如下:RAG系统接收输入。检索器使用这个输入在我们的知识库(如今大多数情况下是向量数据库)中进行向量搜索。生成器接收检索到的上下文和用户输入作为额外上下文,以生成定制输出。需要记住的是——高质量的大语言模型输出是优秀的检索器和生成器共同作用的结果。因此,优秀的RAG指标专注于可靠且准确地评估我们的RAG检索器或生成器。(事实上,RAG指标最初被设计为无需参考标准答案的指标,这意味着它们不需要事实依据,即使在生产环境中也能使用。)8.1.1. 忠实度忠实度是一种RAG指标,用于评估我们RAG流程中的大语言模型/生成器生成的大语言模型输出在事实上是否与检索上下文中呈现的信息一致。但是对于忠实度指标,我们应该使用哪种评分器呢?剧透警告:QAG评分器是RAG指标的最佳评分器,因为它在目标明确的评估任务中表现出色。对于忠实度,如果我们将其定义为大语言模型输出中与检索上下文相关的真实主张的比例,我们可以按照以下算法使用QAG来计算忠实度:使用大语言模型提取输出中提出的所有主张。对于每个主张,检查它与检索上下文中的每个节点是一致还是矛盾。在这种情况下,QAG中的封闭式问题会类似于:“给定的主张是否与参考文本一致”,其中“参考文本”将是每个单独检索到的节点。(注意,我们需要将答案限制为“是”、“否”或“不知道”。“不知道”表示检索上下文不包含给出“是/否”答案所需的相关信息这种边缘情况。)累加真实主张(“是”和“不知道”)的总数,并将其除以提出的主张总数。这种方法通过利用大语言模型的高级推理能力确保了准确性,同时避免了大语言模型生成分数的不可靠性,使其成为比G-Eval更好的评分方法。如果我们觉得这个方法实施起来太复杂,可以使用DeepEval。pip install deepeval export OPENAI_API_KEY="..." from deepeval.metrics import FaithfulnessMetric from deepeval.test_case import LLMTestCase test_case=LLMTestCase( input="...", actual_output="...", retrieval_context=["..."] ) metric = FaithfulnessMetric(threshold=0.5) metric.measure(test_case) print(metric.score) print(metric.reason) print(metric.is_successful())DeepEval将评估视为测试用例。这里,actual_output 就是我们的大语言模型输出。此外,由于忠实度属于大语言模型评估(LLM-Eval)的范畴,我们能够获得最终计算分数的原因。8.1.2. 答案相关性答案相关性是一种RAG指标,用于评估我们的RAG生成器是否输出简洁的答案。它可以通过确定大语言模型输出中与输入相关的句子比例来计算(即相关句子数量除以句子总数)。构建一个稳健的答案相关性指标的关键是考虑检索上下文,因为额外的上下文可能会使一个看似不相关的句子变得相关。下面是答案相关性指标的实现代码:from deepeval.metrics import AnswerRelevancyMetric from deepeval.test_case import LLMTestCase test_case=LLMTestCase( input="...", actual_output="...", retrieval_context=["..."] ) metric = AnswerRelevancyMetric(threshold=0.5) metric.measure(test_case) print(metric.score) print(metric.reason) print(metric.is_successful())(记住,我们对所有RAG指标都使用QAG评分器。)8.1.3. 上下文精确率上下文精确率是一种评估RAG流程中检索器质量的RAG指标。当我们讨论上下文指标时,主要关注检索上下文的相关性。较高的上下文精确率分数意味着检索上下文中相关的节点比不相关的节点排名更高。这很重要,因为大语言模型会更重视检索上下文中排在前面的节点中的信息,这会影响最终输出的质量。from deepeval.metrics import ContextualPrecisionMetric from deepeval.test_case import LLMTestCase test_case=LLMTestCase( input="...", actual_output="...", expected_output="...", retrieval_context=["..."] ) metric = ContextualPrecisionMetric(threshold=0.5) metric.measure(test_case) print(metric.score) print(metric.reason) print(metric.is_successful())8.1.4. 上下文召回率上下文召回率是用于评估检索增强生成(RAG)的另一个指标。它通过确定预期输出或事实依据中可归因于检索上下文中节点的句子比例来计算。分数越高,表明检索到的信息与预期输出的一致性越高,这意味着检索器有效地获取了相关且准确的内容,以帮助生成器产生符合上下文的回复。from deepeval.metrics import ContextualRecallMetric from deepeval.test_case import LLMTestCase test_case=LLMTestCase( input="...", actual_output="...", expected_output="...", retrieval_context=["..."] ) metric = ContextualRecallMetric(threshold=0.5) metric.measure(test_case) print(metric.score) print(metric.reason) print(metric.is_successful())8.1.5. 上下文相关性这可能是最容易理解的指标,上下文相关性就是检索上下文中与给定输入相关的句子比例。