搜索到
378
篇与
的结果
-
 AI专题十七:一个AI算力板块上多颗chiplet之间的chip-to-chip连接 1 H100 板卡NVIDIA H100 实际上采用的是单一大芯片(Monolithic)设计,而非 Chiplet/MCM 多芯片设计。项目规格GPU 型号GH100(Hopper 架构)制造工艺台积电 4N 定制工艺晶体管数量800 亿Die 尺寸814 mm²架构类型单一大芯片(Monolithic),非 Chiplet所以NVIDIA H100 GPU板卡没有多颗算力芯片的chiplet 的 chip-to-chip连接2 一个AI算力版本上集成多颗算力chiplet 的方案AMD MI300X 架构详解板卡上的 Chiplet 组成组件数量工艺节点功能XCD (Accelerator Complex Die)8 颗台积电 5nmGPU 计算芯粒,每颗含 38 个 CUIOD (I/O Die)4 颗台积电 6nmI/O 芯粒,含内存控制器、Infinity Fabric 网络HBM3 堆栈8 颗-每颗 24GB,共 192GBNVIDIA Blackwell (B100/B200) 架构详解板卡上的 Chiplet 组成组件数量工艺节点功能GPU Compute Die2 颗台积电 4NP计算芯粒,每颗约 1040 亿晶体管HBM3e 堆栈8 颗-每颗 24GB,共 192GB双 Die 互连结构Blackwell 采用 NV-HBI(NV-High Bandwidth Interface) 连接两颗计算芯粒┌─────────────────┐ NV-HBI (10 TB/s) ┌─────────────────┐ │ GPU Die 0 │ ←────────────────────→ │ GPU Die 1 │ │ (104B 晶体管) │ 芯片间高带宽接口 │ (104B 晶体管) │ │ │ │ │ │ 80 SM (第5代) │ │ 80 SM (第5代) │ │ 5 颗 HBM3e │ │ 3 颗 HBM3e │ └─────────────────┘ └─────────────────┘ ↓ ↓ ┌─────────────────────────────────────────────────────┐ │ TSMC CoWoS-L 硅中介层 │ │ (Local Silicon Interconnect 技术) │ └─────────────────────────────────────────────────────┘两颗 reticle-limited dies(约 800mm² 每颗)通过 NV-HBI 以 10 TB/s 速率连接 szwecent.com• 采用 TSMC CoWoS-L 封装技术(带 LSI 芯片的 RDL 中介层)EnosTech.com• 对外呈现为 单一统一 GPU(逻辑上不是双 GPU)上面两个GPU 板块对比特性AMD MI300XNVIDIA B100/B200Chiplet 数量12 颗(8 XCD + 4 IOD)2 颗 GPU Die每个 Chiplet 内部 Die 数XCD: 1 颗 DieIOD: 1 颗 Die每颗 GPU Die: 1 颗大 Die堆叠方式3.5D(3D SoIC + 2.5D CoWoS)2.5D CoWoS-L(双 Die 平铺)内部互连技术Infinity Fabric APNV-HBI (10 TB/s)外部互连技术Infinity Fabric (896 GB/s)NVLink 5.0 (1.8 TB/s)计算单元304 CU (8×38)160 SM (2×80)内存容量192 GB HBM3192 GB HBM3e总晶体管数~1530 亿2080 亿3 一个AI算力板块上多颗chiplet之间的chip-to-chip连接互联技术带宽(双向,典型配置)延迟(链路延迟,典型场景)能效(每字节传输能耗/相对值)一致性支持PHY面积(相对PCIe Gen5,同工艺)关键备注NVLink C2C(4.0)单链路900GB/s;多链路可聚合(如Grace Hopper平台)亚纳秒级(<1ns,封装内芯片间)1.3皮焦/字节;相对PCIe Gen5提升25倍支持全缓存一致性,兼容AMBA CHI协议10%(面积效率提升90%)专为芯片级短距互联设计,依赖先进封装(MCM/硅中介层)PCIe Gen5x16链路:128GB/s(单通道32GT/s,NRZ调制)15-30ns(板级设备间)相对NVLink C2C低25倍;典型每字节能耗~32.5皮焦不支持原生缓存一致性,需上层协议扩展100%(基准值)通用I/O互联,生态成熟,适用于板级外设连接PCIe Gen6x16链路:256GB/s(单通道64GT/s,PAM4调制)<10ns(板级设备间,FLIT模式)相对PCIe Gen5提升50%;每字节能耗~21.7皮焦不支持原生缓存一致性110%-120%(引入FEC和PAM4,面积略有增加)兼容前代PCIe设备,支持动态FLIT/TLP模式切换CCIX 1.1x16链路:100GB/s(单通道25Gbps,NRZ);扩展模式可达更高10-20ns(板级CPU-加速器间)相对PCIe Gen5提升2-3倍;每字节能耗~10-16皮焦支持全缓存一致性,基于AMBA CHI协议演进95%-105%(基于PCIe物理层,面积相近)专为异构计算设计,优化CPU与加速器互联CXL 3.0x16链路:256GB/s(单通道64GT/s,PAM4,兼容PCIe 6.0)3-8ns(板级设备间,优化后)相对PCIe Gen5提升3-4倍;功耗密度2.8W/cm²支持全缓存一致性(CXL.cache/CXL.mem模式)80%-90%(复用PCIe PHY,协议层优化压缩面积)开放生态,兼容PCIe基础设施,适用于内存扩展与加速器互联Nvlink-C2CNVLink-C2C技术也可用于连接同一块PCB主板或同一台服务器内、不同封装的两个独立芯片。技术实现:通过芯片边缘的NVLink SerDes物理层接口,经由主板上的高速走线或连接器进行连接。1特点:这种连接距离比封装内远,但仍远优于传统PCIe,用于构建多芯片、多节点的紧密耦合系统。例如,可以将多个集成了NVLink-C2C IP的定制加速器芯片在板级互联。NVLink C2C的核心价值是打破单芯片性能瓶颈,实现多芯片(如CPU+GPU、CPU+CPU)在同一封装内的“超级芯片”级整合:AMD IF这是在同一块物理加速卡内部,连接多个GPU计算芯片(GCD)的桥梁。作用:让一块物理GPU卡内的多个计算芯片(例如MI250X包含2个GCD)能够像单个逻辑GPU一样协同工作,共享内存一致性域。示例:AMD Instinct MI250X:一块双芯GPU卡,其内部的两个图形计算芯片(GCD)就是通过极高带宽的Infinity Fabric链路(四向链路,双向带宽约200GB/s) 直接互联的。这是它实现高计算密度和内存一致性的基础。特点:带宽远高于传统的PCIe,是实现单卡内多芯片高效协同的关键。PCIE (包括PCIE GEN5 、PCIE GEN6)PCIe可以用于同一封装内Chiplet之间的通信,但这并非其最优或主要设计场景。其应用受到物理特性和协议开销的限制,主要出现在特定过渡或兼容场景中。主要特点与限制并非原生设计:PCIe协议设计初衷是板级或设备间通信,其物理层和协议栈包含了应对较长距离、信号完整性问题以及系统枚举的额外开销。高延迟与较大功耗:由于上述协议开销,在极短距离的Chip-to-Chip互连中,PCIe的延迟和功耗显著高于UCIe、AIB、BoW等专为Chiplet设计的互连标准。封装技术要求高:为了实现Chiplet间通信,需要将PCIe的SerDes(串行器/解串器)电路集成到每个Chiplet中,并在封装内布线,这对封装设计和信号完整性提出了挑战。主要应用场景尽管非最优,PCIe在Chiplet场景中仍有其应用价值,主要集中在以下方面:早期集成与原型验证在专用Chiplet互连标准(如UCIe)成熟和普及之前,或在对峰值带宽和极致延迟要求不高的场景中,开发团队可能选择使用成熟的PCIe IP进行Chiplet间的初步集成和功能验证,以缩短开发周期。2异构扩展与桥接当需要将一个基于PCIe设计的功能模块(例如,一个已验证的IP核、第三方IP或遗留设计)以Chiplet形式集成到先进封装中时,使用PCIe接口可以最大程度地避免对该模块内部架构的重新设计,实现“即插即用”。这常见于某些I/O、控制器或加速器Chiplet。2作为上层协议载体更常见且重要的应用方式是,物理层采用更高效的Chiplet互连标准(如UCIe),而在协议层运行PCIe。UCIe标准原生支持PCIe作为其上层协议之一。在这种架构下,Chiplet间享受了高带宽、低延迟的物理连接,同时在软件层面呈现为标准的PCIe设备,继承了PCIe完善的生态、驱动和操作系统支持。168系统级互联的补充在包含多个Chiplet的复杂封装中,可能同时存在多种互连。例如,计算核心与缓存之间采用超低延迟的专用总线,而与通用I/O Chiplet或外部内存控制器之间则可能采用PCIe,以满足不同的带宽、延迟和功能隔离需求。PCIE CCIXCCIX(缓存一致性互联协议)是一个旨在为CPU与加速器之间提供高性能、缓存一致互连的协议标准。它的核心目标是通过引入缓存一致性机制,简化异构系统的数据共享,降低时延,提升带宽。1CCIX的分层架构组成CCIX采用了分层架构设计,可以分为协议规范和传输规范两部分。CCIX协议规范:包含协议层和链路层,负责定义缓存一致性协议、消息格式、流量控制等。CCIX传输规范:包含事务层(CCIX和PCIe事务层)、数据链路层(PCIe数据链路层)和物理层(CCIX物理层),负责具体的数据包传输、错误校验和物理连接。23CCIX物理层的两种实现方式CCIX并非独立的物理接口,而是在物理层上兼容或扩展现有的高速互连标准。兼容PCIe PHY:CCIX规范要求设备必须支持两种物理层之一。一种是PCIe PHY,即完全使用PCIe标准的物理层和电气接口。这使得CCIX可以无缝运行在标准的PCIe插槽和链路上。扩展EDR PHY:另一种是CCIX EDR PHY。这是一种扩展模式,在原PCIe物理层基础上提升数据速率,支持20GT/s和25GT/s,以提供更高的原始带宽。CCIX与PCIe的关系和优势CCIX在设计上深度依赖于PCIe的成熟基础设施,并对其进行了功能扩展。