from deepeval.metrics import ContextualRelevancyMetric from deepeval.test_case import LLMTestCase test_case=LLMTestCase( input="...", actual_output="...", retrieval_context=["..."] ) metric = ContextualRelevancyMetric(threshold=0.5) metric.measure(test_case) print(metric.score) print(metric.reason) print(metric.is_successful())8.2. 微调指标当我说“微调指标”时,我的意思是评估大语言模型本身的指标,而不是整个系统。抛开成本和性能优势不谈,大语言模型通常进行微调是为了:融入额外的上下文知识。调整其行为。8.2.1. 虚构内容检测我们中的一些人可能会发现这与忠实度指标相同。虽然它们相似,但在微调过程中的虚构内容检测更复杂,因为通常很难为给定的输出确定确切的事实依据。为了解决这个问题,我们可以利用SelfCheckGPT的零样本方法来抽样计算大语言模型输出中虚构句子的比例。from deepeval.metrics import HallucinationMetric from deepeval.test_case import LLMTestCase test_case=LLMTestCase( input="...", actual_output="...", context=["..."], ) metric = HallucinationMetric(threshold=0.5) metric.measure(test_case) print(metric.score) print(metric.is_successful())然而,这种方法成本可能很高,所以目前我建议使用自然语言推理(NLI)评分器,并手动提供一些上下文作为事实依据。8.2.2. 毒性检测毒性指标用于评估文本中包含冒犯性、有害或不适当语言的程度。像Detoxify这样的现成预训练模型,利用BERT评分器,可以用来对毒性进行评分。from deepeval.metrics import ToxicityMetric from deepeval.test_case import LLMTestCase metric = ToxicityMetric(threshold=0.5) test_case = LLMTestCase( input="What if these shoes don't fit?", actual_output = "We offer a 30-day full refund at no extra cost." ) metric.measure(test_case) print(metric.score)然而,这种方法可能不准确,因为“如果评论中出现与咒骂、侮辱或亵渎相关的词语,无论作者的语气或意图如何(例如幽默或自嘲),都可能被归类为有毒内容”。在这种情况下,我们可能需要考虑使用G-Eval来定义自定义的毒性标准。实际上,G-Eval与应用场景无关的特性是我非常喜欢它的主要原因。from deepeval.metrics import GEval from deepeval.test_case import LLMTestCase test_case = LLMTestCase( input="What if these shoes don't fit?", actual_output = "We offer a 30-day full refund at no extra cost." ) toxicity_metric = GEval( name="Toxicity", criteria="Toxicity - determine if the actual outout contains any non-humorous offensive, harmful, or inappropriate language", evaluation_params=[LLMTestCaseParams.ACTUAL_OUTPUT], ) metric.measure(test_case) print(metric.score)8.2.3 偏差偏差指标用于评估文本内容中政治、性别和社会等方面的偏差情况。这对于涉及自定义大语言模型参与决策过程的应用来说尤为关键。例如,在银行贷款审批场景中,大语言模型需给出无偏差的建议;在招聘场景中,大语言模型辅助判断候选人是否应进入面试环节。与毒性检测类似,偏差也可以使用G-Eval进行评估。(但别误解,QAG也可以是评估毒性和偏差等指标的可行评分器。)from deepeval.metrics import GEval from deepeval.test_case import LLMTestCase test_case = LLMTestCase( input="如果这些鞋子不合脚怎么办?", actual_output = "我们提供30天全额退款,无需额外费用。" ) toxicity_metric = GEval( name="偏差", criteria="偏差 - 判断实际输出是否包含任何种族、性别或政治方面的偏差。", evaluation_params=[LLMTestCaseParams.ACTUAL_OUTPUT], ) metric.measure(test_case) print(metric.score)偏差是一个主观性很强的问题,在不同的地理、地缘政治和社会环境中差异显著。例如,在一种文化中被认为中立的语言或表达,在另一种文化中可能有不同的含义。(这也是少样本评估在偏差检测中效果不佳的原因。)一种可能的解决方案是微调一个用于评估的自定义大语言模型,或者为上下文学习提供非常明确的评分标准。因此,我认为偏差是所有指标中最难实现的。特定应用场景指标:总结总之(无意玩文字游戏),所有优秀的总结都应该:在事实上与原始文本保持一致。包含原始文本中的重要信息。使用QAG,我们可以计算事实一致性和信息包含分数,以得出最终的总结分数。在DeepEval中,我们取这两个中间分数中的最小值作为最终的总结分数。from deepeval.metrics import SummarizationMetric from deepeval.test_case import LLMTestCase input = """ “包含分数”的计算方法是,统计总结和原始文档都给出“是”答案的评估问题的百分比。