协议层面复用与扩展:CCIX构建在PCIe的数据链路层之上,定义了自身的协议层和事务层,以支持缓存一致性。它既可以传输标准的PCIe数据包,也可以传输为一致性操作优化的、开销更小的CCIX包。35物理层面兼容与提速:CCIX可以在标准的PCIe物理层上运行,从而利用现有庞大的PCIe生态。同时,它又通过EDR模式提供了高于PCIe 4.0原生16GT/s的速率选项CCIX协议未被正式纳入PCIe Gen5或Gen6的核心规范,它作为一个独立的互联协议,通过复用PCIe物理层来实现高速互连。CIX没有“成为”PCIe规范的一部分,而是作为一种能够运行在PCIe物理通道上的、附加的协议层存在。它需要系统中的芯片(如CPU、加速器)专门集成CCIX控制器(即CCIX协议栈)才能启用。PCIE CXLCXL是一种独立的逻辑协议CXL(Compute Express Link)是一种开放标准的行业协议(即逻辑规范和数据通信规则),而非物理接口的硬件定义。它定义了主机处理器与加速器、内存扩展设备等之间进行高带宽、低延迟通信时所需的链路层、传输层及事务层协议,特别是强调了缓存一致性内存访问的语义。27CXL复用PCIe的物理层接口CXL协议在物理层完全复用并依赖于PCIe(特别是Gen 5及以上版本)的物理电气接口。这意味着CXL设备使用与PCIe设备相同的连接器、线缆和电气信号标准进行物理连接和数据传输。CXL利用PCIe的这种成熟物理基础来实现高速互连,从而简化了硬件设计和产业推广。125CXL并非PCIe协议的一部分CXL是一个与PCIe并行发展、相互协作但独立的协议。它没有成为PCIe协议的一部分。具体表现为:协议栈独立:CXL拥有自己独特的链路层和传输层协议(如CXL.cache, CXL.mem),这些协议在通过PCIe物理层传输前,会与CXL.io协议动态复用。35组织独立:CXL由独立的CXL联盟制定和维护,而PCIe则由PCI-SIG组织管理。两者是不同的行业标准机构。2兼容与共存:CXL设备可通过PCIe的Flex Bus接口兼容连接。如果主机或设备不支持CXL,链接将降级为标准的PCIe操作模式,这表明两者是共存而非融合的关系Unified BUSUnified BUS 也可用于C2C灵衢定义为面向超节点(SuperPoD) 的统一互联协议,旨在将 I/O、内存访问、异构计算单元(CPU/NPU/GPU等)之间的通信融合到同一技术体系中,实现高性能、高协同、高弹性的计算基础设施。UCIEUCIE 也可以用于C2CUCIe规范采用分层架构方法,在保持高性能的同时最大化灵活性和互操作性。在基础层面,物理层在电气层面处理芯间I/O,实现链路训练、通道修复/反转、扰码、模拟前端功能、时钟、侧带通信和配置寄存器。该层还定义通道要求并确保符合电气规范。物理层设计为适应不同的封装技术,同时保持一致的性能特性。中间层,称为芯间适配器,作为可靠性层负责确保可靠的数据传输。当使用多个协议时,实现仲裁和多路复用,处理CRC/重试机制进行错误检测和纠正,管理链路状态转换,并支持连接设备之间的参数协商。适配器维护可访问高级功能的配置寄存器,在原始模式下可完全绕过,用于需要直接访问物理层的专用应用。这种灵活性允许标准化和定制实现在UCIe框架内共存。在堆栈顶部,协议层支持多种接口类型,以适应多样化的使用模型。主要支持的协议是CXL/PCIe,适用于需要标准化"即插即用"功能的大量应用,如I/O附件、内存接口和加速器。这些协议利用现有软件生态系统,实现与当前系统架构的无缝集成。对于更专业的应用,UCIe还支持流式接口,可容纳AXI、CHI、SFI和CPI等专有协议。这种流式方法对于从较小芯片构建更大计算单元的扩展场景特别有价值,例如由多个较小元素组成的CPU、GPU和网络交换机。完整规范涵盖从物理凸点/键合焊盘层到形状因素定义的互连,为跨不同封装技术和应用领域的Chiplet集成创建了全面框架。
AI专题十七:一个AI算力板块上多颗chiplet之间的chip-to-chip连接 1 H100 板卡NVIDIA H100 实际上采用的是单一大芯片(Monolithic)设计,而非 Chiplet/MCM 多芯片设计。项目规格GPU 型号GH100(Hopper 架构)制造工艺台积电 4N 定制工艺晶体管数量800 亿Die 尺寸814 mm²架构类型单一大芯片(Monolithic),非 Chiplet所以NVIDIA H100 GPU板卡没有多颗算力芯片的chiplet 的 chip-to-chip连接2 一个AI算力版本上集成多颗算力chiplet 的方案AMD MI300X 架构详解板卡上的 Chiplet 组成组件数量工艺节点功能XCD (Accelerator Complex Die)8 颗台积电 5nmGPU 计算芯粒,每颗含 38 个 CUIOD (I/O Die)4 颗台积电 6nmI/O 芯粒,含内存控制器、Infinity Fabric 网络HBM3 堆栈8 颗-每颗 24GB,共 192GBNVIDIA Blackwell (B100/B200) 架构详解板卡上的 Chiplet 组成组件数量工艺节点功能GPU Compute Die2 颗台积电 4NP计算芯粒,每颗约 1040 亿晶体管HBM3e 堆栈8 颗-每颗 24GB,共 192GB双 Die 互连结构Blackwell 采用 NV-HBI(NV-High Bandwidth Interface) 连接两颗计算芯粒┌─────────────────┐ NV-HBI (10 TB/s) ┌─────────────────┐ │ GPU Die 0 │ ←────────────────────→ │ GPU Die 1 │ │ (104B 晶体管) │ 芯片间高带宽接口 │ (104B 晶体管) │ │ │ │ │ │ 80 SM (第5代) │ │ 80 SM (第5代) │ │ 5 颗 HBM3e │ │ 3 颗 HBM3e │ └─────────────────┘ └─────────────────┘ ↓ ↓ ┌─────────────────────────────────────────────────────┐ │ TSMC CoWoS-L 硅中介层 │ │ (Local Silicon Interconnect 技术) │ └─────────────────────────────────────────────────────┘两颗 reticle-limited dies(约 800mm² 每颗)通过 NV-HBI 以 10 TB/s 速率连接 szwecent.com• 采用 TSMC CoWoS-L 封装技术(带 LSI 芯片的 RDL 中介层)EnosTech.com• 对外呈现为 单一统一 GPU(逻辑上不是双 GPU)上面两个GPU 板块对比特性AMD MI300XNVIDIA B100/B200Chiplet 数量12 颗(8 XCD + 4 IOD)2 颗 GPU Die每个 Chiplet 内部 Die 数XCD: 1 颗 DieIOD: 1 颗 Die每颗 GPU Die: 1 颗大 Die堆叠方式3.5D(3D SoIC + 2.5D CoWoS)2.5D CoWoS-L(双 Die 平铺)内部互连技术Infinity Fabric APNV-HBI (10 TB/s)外部互连技术Infinity Fabric (896 GB/s)NVLink 5.0 (1.8 TB/s)计算单元304 CU (8×38)160 SM (2×80)内存容量192 GB HBM3192 GB HBM3e总晶体管数~1530 亿2080 亿3 一个AI算力板块上多颗chiplet之间的chip-to-chip连接互联技术带宽(双向,典型配置)延迟(链路延迟,典型场景)能效(每字节传输能耗/相对值)一致性支持PHY面积(相对PCIe Gen5,同工艺)关键备注NVLink C2C(4.0)单链路900GB/s;多链路可聚合(如Grace Hopper平台)亚纳秒级(<1ns,封装内芯片间)1.3皮焦/字节;相对PCIe Gen5提升25倍支持全缓存一致性,兼容AMBA CHI协议10%(面积效率提升90%)专为芯片级短距互联设计,依赖先进封装(MCM/硅中介层)PCIe Gen5x16链路:128GB/s(单通道32GT/s,NRZ调制)15-30ns(板级设备间)相对NVLink C2C低25倍;典型每字节能耗~32.5皮焦不支持原生缓存一致性,需上层协议扩展100%(基准值)通用I/O互联,生态成熟,适用于板级外设连接PCIe Gen6x16链路:256GB/s(单通道64GT/s,PAM4调制)<10ns(板级设备间,FLIT模式)相对PCIe Gen5提升50%;每字节能耗~21.7皮焦不支持原生缓存一致性110%-120%(引入FEC和PAM4,面积略有增加)兼容前代PCIe设备,支持动态FLIT/TLP模式切换CCIX 1.1x16链路:100GB/s(单通道25Gbps,NRZ);扩展模式可达更高10-20ns(板级CPU-加速器间)相对PCIe Gen5提升2-3倍;每字节能耗~10-16皮焦支持全缓存一致性,基于AMBA CHI协议演进95%-105%(基于PCIe物理层,面积相近)专为异构计算设计,优化CPU与加速器互联CXL 3.0x16链路:256GB/s(单通道64GT/s,PAM4,兼容PCIe 6.0)3-8ns(板级设备间,优化后)相对PCIe Gen5提升3-4倍;功耗密度2.8W/cm²支持全缓存一致性(CXL.cache/CXL.mem模式)80%-90%(复用PCIe PHY,协议层优化压缩面积)开放生态,兼容PCIe基础设施,适用于内存扩展与加速器互联Nvlink-C2CNVLink-C2C技术也可用于连接同一块PCB主板或同一台服务器内、不同封装的两个独立芯片。技术实现:通过芯片边缘的NVLink SerDes物理层接口,经由主板上的高速走线或连接器进行连接。1特点:这种连接距离比封装内远,但仍远优于传统PCIe,用于构建多芯片、多节点的紧密耦合系统。例如,可以将多个集成了NVLink-C2C IP的定制加速器芯片在板级互联。NVLink C2C的核心价值是打破单芯片性能瓶颈,实现多芯片(如CPU+GPU、CPU+CPU)在同一封装内的“超级芯片”级整合:AMD IF这是在同一块物理加速卡内部,连接多个GPU计算芯片(GCD)的桥梁。作用:让一块物理GPU卡内的多个计算芯片(例如MI250X包含2个GCD)能够像单个逻辑GPU一样协同工作,共享内存一致性域。示例:AMD Instinct MI250X:一块双芯GPU卡,其内部的两个图形计算芯片(GCD)就是通过极高带宽的Infinity Fabric链路(四向链路,双向带宽约200GB/s) 直接互联的。这是它实现高计算密度和内存一致性的基础。特点:带宽远高于传统的PCIe,是实现单卡内多芯片高效协同的关键。PCIE (包括PCIE GEN5 、PCIE GEN6)PCIe可以用于同一封装内Chiplet之间的通信,但这并非其最优或主要设计场景。其应用受到物理特性和协议开销的限制,主要出现在特定过渡或兼容场景中。主要特点与限制并非原生设计:PCIe协议设计初衷是板级或设备间通信,其物理层和协议栈包含了应对较长距离、信号完整性问题以及系统枚举的额外开销。高延迟与较大功耗:由于上述协议开销,在极短距离的Chip-to-Chip互连中,PCIe的延迟和功耗显著高于UCIe、AIB、BoW等专为Chiplet设计的互连标准。封装技术要求高:为了实现Chiplet间通信,需要将PCIe的SerDes(串行器/解串器)电路集成到每个Chiplet中,并在封装内布线,这对封装设计和信号完整性提出了挑战。主要应用场景尽管非最优,PCIe在Chiplet场景中仍有其应用价值,主要集中在以下方面:早期集成与原型验证在专用Chiplet互连标准(如UCIe)成熟和普及之前,或在对峰值带宽和极致延迟要求不高的场景中,开发团队可能选择使用成熟的PCIe IP进行Chiplet间的初步集成和功能验证,以缩短开发周期。2异构扩展与桥接当需要将一个基于PCIe设计的功能模块(例如,一个已验证的IP核、第三方IP或遗留设计)以Chiplet形式集成到先进封装中时,使用PCIe接口可以最大程度地避免对该模块内部架构的重新设计,实现“即插即用”。这常见于某些I/O、控制器或加速器Chiplet。2作为上层协议载体更常见且重要的应用方式是,物理层采用更高效的Chiplet互连标准(如UCIe),而在协议层运行PCIe。UCIe标准原生支持PCIe作为其上层协议之一。在这种架构下,Chiplet间享受了高带宽、低延迟的物理连接,同时在软件层面呈现为标准的PCIe设备,继承了PCIe完善的生态、驱动和操作系统支持。168系统级互联的补充在包含多个Chiplet的复杂封装中,可能同时存在多种互连。例如,计算核心与缓存之间采用超低延迟的专用总线,而与通用I/O Chiplet或外部内存控制器之间则可能采用PCIe,以满足不同的带宽、延迟和功能隔离需求。PCIE CCIXCCIX(缓存一致性互联协议)是一个旨在为CPU与加速器之间提供高性能、缓存一致互连的协议标准。它的核心目标是通过引入缓存一致性机制,简化异构系统的数据共享,降低时延,提升带宽。1CCIX的分层架构组成CCIX采用了分层架构设计,可以分为协议规范和传输规范两部分。CCIX协议规范:包含协议层和链路层,负责定义缓存一致性协议、消息格式、流量控制等。CCIX传输规范:包含事务层(CCIX和PCIe事务层)、数据链路层(PCIe数据链路层)和物理层(CCIX物理层),负责具体的数据包传输、错误校验和物理连接。23CCIX物理层的两种实现方式CCIX并非独立的物理接口,而是在物理层上兼容或扩展现有的高速互连标准。兼容PCIe PHY:CCIX规范要求设备必须支持两种物理层之一。一种是PCIe PHY,即完全使用PCIe标准的物理层和电气接口。这使得CCIX可以无缝运行在标准的PCIe插槽和链路上。扩展EDR PHY:另一种是CCIX EDR PHY。这是一种扩展模式,在原PCIe物理层基础上提升数据速率,支持20GT/s和25GT/s,以提供更高的原始带宽。CCIX与PCIe的关系和优势CCIX在设计上深度依赖于PCIe的成熟基础设施,并对其进行了功能扩展。协议层面复用与扩展:CCIX构建在PCIe的数据链路层之上,定义了自身的协议层和事务层,以支持缓存一致性。它既可以传输标准的PCIe数据包,也可以传输为一致性操作优化的、开销更小的CCIX包。35物理层面兼容与提速:CCIX可以在标准的PCIe物理层上运行,从而利用现有庞大的PCIe生态。同时,它又通过EDR模式提供了高于PCIe 4.0原生16GT/s的速率选项CCIX协议未被正式纳入PCIe Gen5或Gen6的核心规范,它作为一个独立的互联协议,通过复用PCIe物理层来实现高速互连。CIX没有“成为”PCIe规范的一部分,而是作为一种能够运行在PCIe物理通道上的、附加的协议层存在。它需要系统中的芯片(如CPU、加速器)专门集成CCIX控制器(即CCIX协议栈)才能启用。PCIE CXLCXL是一种独立的逻辑协议CXL(Compute Express Link)是一种开放标准的行业协议(即逻辑规范和数据通信规则),而非物理接口的硬件定义。它定义了主机处理器与加速器、内存扩展设备等之间进行高带宽、低延迟通信时所需的链路层、传输层及事务层协议,特别是强调了缓存一致性内存访问的语义。27CXL复用PCIe的物理层接口CXL协议在物理层完全复用并依赖于PCIe(特别是Gen 5及以上版本)的物理电气接口。这意味着CXL设备使用与PCIe设备相同的连接器、线缆和电气信号标准进行物理连接和数据传输。CXL利用PCIe的这种成熟物理基础来实现高速互连,从而简化了硬件设计和产业推广。125CXL并非PCIe协议的一部分CXL是一个与PCIe并行发展、相互协作但独立的协议。它没有成为PCIe协议的一部分。具体表现为:协议栈独立:CXL拥有自己独特的链路层和传输层协议(如CXL.cache, CXL.mem),这些协议在通过PCIe物理层传输前,会与CXL.io协议动态复用。35组织独立:CXL由独立的CXL联盟制定和维护,而PCIe则由PCI-SIG组织管理。两者是不同的行业标准机构。2兼容与共存:CXL设备可通过PCIe的Flex Bus接口兼容连接。如果主机或设备不支持CXL,链接将降级为标准的PCIe操作模式,这表明两者是共存而非融合的关系Unified BUSUnified BUS 也可用于C2C灵衢定义为面向超节点(SuperPoD) 的统一互联协议,旨在将 I/O、内存访问、异构计算单元(CPU/NPU/GPU等)之间的通信融合到同一技术体系中,实现高性能、高协同、高弹性的计算基础设施。UCIEUCIE 也可以用于C2CUCIe规范采用分层架构方法,在保持高性能的同时最大化灵活性和互操作性。在基础层面,物理层在电气层面处理芯间I/O,实现链路训练、通道修复/反转、扰码、模拟前端功能、时钟、侧带通信和配置寄存器。该层还定义通道要求并确保符合电气规范。物理层设计为适应不同的封装技术,同时保持一致的性能特性。中间层,称为芯间适配器,作为可靠性层负责确保可靠的数据传输。当使用多个协议时,实现仲裁和多路复用,处理CRC/重试机制进行错误检测和纠正,管理链路状态转换,并支持连接设备之间的参数协商。适配器维护可访问高级功能的配置寄存器,在原始模式下可完全绕过,用于需要直接访问物理层的专用应用。这种灵活性允许标准化和定制实现在UCIe框架内共存。在堆栈顶部,协议层支持多种接口类型,以适应多样化的使用模型。主要支持的协议是CXL/PCIe,适用于需要标准化"即插即用"功能的大量应用,如I/O附件、内存接口和加速器。这些协议利用现有软件生态系统,实现与当前系统架构的无缝集成。对于更专业的应用,UCIe还支持流式接口,可容纳AXI、CHI、SFI和CPI等专有协议。这种流式方法对于从较小芯片构建更大计算单元的扩展场景特别有价值,例如由多个较小元素组成的CPU、GPU和网络交换机。完整规范涵盖从物理凸点/键合焊盘层到形状因素定义的互连,为跨不同封装技术和应用领域的Chiplet集成创建了全面框架。 -
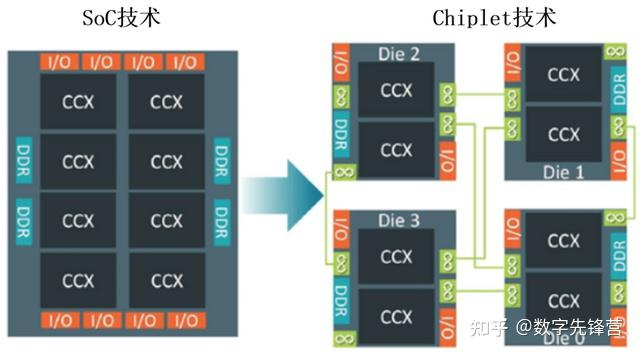
AI专题十六:AI算力chiplet的die-to-die连接 1 从SOC 到chipletChiplet又称“小芯片”或“芯粒”,它是一种功能电路块。Chiplet技术就是将一个功能丰富且面积较大的芯片裸片(die)拆分成多个芯粒(chiplet),并将这些具有特定功能的芯粒通过先进封装的形式组合在一起,最终形成一个系统芯片。而目前市场主流的SoC(英文全称是System-on-a-Chip)技术则与之相反,它是将多个负责不同功能的电路块通过光刻的形式制作到同一块芯片裸片(die)上,如手机SoC芯片,基本都集成了CPU、GPU、DSP、ISP、NPU、Modem等不同功能的计算单元和诸多的接口IP。SoC技术和Chiplet技术的关系示意图,如下所示:SoC技术对先进的纳米工艺有着高度的依赖。像手机芯片制造工艺就越来越高,从28nm一路升级到10nm、7nm、5nm,目前正进一步走向3nm甚至更低。不过,纳米工艺已经接近物理极限,业内普遍认为半导体行业正在进入后摩尔时代,需要寻找新的技术路线。于是,Chiplet技术被寄予厚望,很可能在未来几年成为一种主要的芯片设计形式。那么,Chiplet技术具体有哪些优点呢?Chiplet有哪些优势?首先,Chiplet技术把大芯片分成面积更小的芯片,有助于改善良品率,从而减少制造成本。通常,在晶圆加工过程中,离晶圆中心越远就越容易出现坏点。因此从硅晶圆中心向外扩展,坏点数呈上升趋势,所以企业无法随心所欲地增大晶圆尺寸,否则不良率会大幅上升。其次,SoC芯片的逻辑计算单元依赖先进制程来提高性能,其他部分通常可使用成本更低的成熟制程,SoC芯片Chiplet化之后,不同芯粒可以根据需要来选择合适的工艺制程分开制造,再通过先进封装技术进行组装,从而有效降低制造成本。2 chiplet die-to-die 连接方式die-to-die 连接示意图目前主流的chiplet die-to-die 主流连接接口根据下面信息,主要优先掌握ucie 、openHBI接口,了解Nvlink、Unified BUS连接。 几乎每家有实力做AI 算力芯片的公司都会搞自己私有的die-2o-die 接口。ucie统一Chiplet标准UCIe在众多Chiplet互联标准中,由Intel提出的通用Chiplet互联标准(UCIe)在很短时间内就引起了业界广泛关注,目前来看最有希望成为业界统一的互联标准。UCIe是唯一具有完整裸片间接口堆栈的标准,其他标准都没有为协议栈提供完整裸片间接口的全面规范,大多仅关注在特定层。此外,UCIe不但支持有机衬底或层压板等传统封装,也可以支持2.5D和桥接等先进封装,如硅衬底、硅桥或再分配层(RDL)扇出等形式,预计未来还会支持3D封装。