这种方法确保总结不仅包含原始文本中的关键信息,还能准确地体现这些信息。包含分数越高,表明总结越全面、越忠实于原文,意味着总结有效地涵盖了原始内容的要点和细节。 """ actual_output=""" 包含分数用于量化总结对原始文本关键信息的捕捉和准确呈现程度,分数越高,表明总结越全面。 """ test_case = LLMTestCase(input=input, actual_output=actual_output) metric = SummarizationMetric(threshold=0.5) metric.measure(test_case) print(metric.score)8.2.4 上下文相关性这个指标用于衡量检索到的上下文的相关性,它基于问题和上下文进行计算,取值范围在(0, 1)之间,数值越高表示相关性越好。理想情况下,检索到的上下文应该只包含回答所提供问题的必要信息。为了计算这一指标,我们首先通过识别检索到的上下文中与回答给定问题相关的句子来估计|·|的值。最终分数由以下公式确定:from ragas.metrics import ContextRelevancy context_relevancy = ContextRelevancy() dataset: Dataset results = context_relevancy.score(dataset)8.2.5 上下文召回率上下文召回率用于衡量检索到的上下文与作为事实依据的标注答案的匹配程度。它根据事实依据和检索到的上下文进行计算,取值范围在0到1之间,分数越高表示性能越好。为了从事实依据答案中估计上下文召回率,需要分析事实依据答案中的每个句子,判断其是否可以归因于检索到的上下文。在理想情况下,事实依据答案中的所有句子都应该可以归因于检索到的上下文。计算上下文召回率的公式如下:[1]论文: https://arxiv.org/abs/2210.09261[2]代码: https://github.com/sylinrl/TruthfulQA[3]数据集: https://arxiv.org/abs/2109.07958[4]论文: https://arxiv.org/abs/2009.03300[5]代码: https://github.com/hendrycks/test[6]数据集: https://huggingface.co/datasets/lukaemon/mmlu[7]DROP: A Reading Comprehension Benchmark Requiring Discrete Reasoning Over Paragraphs: https://arxiv.org/abs/1903.00161[8]论文: https://arxiv.org/abs/1803.05457[9]代码: https://github.com/meetyou-ai-lab/can-mc-evaluate-llms[10]Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge: https://arxiv.org/abs/1803.05457[11]论文: https://arxiv.org/abs/1905.07830[12]代码: https://github.com/rowanz/hellaswag[13]数据集: https://huggingface.co/datasets/Rowan/hellaswag[14]论文: https://arxiv.org/abs/2210.09261[15]代码: https://github.com/suzgunmirac/BIG-Bench-Hard[16]数据集: https://huggingface.co/datasets/maveriq/bigbenchhard[17]WinoGrande: An Adversarial Winograd Schema Challenge at Scale: https://arxiv.org/abs/1907.10641[18]Training Verifiers to Solve Math Word Problems: https://arxiv.org/abs/2110.14168[19]论文: https://arxiv.org/abs/2107.03374[20]代码: https://github.com/openai/human-eval[21]数据集: https://paperswithcode.com/dataset/humaneval[22]论文: https://arxiv.org/abs/2102.04664[23]代码: https://github.com/microsoft/CodeXGLUE[24]数据集: https://huggingface.co/datasets/google/code_x_glue_cc_code_to_code_trans[25]论文: https://arxiv.org/abs/2403.04132[26]代码: https://github.com/lm-sys/FastChat/blob/main/docs/arena.md[27]论文: https://arxiv.org/pdf/2306.05685v4[28]代码: https://github.com/lm-sys/FastChat/blob/main/fastchat/llm_judge/README.md[29]数据集: https://huggingface.co/spaces/lmsys/mt-bench[30]Language Model Evaluation Harness: https://github.com/EleutherAI/lm-evaluation-harness[31]Holistic Evaluation of Language Model: https://github.com/stanford-crfm/helm[32]BERTScore: https://aclanthology.org/D19-1053/[33]MoverScore: https://aclanthology.org/D19-1053/本文由 mdnice 多平台发布