UCIe协议栈本身有三层:最上端的协议层通过基于流量控制单元(FLIT)的协议实现,确保最大效率和最低延迟,并支持多个主流协议,包括PCIe、Compute Express Link(CXL),以及用户定义的流协议。中间的D2D适配层用于对协议进行仲裁与协商,以及通过裸片间适配器进行连接管理。基于循环冗余检查(CRC)和重试机制,该层还包括可选的错误纠正功能。最下面的物理层(PHY)规定了与封装介质的电气接口,是电气/模拟前端(AFE)、发射器/接收器以及边带通道(Sideband)在两个裸片之间进行参数交换与协商的层级。逻辑PHY可实现连接初始化、训练和校准算法,以及测试和修复功能。UCIe协议具有如下优点:UCIe的Sideband、DDR、Forward Clock设计使得UCIe单个应用场景下的模块设计复杂度相对更低,模块验证也更加容易;UCIe传输时延和功耗更低、速率更高、BER更低,在功耗和性能的平衡方面做得比其他协议好;由于和PCIe/CXL的无缝对接,可以利用PCIe现有的强大生态,轻松地将板级互联扩展到封装内部;UCIe不但支持PCIe向CXL的扩展,还支持用户自定义的Raw mode,一个D2D Adaptor 可持架接多个协议栈。目前已经有不少国内厂商加入UCIe联盟,其中包括:阿里云、日月光、长电、华为、芯原、灿芯、芯耀辉、超摩科技、合见工软、芯和半导体、长鑫、牛芯、芯云凌、芯来科技和奎芯等。此外,由中国计算机互连技术联盟(CCITA)发起的Chiplet标准《小芯片接口总线技术要求》在中科院计算所、工信部电子四院和国内多个芯片厂商合作推动下,也已经发布。小芯片接口总线技术的体系架构见下图,主要包括数据链路层(Data Link Layer,DLL)、物理适配层(Physical Adaptation Layer,PAL),以及物理层(Physical Layer,PHY)等。此标准列出了并行总线等三种接口,提出了多种速率要求,总连接带宽可以达到1.6Tbps,以灵活应对不同的应用场景以及不同能力的技术供应商。通过对链路层、适配层、物理层的详细定义,实现在小芯片之间的互连互通,并兼顾了 PCIe 等现有协议的支持,列出了对封装方式的要求。小芯片设计不但可以使用国际先进封装方式,也可以充分利用国内通用封装技术。BoWODSA正在定义一个名为Bunch of Wires (BoW)的芯片到芯片接口。BoW接口专注于解决基于有机基板的并行互连问题,BoW有BoW Base,BoW-Fast和BoW-Turbo三种类型,支持不同的传输距离和传输效率。此外,BoW支持向后兼容,并且对芯片工艺和封装技术的限制较少,不依赖于先进的基于硅的互连封装技术,具有广泛的应用范围Bunch of Wires(BoW)是一种适合Chiplet和芯片级封装(CSP)互联的简单物理接口架构,起初是针对数据中心计算、通信和网络需求的短距离互联解决方案,后来被OCP下属的开放特定域架构(ODSA)工作组采纳为用于连接同一封装内近距离裸片互联的接口协议。跟服务器板卡之间的互联不同,芯片封装内多个裸片的互联环境相对稳定,因为距离短,信号衰减小,因此互联设计可以比较简单。其实,BoW接口设计的初衷就是要实现低实施成本、兼容不同IC工艺节点,并可灵活支持各种封装技术凸凹间距,从而满足复杂芯片的低功耗、低延迟和高吞吐量要求。据OCP/ODSA介绍,BoW应用于Chiplet互联时具有如下优势:比现有并行标准更高的数据速率;适用于传统的低成本压层衬底封装及更高密度的硅interposer封装;比采用传统的SerDes链路设计更容易实现(较低的数据传输率可以使用单端信号及更密集的线束);兼容混合凸凹间距的封装情况。2018年,OCP与JEDEC联合起草了CDXML (Chip Data Exchange Markup Language)规范,定义了Chiplet互联的电气、机械和散热标准。这一针对2.5D或3D堆叠Chiplet设计的规范语言采用XML格式,并借鉴了多个现有JEDEC标准,包括JEP181散热标准和JEP30-P101电气/机械和I/O标准,以及IEEE 1687测试 和IEEE 2416电源模型标准。BoW 的开放式物理层和链路层规范旨在支持高性能 D2D 接口。关键性能指标包括每条线路高达 32Gb/s 的数据传输速率、低于 0.5pJ/bit 的能效和低于 8ns 的延迟。BoW 与各种封装和集成电路工艺的兼容性使其成为不同成本和性能设计点的通用解决方案。发展到 BoW 2.1为了促进开放式芯片经济的发展,BoW 正在不断改进,以满足新应用的需求,特别是在人工智能、边缘和物联网领域。即将发布的 BoW 2.1 版本将在三个关键领域引入规范扩展: 光学、内存和物联网。BoW简化了传统SerDes的复杂性,适合短距离互联:传统SerDes架构: BoW架构:┌────────────┐ ┌────────────┐│Serializer │ │ ││ PLL │ │ Simple ││ CDR │ │ Driver ││ Equalizer │ │ │└────────────┘ └────────────┘复杂度:高 复杂度:低功耗:>5 pJ/bit 功耗:<1 pJ/bit关键简化:无需时钟数据恢复(CDR)无需均衡器简单的单端驱动器源同步时钟物理层实现细节IO单元设计: ┌─────────────────────┐ TX───│ Driver │ │ - Impedance: 50Ω │───> Bump │ - Slew Rate Control│ └─────────────────────┘ ┌─────────────────────┐ RX<──│ Receiver │<─── Bump │ - Comparator │ │ - Hysteresis: 20mV │ └─────────────────────┘时钟分发网络:H-tree结构最小化偏斜每16个数据位配1个时钟相位插值器用于去偏斜最大偏斜:<50ps时钟架构深度分析转发时钟 vs 嵌入式时钟:转发时钟(AIB/BoW选择):优点:简单、低功耗、确定性延迟缺点:需要额外的时钟引脚适用:Chiplet等确定性连接嵌入式时钟:优点:无需时钟引脚、灵活缺点:需要CDR、功耗高适用:板级互联、光通信多时钟域处理:Die A (1GHz) Die B (1.5GHz) │ │ ├──> Async FIFO <──────┤ │ │ └──> Clock Domain ─────┘ Crossing (CDC)AIB/MDIOAdvanced Interface Bus (AIB)最初由Intel开发,用于FPGA的die-to-die互联。AIB 1.0特性(2017年):单端信令数据速率:2 Gbps/pin凸点间距:55μm功耗:0.85 pJ/bit应用:Intel Stratix 10 FPGAAIB 2.0改进(2019年):数据速率:4 Gbps/pin功耗优化:0.5 pJ/bit增强时钟架构DFT(Design for Test)增强作为AIB的升级版本,MIDO提供了更高的传输效率,并且响应速度和带宽密度是AIB的两倍以上。AIB和MDIO技术主要适用于通信距离短,损耗低的2.5D和3D封装技术,例如EMIB、Foveros。LIPINCONLIPINCON:LIPINCON是台积电多年前就开始研发的裸片之间数据互联接口技术,通过使用先进的基于硅的互连封装技术(例如InFO、CoWoS)和时序补偿技术,为Chiplet提出的高性能互连接口。LIPINCON可以在没有PLL/DLL的情况下降低功耗和占用面积。LIPINCON接口包含两种类型的PHY:PHYC和PHYM,分别用于SoC芯片和存储器/收发器芯片。OpenHBIOpenHBI 利用 JEDEC 的 HBM3 电气特性和 IO 类型来降低风险。它使用低电压和未端接的单端 DDR 信号来传输晶粒之间的数据。OpenHBI 标准具有许多关键特征:整合多个 OpenHBI 兼容 的 die-to-die 接口,实现互操作性利用 JEDEC HBM3 IO 类型和电气特性可与支持 HBM 存储器和 OpenHBI 标准的双模 HBM 主机控制器互操作支持硅中介层和晶圆级集成扇出或同等技术实现对称 die-to-die 接口实现目标速度:每引脚 8Gbps,正迈向 12-16 Gbps在最高数据传输速率时提供长达 3mm 的互连距离实现小于等于 0.5pJ/bit 的功耗目标提供大于 1.5T 位/毫米(包括发射器和接收器)的线性(边缘)带宽密度定义 PHY 和逻辑 PHY 抽象层,轻松适配上层支持正常的和旋转的晶粒方向可以调整带宽和边缘(DW 数量)以匹配各种用例支持小芯片 (Chiplet) 配置和测试 (CCT) 接口支持通道修复,提高制造良率OpenHBI 标准主要针对图 2 所示的下层(PHY 和逻辑 PHY 层)。然后将适配器层用于与上层(协议层)进行连接。因此,系统实现不依赖于各个应用所用的协议。Infinity FabricInfinity Fabric 是AMD为其Ryzen、EPYC等产品设计的内部互连架构。它由传输数据的Infinity Scalable Data Fabric和负责控制的Infinity Scalable Control Fabric组成,连接CPU核心、GPU、内存控制器以及多die之间和多个CPU插槽之间。它本质上是AMD的专有技术,不对外开放规格,主要用于其自家产品内部的die-to-die和多socket互连.NvlinkVIDIA的NVLink技术可以用于chiplet内部的die-to-die连接,其具体实现形式被称为NVLink-C2C。这项技术是NVIDIA应对chiplet和异构集成趋势的核心方案。以下是其关键特性与应用场景的详细说明:技术形态:NVLink-C2C这是一种专门为芯片内部或封装内die-to-die互连而设计的物理层和互连协议技术。它脱胎于高带宽的GPU间NVLink技术,但针对短距离、超高密度的片上互连进行了优化9。性能特点超高带宽与低延迟:在先进封装(如硅中介层)下,能提供高达900 GB/s的带宽,延迟极低,并支持缓存一致性9。高能效与面积效率:其能效比是PCIe 5.0的25倍,面积效率更是高达90倍,使其非常适合对功耗和空间极其敏感的chiplet设计9。主要应用场景NVLink-C2C主要用于连接NVIDIA自家的不同计算芯粒,构建超级芯片:CPU-CPU连接:例如在Grace Superchip中,用于连接两个Grace CPU die,形成一个统一的144核处理器9。CPU-GPU连接:例如在Grace Hopper Superchip中,用于连接Grace CPU die和Hopper GPU die,实现CPU与GPU间的高速协同9。为定制芯片提供接口:NVIDIA也将此技术以 “NVLink Fusion” 的形式开放授权。其他厂商(如定制AI加速器公司)可以将其Chiplet集成到自己的设计中,从而接入NVLink生态系统,与NVIDIA的GPU实现高速互连5813。与标准互连方案的对比与传统(板级)NVLink的区别:传统的NVLink用于连接独立的GPU卡或板级组件,通过PCB走线或电缆传输。而NVLink-C2C是通过封装内的硅中介层或硅桥进行连接,属于片上网络级别,带宽和能效更高9。与开放标准(如UCIe)的关系:在chiplet互连的开放标准领域,UCIe 是主流。NVIDIA的NVLink-C2C是一种专有高性能方案,主要服务于其自身的产品生态。虽然性能卓越,但开放性不及UCIe4。总结NVLink-C2C是NVIDIA用于chiplet内部die-to-die连接的专用高性能互连技术。它已成功应用于其Grace CPU和Hopper GPU的超级芯片设计中,并通过NVLink Fusion计划向合作伙伴开放,旨在构建一个以NVLink为核心的高速异构计算生态系统这是一个非常精准的技术命名问题。NVIDIA将其chiplet/芯片间互连技术命名为 NVLink-C2C(Chip-to-Chip),而非Die-to-Die(D2D),这一选择背后反映了其技术定位、封装层级和市场策略的深层考量。一、 技术层级与封装范畴的区分“Die-to-Die”通常指代的是在单个封装(Package)内部,不同硅片(裸片)之间的互连。 例如,AMD的Chiplet架构中,CCD与IOD之间的连接,或英特尔EMIB技术连接的裸片,都属于这个范畴。其特点是距离极短、功耗极低,通常依赖于硅中介层或先进封装技术实现超高密度布线。而“Chip-to-Chip”则定义了一个更宽泛、封装层级更高的互连范畴。 它明确包含了两种场景:单封装内裸片互连:即传统意义上的D2D。板级芯片互连:将两个独立的、已封装好的芯片(如一个Grace CPU封装和一个Hopper GPU封装)通过基板上的超高密度布线连接在一起,形成一个更大的“超级芯片”。NVLink-C2C的核心设计目标正是为了无缝覆盖以上两种场景。 例如在Grace Hopper超级芯片中,它既可用于连接同一封装内的计算单元,更重要的是用于连接独立的Grace CPU芯片和独立的Hopper GPU芯片,将它们整合为一个统一的内存系统。3510二、 强调技术扩展性与通用性使用 “Chip” 而非 “Die”,在语义和营销上更具扩展性:“Chip”是商品化的单元:在产业链和用户认知中,CPU、GPU、DPU都是可以独立采购、封装和测试的“芯片”。命名为C2C,清晰地传达了这项技术可用于连接这些已经成型的产品级芯片,而不仅仅是制造过程中的半成品裸片。体现技术通用性:它暗示该技术不仅可以用于NVIDIA自家芯片的互连,未来也可能开放给合作伙伴,用于连接其他符合标准的第三方芯片,构建更广泛的生态系统。这与D2D通常局限于同一家公司、同一封装内部的私有互连协议形成了概念上的区别。3三、 与UCIe等D2D标准进行战略区分在NVIDIA推出NVLink-C2C的同期,行业正在力推开放的UCIe标准,其核心正是Die-to-Die互连。NVIDIA选择“Chip-to-Chip”的命名,在技术话语体系上巧妙地与UCIe进行了区隔:UCIe:定位为封装内裸片互连的开放标准,旨在实现不同厂商裸片在先进封装内的“即插即用”。1NVLink-C2C:定位为NVIDIA私有的、更高层级的互连技术,不仅涵盖封装内,更强调封装间(板级)的超高性能一致性互联,服务于其构建“超级芯片”和庞大计算节点的整体战略。56这种命名避免了让市场直接将其与UCIe在D2D层面进行对标,而是突出了其在性能(带宽、延迟)和系统集成度上的更高追求。6四、 品牌与技术路线的延续“NVLink” 本身已是NVIDIA高性能互连的金字招牌,最初用于GPU间互联,后扩展到GPU与CPU。“C2C”是其自然演进,明确了互连的物理主体从“板卡”进一步下探到了“芯片”级别。NVLink(卡间) -> NVLink-C2C(芯片间) -> (未来可能的)更紧密集成。这种命名保持了品牌的一致性和技术演进的清晰脉络,让开发者与合作伙伴易于理解:这是NVLink技术向更底层、更紧密集成方向的延伸。总结NVIDIA选择 NVLink-C2C 而非 NVLink-D2D,绝非随意之举:技术定义更广:C2C涵盖了从封装内裸片到板级封装芯片的互连,而D2D通常特指前者。市场定位更高:强调其用于连接完整产品级芯片,构建超级芯片系统的能力,与单纯的裸片集成区分开来。战略区隔明显:与行业开放的UCIe(D2D)标准形成差异化竞争,突出其私有高性能技术路线。品牌延续性强:作为NVLink家族的新成员,清晰表明了技术方向的演进。因此,“Chip-to-Chip”是对这项技术野心和应用范围更准确、更具战略视野的命名。Unified BUS华为统一开放的可以用于芯片内部,die-2-top, chip-to-chip,server-to-server 的总线。技术核心特点:总线级互联:提供类似计算机内部总线的紧密连接能力,使得超节点内多个计算单元能够高效协同工作。协议归一化:通过统一互联协议,解决不同计算设备间的兼容性问题,降低系统复杂度。平等协同:超节点内各个计算单元处于平等地位,能够动态分配任务和负载。全量池化:将计算、存储和网络资源完全池化,实现资源的灵活调度和高效利用。大规模组网:支持极大规模计算集群组建,华为基于灵衢技术推出的超节点集群可支持50万卡至百万卡级别的算力规模。高可用性:具备故障自动检测、隔离和恢复能力,确保大规模计算系统的高可靠性。华为自2019年开始研究灵衢技术,目前已发布灵衢2.0技术规范并对外开放,包括《灵衢基础规范2.0》、《灵衢固件规范2.0》和《灵衢使能操作系统参考设计2.0》等核心文档3 chiplet 的封装技术支持Chiplet的底层封装技术维度代表技术厂商核心特点2DMCM (Multi-Chip Module)通用多芯片平铺在有机基板上,通过基板布线互连,成本低但密度有限2.5DCoWoS (Chip-on-Wafer-on-Substrate)台积电通过硅中介层或 RDL 中介层实现高密度互连,分为 CoWoS-S(硅中介层)、CoWoS-R(RDL 中介层)、CoWoS-L(LSI+RDL) EMIB (Embedded Multi-die Interconnect Bridge)Intel嵌入式硅桥技术,无需完整硅中介层,成本更低、灵活性更高 I-Cube三星分为 I-Cube S(硅中介层,类似 CoWoS)和 I-Cube E(Si Bridge + RDL,类似 EMIB) InFO\_oS / FOCoS-B台积电 / 日月光扇出型封装,使用 RDL 重布线层作为中介层3DSoIC (System-on-Integrated-Chips)台积电晶圆对晶圆键合,无凸点直接键合,真正的垂直 3D 堆叠 FoverosIntel有源中介层 3D 堆叠,使用 TSV 实现上下层芯片通信 X-Cube三星3D 封装技术,支持 HBM 与逻辑芯片垂直集成 Hybrid Bonding (混合键合)多家铜-铜直接键合,实现更高密度的 3D 互连封装技术目前主要由TSMC、ASE、Intel等公司来主导,包含从2D MCM到2.5D CoWoS、EMIB和3D Hybrid Bonding。本文主要介绍目前工业界主流的2D和2.5D封装技术和其优缺点。1. MCM(Multi-Chip Module)Multi-chip ModuleMCM一般是指通过Substrate(封装基板)走线将多个芯片互联的技术。通常来说走线的距离和范围可以在10mm~25mm,线距线宽大约10mm量级,单条走线带宽大约10Gbit/s量级。由于MCM可以通过基板直接连接各个芯片,通常封装的成本会相对较低,但是由于走线的线距线宽比较大,封装密度相对较低,接口速率相对较低,延时相对较大。MCM 是 2D 封装:所有芯片平铺在基板上,通过基板走线连接,技术成熟、成本最低,但布线密度受限(线宽通常 >12μm)2. CoWoS(Chip-on-Wafer-on-Substrate)CoWoS是TSMC主导的,基于interposer(中间介质层)实现的2.5D封装技术,其中interposer采用成熟制程的芯片制造工艺,可以提供相比MCM更高密度和更大速率的接口。目前TSMC主流的CoWoS技术包括:CoWoS-S:基础CoWoS技术,可以支持超高集成密度,提供不超过两倍掩膜版尺寸的interposer层,通常用于集成HBM等高速高带宽内存芯片。CoWoRCoWoS-R:基于前述CoWoS-S技术,引入InFO技术中的RDL(Redistribution Layer),RDL 中介层由聚合物和铜迹线组成,具有相对机械柔韧性,而这种灵活性增强了封装连接的可靠性,并允许新封装可以扩大其尺寸以满足更复杂的功能需求,从而有效支持多个Chiplets之间进行高速可靠互联。CoWoS-RCoWoS-L:在上述CoWoS-S和InFO技术的基础上,引入LSI(Local Silicon Interconnect)技术,LSI 芯片在每个产品中可以具有多种连接架构(例如 SoC 到 SoC、SoC 到小芯片、SoC 到 HBM 等),也可以重复用于多个产品,提供更灵活和可复用的多芯片互联架构。CoWoS-L相比于MCM,CoWoS技术可以提供更高的互联带宽和更低的互联延时,从而获得更高的性能。同时,受限于interposer的尺寸(通常为2倍掩膜版最大尺寸),可以提供的封装密度上限相对比较有限,并且由于interposer的引入,需要付出额外的制造成本和更高的技术复杂度,以及随之而来的整体良率的降低。3. EMIB(Embedded Multi-die Interconnect Bridge)EMIBEMIB是Intel主导的2.5D封装技术,使用多个嵌入式包含多个路由层的桥接芯片,同时内嵌至封装基板,达到高效和高密度的封装。由于不再使用interposer作为中间介质,可以去掉原有连接至interposer所需要的TSVs,以及由于interposer尺寸所带来的封装尺寸的限制,可以获得更好的灵活性和更高的集成度。总体而言,相比于前述介绍的MCM、CoWoS和InFO/LSI技术,EMIB技术要更为优雅和经济高效,获得更高的集成度和制造良率。但是EMIB需要封装工艺配合桥接芯片,技术门槛和复杂度较高。CoWoS、EMIB、I-Cube 都属于 2.5D 封装:它们都通过中介层/硅桥实现比 MCM 更高密度的互连CoWoS 使用完整硅中介层,密度最高但成本也高EMIB 使用局部硅桥,性价比更好I-Cube E 是三星的"类 EMIB"方案SoIC、Foveros、X-Cube属于 3D 封装:实现芯片垂直堆叠,是真正的立体集成用于 HBM 堆叠、3D Cache 等场景"3.5D 封装"是混合概念:实际工程中常混合使用 2.5D 和 3D,例如逻辑芯片用 2.5D 放在中介层上,HBM 内存用 3D 堆叠,但这并非正式分类4 Chiplet架构挑战和洞察基于Chiplet的架构设计,首先要考虑不同Chiplets之间如何进行功能划分和架构定义,目前主流的设计思路大致可以分为两类:第一类基于功能划分到多个Chiplets,单个Chiplet不包含完整功能集合,通过不同Chiplets组合封装实现不同类型的产品,典型代表为Huawei Lego架构(Kunpeng & Ascend)、AMD Zen2/3架构。Huawei Lego架构:采用compute die(compute + memory interface)和I/O die组合的形式进行不同Chiplets功能拆解。在compute die(CPU/AI)设计时采用先进的工艺,获得顶级的算力和能效,在I/O die设计时采用成熟工艺,在面积与先进工艺差别不大的情况下获得成本收益。并且不同的Chiplets的数量和组合形式都可以灵活搭配,从而组合出多种不同规格的云端高性能处理器产品。AMD Zen3架构:采用CCD(compute)和CIOD(memory interface + I/O)组合的形式进行不同Chiplets功能拆解。在CCD设计时采用最先进的工艺,获得顶级的算力和能效,在CIOD设计时采用成熟工艺,在面积与先进工艺差别不大的情况下获得成本收益。并且CCD本身按照两个4C8T cluster组合的形式设计,可以适应AMD从Desktop到Server的架构需求,根据场景选择CCD数量和设计对应的CIOD即可,灵活度非常高。第二类单个Chiplet包含较为独立完整的功能集合,通过多个Chiplets级联获得性能的线性增长,典型代表为Apple M1 Ultra、Intel Sapphire rapids系列。Apple M1 Ultra:通过Apple自研的封装技术UltraFusion来堆叠两颗M1 Max芯片,使得两颗芯片之间拥有超过2.5TB/s带宽且极低延时的互联能力。基于这个互联的延时带宽能力,可以使得M1 Ultra直接获得两倍M1 Max的算力,同时在软件层面依然可以将M1 Ultra当做一个完整芯片对待,而不会增加额外的软件修改和调试的负担。Intel Sapphire Rapids:通过两组镜像对称的相同架构的building blocks,组合4个Chiplets,获得4倍的性能和互联带宽。每个基本模块包含计算部分(CHA & LLC & Cores mesh, Accelerators)、memory interface部分(controller, Ch0/1)、I/O部分(UPI,PCIe)。通过将上述高性能组件组成基本的building block,再通过EMIB技术进行Chiplet互联,可以获得线性性能提升和成本收益。基于Chiplet的架构设计,同时要考虑多个Chiplets如何进行有效互联和扩展,实现高效灵活可扩展的架构,避免多Chiplets之间出现信号死锁、流量拥塞等功能和性能问题。由于芯片内部互联通常为可靠连接假设下的并行数据传输,而芯片之间的互联通常为不可靠连接假设下的串行数据传输,根据芯片片上和片间互联架构的组合和流量收敛情况,目前主流的设计思路和应用场景大致分为两大类:第一类片上片间相同架构,流量全打平或基本打平。典型代表如Cerebras,采用从tile到single die到wafer scale engine完全相同的互联架构。另一个典型代表是Tesla DoJo,采用InFO-SoW的封装和芯片四边全部放置I/O接口的方式实现片内每个方向10TBps带宽,跨片每边4TBps,SoW集成后单边带宽9TBps。CS-1 Wafer Scale Engine第二类片上片间架构相似,片间流量按照一定比例收敛。典型代表一个是前述的Huawei Bufferless Multi-Ring架构,片上流量会收敛到分布式的各个跨片接口;另一个典型代表是前述的Apple M1 Ultra,片上流量收敛到UltraFusion集中交换部分。Bufferless Multi-Ring从计算负载的角度,当单个计算任务计算密度较高,超出单芯片算力范围的时候,需要多个芯片协同来完成,此时跨片数据交互也需要提供和片上数量级相当的带宽和延时,才能更有效利用算力,提高计算效率。典型的任务类型是AI的训练任务,前述Cerebras和DoJo的互联架构对这类场景有较强优势。当计算任务数量庞大,单个任务负载较小,跨片流量通常是要远小于片上流量的,此时采用流量收敛策略更为合适。
-
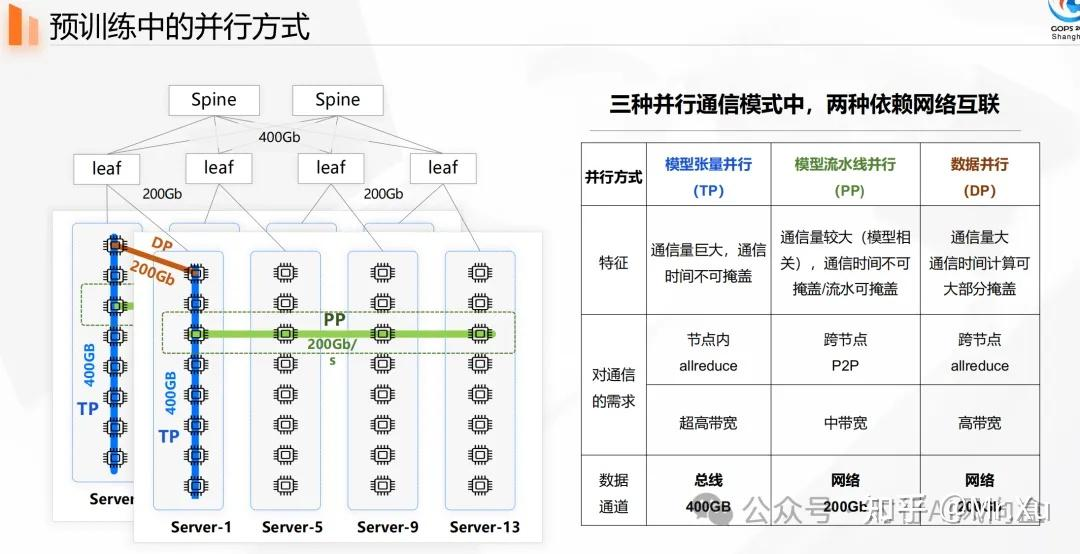
AI专题十五:AI算力卡互联 备注:未来主要是看Nvlink、UAlink、Unified Bus在 AI 训练和推理中,单卡性能固然重要,但当模型规模、数据量持续膨胀时,模型参数到达几十亿甚至上千亿参数,单张 GPU 的显存与算力已无法独立承载训练、推理任务,多卡并行成为唯一选择。这时候,卡与卡之间的互联带宽、延迟、拓扑结构 就成了制约整体性能的关键瓶颈。(图源:GOPS 全球运维大会暨研运数智化技术峰会 2024 · 上海站)本文主要介绍节点内部的GPU互联,节点间的GPU互联涉及网络部分,后面开新篇详细讲解。大模型训练时,模型的权重矩阵被切分到不同 GPU,每次前向/反向传播都要交换激活或梯度。这种通信量大但延迟敏感的场景,放在节点内更高效,因此单节点内,会经常有张量并行的场景。这种高带宽、低延迟的互联需求,也催生了GPU互联技术的发展。1、PCIe最初,大家都使用PCIe 进行互联,GPU 插卡通过 PCIe 接入主板,生态成熟、通用性强、设备即插即用。(图源:《电子发烧友》)但随着模型规模不断增大,PCIe 的带宽逐渐显得不足。以某PCIE GPU服务器为例,每个CPU下连接一个PCIe Switch芯片,每个PCIe Switch芯片连接5张GPU。GPU0-GPU3、GPU4-GPU7的两组GPU,内部可以通过PCIe switch通信,但如果需要跨组通信,只能通过CPU之间UPI来进行(GPU 1 -> PCIe 总线 -> CPU -> PCIe 总线 -> GPU 8)。(图源:元脑®服务器 NF5468G7 系列技术白皮书)不过,即使是最新的PCIe 技术,提供的带宽也有限。PCIe 4.0 x16 单向带宽约 32 GB/s,PCIe 5.0 64 GB/s。相比 GPU 内部早已上TB/s的显存带宽,这显然成了“木桶效应”中的短板,成了拉低通信效率的瓶颈。为了解决这一瓶颈,GPU 厂商开始探索专门的GPU互联通道。2、英伟达NVLinkNVLink首次作为GPU互联技术随NVIDIA P100 GPU推出,此后与每一代新的NVIDIA GPU架构同步发展。从最初的简单GPU-GPU连接,到如今的全系统互联解决方案,NVLink已经成为高性能GPU互联的代名词。2016年,NVLink 1.0 与 P100 GPU 一同发布(顺便说一句,Tesla P100也是全球首个支持高带宽 HBM2 内存技术的 GPU 架构),一张 GPU 支持最多 4 条 NVLink,每条链路双带宽约 40 GB/s ,整个芯片的总双向带宽达到了 160GB/s,大大突破了PCIe 3.0 带宽限制(PCIe 3.0 x16 双向仅 ~32 GB/s)。2017 年,NVLink 2.0 随 V100 (Volta 架构) 推出,每条链路双向带宽提升至 50 GB/s,单卡支持 6 条链路,总带宽最高 300 GB/s。NVLink2.0 技术虽然大大提高了带宽,但是单服务器中 8 个 GPU仍然无法做到全连接,为解决该问题,NVIDIA 在V100发布同年,发布了 NVSwitch,实现了 NVLink 的全连接。GPU所有的端口都用于与SW互联,数据在所有NVLink通道上交错传输,支持任意两块 GPU 之间的全带宽,NVLinks 的总带宽未超,对单个 GPU 的传输就不会阻塞。到如今,NVLink已经发展到了第五代,几乎每一代的带宽都是翻倍增长,最新的第五代性能已经高达1.8T/s。第五代NVIDIA NVSwitch更是配备144 个NVLink 端口,无阻塞交换能力达到了14.4 TB/s。备注:NVLink 和 NVSwitch 是英伟达(NVIDIA)为解决高性能计算和人工智能(AI)场景下多 GPU 间通信瓶颈而设计的两项核心技术。它们虽然紧密相关,但角色和功能有本质区别。下面从基础概念、功能定位、技术演进、工作原理和实际应用等方面进行详细分析。NVLink:点对点连接最初设计用于替代带宽受限的 PCIe 接口。支持两个设备(如 GPU-GPU 或 GPU-CPU)之间直接通信,提供远高于 PCIe 的带宽和更低的延迟。例如:两张 A100 GPU 通过 NVLink 直连,可实现高达 600 GB/s 的双向带宽(A100 SXM4)。NVSwitch:全互连拓扑构建者解决多 GPU 系统中“无法全互联”的问题。在一个服务器内(如 DGX 系统),NVSwitch 芯片允许多个 GPU(如 8 个或 16 个)通过 NVLink 连接到同一个交换矩阵上,实现“每个 GPU 都能直接与其它所有 GPU 通信”。消除了传统 PCIe Switch 或树状拓扑中的通信瓶颈。3、AMD Infinity FabricAMD 2017年随Ryzen/EPYC 首次提出Infinity Fabric,是一种专有的系统互联架构,用于促进所有连接组件之间的数据和控制传输。目前,Infinity Fabric已经进入了第四代,每条 Infinity Fabric 链路支持高达 32 Gbps 的传输速率,提供 128 GB/s 的双向带宽(跟PCIe 5.0很像呢)。 主要为环形或者网状拓扑。4、国产厂商互联技术国产芯片厂商的资料一般不公开,以下内容也是基于互联网资料整理的。华为昇腾HCCS昇腾 910B(尤其是 910B2)使用的是 HCCS 高速缓存一致性系统,相当于华为版本的 NVLink,专门用于芯片间高速通信与缓存一致性,卡间互连带宽为约 392 GB/s。华为unified bus衢定义为面向超节点(SuperPoD) 的统一互联协议,旨在将 I/O、内存访问、异构计算单元(CPU/NPU/GPU等)之间的通信融合到同一技术体系中,实现高性能、高协同、高弹性的计算基础设施。寒武纪 MLU-Link™多芯互联技术(公开资料比较老)MLU370-X8智能加速卡支持MLU-Link™多芯互联技术,提供卡内及卡间互联功能。寒武纪为多卡系统专门设计了MLU-Link桥接卡,可实现4张加速卡为一组的8颗思元370芯片全互联,每张加速卡可获得200GB/s的通讯吞吐性能,带宽为PCIe 4.0 的3.1倍,可高效执行多芯多卡训练和分布式推理任务。沐曦 MetaXLink采用自研MetaXLink高速接口,支持单机8卡全互联,显著提升多卡协同效率壁仞BLink原创BLink™高速GPU互连技术,单卡互连带宽最高达448 GB/s,并支持单节点8卡全互连燧原 GCU-LAREGCU-LARE全域互联技术是燧原专为AI训练集群研发的互联技术,提供双向300 GB/s互联带宽,支持数千张云燧CloudBlazer加速卡互联,可实现优异的线性加速比。Gen-ZGen-Z 其实是一堆行业巨头不满意 Intel 技术垄断和演进的情况下,合作搞出的新型高速互连标准,AMD、ARM、博通、Cray、戴尔 EMC、HPE、华为、IBM、联想、Mellanox (NVIDIA)、美光、红帽、三星、希捷、SK 海力士、西数、赛灵思等等都在其中,CPU,模组,网络,服务器,存储,连接器,操作系统,硬盘,FPGA的龙头老大都已经齐聚一堂,好像也看到无处不在的大陆连接器线缆龙头大哥,立迅精密.Gen-Z架构专注于提供高效率、高带宽和低延迟.Gen-Z 面向数据中心和服务器市场,是一种以内存为中心的总线结构式协议,具备高带宽、低延迟、先进工作负载、良好兼容性和经济性等优点.通过利用经过验证的装载/存储模型实现高效率。简化了Gen-Z硬件接口层,从而最大限度地减少了对软件层的需求。消除这种复杂性、开销和诱导系统延迟可以显着提高系统性能。高带宽以两种方式实现。Gen-Z支持非对称通信路径,这意味着可以将更多通道专用于读取路径而不是写入路径,反之亦然。此外,Gen-Z支持多种信令速率,包括16,25,32,56和112 GT / s,总而言之,这些功能将使Gen-Z能够跟上行业不断增长的速度需求,同时还允许将Gen-Z通信路径调整为特定的工作负载流量模式.通过减少软件堆栈来实现低延迟,与传统的服务器存储和大量分层的网络堆栈不同,Gen-Z采用轻量级软件接口,直接对硬件进行内存读写操作.Gen-Z 1.0 标准采用 PCIe 物理层和修改的 IEEE 802.3 以太网电气层标准,但在物理层上只定义了 PCIe 4.0,因此每通道速度最快只有 25GT/s,要想充分利用标准的全部性能,也必须满足 PHY 物理层面的所有规定.Gen-Z 1.1 则引入了 PCIe 5.0,每通道速度提高到 32GT/s,同时在比较宽松的技术限制下,就可以实现 Gen-Z-E-PAM4-50G-Fabric 链接,原始数据率 53.125GT/s,一切都以达到更高的传输速度、更低的延迟为目标,毕竟这也是该标准的初衷目前主流的AI算力芯片板卡(如NVIDIA、AMD、Intel的GPU/AI加速卡)均未采用Gen-Z接口。它们主要使用PCIe和厂商私有的高速互联协议(如NVLink、Infinity Fabric)。这背后是技术路线、生态锁定和成本效益等多重因素共同作用的结果。以下是详细分析:一、当前主流AI算力卡的互联接口PCI Express:行业标准与“基线”作用:这是所有AI加速卡与主机CPU、系统内存及其他设备通信的标准、必需的接口。目前主流是PCIe 5.0,正在向PCIe 6.0过渡。原因:PCIe是服务器和PC行业的通用标准,提供了必不可少的系统兼容性、枚举和基础I/O功能。任何加速卡都必须通过PCIe与主机连接。厂商私有高速互联协议:性能的“核心”NVIDIA NVLink:用于H100、B200等卡间的直接高速互联。其带宽远超PCIe(例如,H100的NVLink 4.0带宽达900GB/s),是构建多卡统一内存域、实现高效模型并行(如张量并行)的关键。它通过SXM形态或NVLink Bridge实现。AMD Infinity Fabric:在AMD Instinct MI300系列等加速卡上,用于GPU to GPU的直接高速连接,功能与NVLink类似,是AMD生态内构建多卡系统的核心。为什么用私有协议? 因为这些协议由芯片设计方深度定制,可以与自家GPU的架构(如内存控制器、缓存一致性协议)实现最优协同,达到极低的延迟和极高的带宽,这是通用标准短期内难以匹敌的。二、为什么Gen-Z未被AI算力卡采用?Gen-Z是一种以内存语义为中心的开放互连标准,旨在实现CPU、内存、加速器和存储之间的高效数据共享。它未能成为AI算力卡主流接口的主要原因如下:生态锁定与先发优势NVIDIA的统治地位:其NVLink + CUDA 生态已成为AI训练和高端推理的事实标准。客户购买H100不仅买硬件,更是购买整个软件栈和优化过的多卡通信库(如NCCL)。切换到Gen-Z意味着打破这个封闭但高效的生态,对NVIDIA和客户都无益处。AMD的路径依赖:AMD同样选择了发展自己的Infinity Fabric,并在其CPU(EPYC)和GPU(Instinct)之间通过 Infinity Architecture 进行深度集成,形成了自己的协同生态。技术定位与需求错配Gen-Z的核心优势在于内存池化和解耦,让各种设备可以像访问本地内存一样访问共享内存池。这对于某些数据中心架构(如分解式存储、内存池)很有吸引力。AI算力卡的核心需求是极致的点对点通信带宽和低延迟,以支持大规模模型并行训练。NVLink/Infinity Fabric作为紧耦合的专用互联,在为特定芯片对优化这方面,比通用的Gen-Z更有优势。成本与复杂性在主芯片(GPU)上集成额外的Gen-Z控制器会增加芯片面积、功耗和设计复杂性。在板卡和主板层面,需要增加Gen-Z所需的物理接口和线缆,这会增加系统成本和设计难度,而性能收益对于AI工作负载而言并不明确。标准竞争的结局近年来,另一个标准 CXL 在内存语义互连的竞争中逐渐占据了上风,得到了Intel、AMD、ARM及整个服务器生态链的更广泛支持。CXL基于PCIe物理层,兼容性更好,发展路径更清晰。行业焦点已从Gen-Z转向了CXL。三、未来趋势:CXL与UCIe虽然Gen-Z未成为主流,但解决内存墙和异构计算通信问题的需求依然存在,新的接口标准正在崛起:CXL:目前最受瞩目的行业标准。它运行在PCIe物理层之上,专注于实现缓存一致性的内存共享。未来,AI加速卡可能会集成CXL接口,目的不是为了卡间直连,而是为了让GPU能够更高效、更一致地访问CPU内存甚至池化内存,从而突破单卡显存容量限制。UCIe:这是一个芯片级的裸片互连标准。未来,AI算力芯片可能通过UCIe在封装内部直接与其他芯片(如CPU、专用加速器、HBM)连接,实现比板级互联更高的带宽和能效。这可以看作是“更近一步”的NVLink5.桥接器、SXM、OAM : 高速互联GPU的硬件实现这么多GPU高速互联的技术,最终都要落到实际的服务器硬件实现。第一种就是桥接器,最开始是NVIDIA 专为 PCIe GPU 而设计的物理桥接设备。它能让两个 GPU 建立直接高速连接,绕开主板的 PCIe 主干,总带宽远高于单纯依赖 PCIe 通道的多卡互联方式。后面很多其他厂商也学过去了。桥接器的好处就是,只用PCIe 服务器,就能获得高速互联,但是相对而言限制比较大,大部分可以做到2卡高速互联。要想做到单节点所有GPU全互联,就需要改变服务器的硬件形态了。以H100为例,板卡有两种形态,一种是PCIe板,一种是SXM板。SXM板集成了 H100 GPU 和 HBM3 内存堆栈,并支持第四代 NVLink 以及 PCIe Gen 5 连接,提供最优的应用性能。这种SXM卡用于英伟达的DGX/HGX平台,就是我们常说的GPU模组,这个模组里面集成了GPU、NVLink、NVIDIA 网络以及全面优化的 AI 和高性能计算 (HPC) 软件堆栈的全部功能。各家服务器厂商就根据英伟达的这个模组来开发服务器的硬件平台,大部分就是专供英伟达使用了。但是英伟达的模组都是自己私有化的,其他GPU厂商怎么办呢?2019年OCP全球峰会期间,百度宣布与Facebook、微软展开合作,联合制定OAM (OCP Accelerator Module)标准。该标准用于指导AI硬件加速模块和系统设计。2019年在美国丹佛举行的SC19全球超算大会上,浪潮正式发布全新的AI开放加速系统MX1,可在一个AI服务器支持多种符合OAM(OCP Accelerator Module)规范的AI芯片,这也是全球首个可支持多家不同型号的AI芯片直接更换的AI开放加速系统。OAM标准定义了AI加速器的统一接口,支持ASIC、GPU和FPGA等多种架构,并在物理形态、电源、连接器、引脚定义和系统架构方面提供创新设计。6. 未来演进UAlinkUALink 是 Alibaba、AMD、Apple、Astera Labs、AWS、Cisco、Google、HPE、Intel、Meta、Microsoft和Synopsys 发起。国内的一些AI 芯片厂商大概率会放弃自研的link 方式,切换到UAlink,因为实力和市场不容许。通用的UAlinkUltra Accelerator Link™ (UALink™)联盟于2024年10月注册成立,是致力于制定UALink规范的开放行业标准组织。该规范作为高速、可扩展的加速器互联技术,可提升下一代AI和高性能计算集群性能。联盟由行业领军企业组成的董事会领导,包括:Alibaba、AMD、Apple、Astera Labs、AWS、Cisco、Google、HPE、Intel、Meta、Microsoft和Synopsys。联盟制定的技术规范为新兴AI应用模式实现突破性性能提供便利,同时支持构建数据中心加速器的开放生态系统。UALink通用规范2.0为UALink技术引入网内计算,促进加速器之间的计算和通信。降低延迟、节省带宽,提升UALink系统在复杂和多工作负载环境下的AI解决方案分布式训练和推理的扩展效率。UALink 200G数据链路和物理层(DL/PL)规范2.0将DL/PL规范从UALink通用规范中拆分,使UALink能够根据行业对新型物理层和速率的需求快速迭代,无需修改其他规范。引入UALink作为具备集中控制平面和管理平面的系统。采用gNMI、Yang、SAI和Redfish等标准化协议、模型和应用程序接口。定义将UALink技术集成至基于芯粒的片上系统所需的关键信息,包括接口、外形规格、流量控制和芯粒管理标准化。完全兼容UCIe® 3.0规范,简化与现有芯粒生态系统的集成。UALink可管理性规范1.0UALink芯粒规范1.0随着UALink技术持续发展,联盟计划推出互操作性与合规项目,以支撑稳健的多厂商生态系统。欢迎有意推动UALink技术发展并参与相关项目建设的企业加入联盟,共同制定未来UALink规范。AMD 是为放弃Infinity Fabric 还是全面拥抱UAlink,AMD有这个实力。根据当前公开的技术信息和行业趋势,AMD在未来很可能会采取“双轨制”策略,即继续发展和使用Infinity Fabric作为其自家产品内部的核心互联技术,同时积极参与并推广UAlink作为跨厂商、开放生态的外部互联标准。两者并非替代关系,而是互补共存。Infinity Fabric将继续作为AMD产品架构基石Infinity Fabric是AMD自Zen架构以来为其处理器和加速器设计的专有、高性能内部互连总线。它深度集成于AMD的芯片设计中,用于连接CPU核心、CCD、IO芯片以及GPU,是实现其模块化设计和高性能的关键。放弃这一成熟且不断演进的技术(如发展到IFOP 3.0)对AMD而言既不现实也无必要。它将继续在EPYC CPU与Instinct GPU的紧耦合计算单元(如MI300X的8卡互联)中发挥核心作用。410AMD积极主导UAlink以构建开放生态对抗NVLinkUAlink的定位与Infinity Fabric不同。它是由AMD、英特尔、谷歌、微软等巨头联盟推动的开放式加速器互联行业标准,旨在为AI服务器集群中的任意品牌加速器(AMD、Intel等)提供高速、低延迟的互连方案,直接目标是打破英伟达NVLink的封闭生态壁垒。AMD是UAlink联盟的核心发起者和主推者之一,其动机在于通过开放标准吸引更多客户和合作伙伴,扩大其AI加速器的市场渗透率。因此,AMD必将大力支持并推广UAlink。2612两种技术将并存于不同场景未来AMD的产品路线图很可能呈现以下分工:内部紧密集成场景:在单机或机架内纯AMD硬件(如EPYC + Instinct MI系列GPU)构成的计算单元中,将继续优化并使用Infinity Fabric以实现最高效的內部通信。这是其性能优势所在。外部异构集群场景:在需要大规模扩展、或与其他厂商硬件(如英特尔GPU、第三方交换机)混合组网的AI数据中心集群中,AMD的加速器将支持并首选UAlink标准进行互联。这符合其开放生态战略。AMD已明确表示,其下一代机架级解决方案“Helios”将同时支持Infinity Fabric和UAlink。58结论:互补而非切换AMD不会“全面切换”到UAlink而放弃Infinity Fabric。相反,它将:对内巩固:持续投资Infinity Fabric,作为其芯片内部及自家产品组合间的高性能私有通道。对外开放:全力推动UAlink成为行业事实标准,确保其AI硬件能在多供应商环境中无缝互联,增强市场竞争力。这种策略使AMD既能保持核心技术优势,又能参与定义开放生态,是最符合其商业和技术利益的路径。对于用户而言,未来的AMDAI解决方案将根据部署环境(纯AMD栈或异构集群)灵活启用这两种互联技术。英特尔将采取“两手准备、优先自研、拥抱开放”的战略,最终会以自研技术为核心,同时积极兼容并影响开放标准(如UALink)。一、核心判断:英特尔的选择逻辑作为追赶者,必须打造差异化核心竞争力 英特尔深知,若只在通用GPU领域跟随英伟达,难以超越。其真正的差异化路线是 “XPU”异构计算,即将CPU、GPU、AI专用加速器(如Gaudi)、FPGA等通过高速互连集成。为此,自研的互联技术是其异构战略的“骨架”和核心技术壁垒,不可能完全放弃。生态建设的现实需求:必须加入开放阵营 作为市场挑战者,英特尔没有英伟达CUDA生态那样的统治力。要吸引客户(尤其是微软、谷歌等云巨头),就必须证明其产品能与现有基础设施(通常包含多厂商硬件)良好互通。加入并支持UALink这样的开放标准,是降低客户采用门槛、融入多云生态的必经之路。对于英特尔而言,自研互联技术(Xe Link, Foveros)与拥抱开放标准(UALink, CXL)不是非此即彼的选择,而是同时进行的双重战略:对内/底层:用顶尖的自研封装和互连技术(Foveros/EMIB/Xe Link)来保证其AI芯片产品的绝对性能和能效竞争力,这是与英伟达H100、AMD MI300系列正面竞争的硬实力。对外/上层:积极参与并领导CXL、UALink等开放标准,打造开放的、以CPU和通用标准为中心的异构计算生态。这既是团结盟友对抗英伟达的需要,也是其作为系统平台厂商和潜在代工厂商的长期利益所在。Unified BusUB协议在设计上旨在分层支持这四种互联场景,但其在不同层级的物理实现和性能目标有所不同。关于UB是否会全面替换华为原有的HCCS(High-Performance Computing and Communication Switching) 协议,答案是:UB是HCCS在架构上的演进和升级,预计将逐步成为华为未来全场景互联的单一协议栈,但替代过程是渐进的。技术演进关系:HCCS的定位:HCCS是华为早期自研的高速片上互联网络协议,主要用于鲲鹏CPU多核之间以及升腾NPU之间的高速互联18。它类似于AMD的Infinity Fabric或Intel的UPI,实现了多核间的一致性互联,为华为突破单芯片性能瓶颈提供了基础。UB的超越:UB不仅仅是芯片内或板级互联协议,其愿景更宏大——它旨在成为从芯片内到数据中心级别的统一互联架构。UB在协议层抽象了物理介质,可以运行在从封装内裸片链路到长距离光缆的不同物理层上10。替代的必然性与路径:架构代差:UB提供的“对等架构”和“统一内存空间”理念,比HCCS所服务的主从架构更先进,能更好地支撑超大规模智算集群10。产品路线图驱动:华为已经发布了基于UB的Atlas 950/960 SuperPoD超节点和TaiShan 950 SuperPoD通算超节点,这些新一代产品的核心互联已明确采用UB协议2711。这表明在新一代硬件平台上,UB已成为首选。生态统一需求:华为推行“硬件开放、软件开源”策略,一个统一的互联协议栈(UB)有利于降低生态伙伴的开发复杂度和成本712。过渡期安排:短期并存:在现有已部署的基于HCCS的硬件(如某些型号的鲲鹏服务器、升腾910等)生命周期内,HCCS仍将被支持。长期收敛:在2026年及之后的新一代产品(如升腾950、鲲鹏950后续型号)和超节点集群中,UB将全面成为互联基础,HCCS的角色将逐渐弱化或被整合进UB协议栈中311。结论华为Unified Bus是一个雄心勃勃的跨层级统一互联协议,旨在用一套架构覆盖从芯片到数据中心的全场景。它将不仅是HCCS的功能性替代,更是一次互联范式的升级,以适应“数据中心即计算机”的未来算力需求。因此,在华为未来的技术蓝图中,UB将成为唯一的、贯穿各级的互联主干,而HCCS将作为前期技术积累融入并最终收敛到这一主干中。NVlink这个没啥好说,英伟达为继续使用演进根据提供的搜索结果,NVLink技术自诞生至今的演进路线清晰展现了英伟达从构建高速GPU间互联到打造超大规模AI集群网络的雄心。其核心路径是从机内点对点互联演变为跨机箱的网络化超级互联。以下是其主要的演进阶段与关键里程碑:第一阶段:奠基与内部互联 (2016-2017)这一阶段的核心目标是突破PCIe瓶颈,在单台服务器内实现GPU间的高带宽直接通信。首发:NVLink 1.0 - 随Pascal架构(P100 GPU)推出。每块GPU配备4个端口,每个端口由8个速率为20 Gbps的通道组成,单端口双向带宽40 GB/s,单卡总带宽160 GB/s,在当时达到PCIe 3.0带宽的5-10倍。它实现了GPU间的点对点直接内存访问。1389第二阶段:规模化与拥抱CPU (2017-2020)目标从单个连接扩展到多GPU系统全互联,并开始将CPU纳入高速互联生态。NVLink 2.0 / NVSwitch 1.0 - 随Volta架构(V100 GPU)推出。单卡端口数增至6个,单通道速率提升至25 Gbps,单卡总带宽翻倍至300 GB/s。关键的创新是引入了NVSwitch交换芯片(最初18端口),首次实现了8个GPU间的全连接(Full Mesh),并开始支持与IBM POWER CPU的缓存一致性连接。239NVLink 3.0 / NVSwitch 2.0 - 随Ampere架构(A100 GPU)推出。单卡端口数大幅增至12个,采用更高速的50 Gbps通道(每端口4通道),总带宽再次翻倍至600 GB/s。NVSwitch升级至36端口,并支持通过背对背连接组建16卡全互联系统(如DGX A100)。269第三阶段:迈向超级网络 (2022年至今)技术定位从“内部互联”升级为可与InfiniBand竞争的独立网络设备,支撑千卡级AI集群。NVLink 4.0 / NVSwitch 3.0 - 随Hopper架构(H100 GPU)推出。单卡端口数达18个,采用PAM4调制实现100 Gbps通道速率(每端口2通道),单卡总带宽高达900 GB/s。NVSwitch 3.0支持64个端口,并集成了用于集合通信优化的SHARP功能。更重要的是,NVLink Network开始支持通过OSFP光模块进行机箱间的连接,实现了“单一节点”概念的巨大扩展。12469未来:NVLink 5.0及生态系统开放 - 根据路线图,下一代预计采用200 Gbps通道速率,带宽将继续提升。更重大的趋势是英伟达推出NVLink Fusion项目,计划通过IP授权方式,允许第三方厂商(如Intel, Arm, SiFive RISC-V)的CPU或其他加速器接入NVLink网络,旨在构建一个以NVLink为核心、更开放的异构计算生态。1710演进规律总结性能跃进:单通道速率按“20G→25G→50G→100G→200G(预计)”翻倍提升,同时通过增加单卡端口数(4→6→12→18→24预计)实现总带宽的指数级增长。79架构变革:从点对点连接,到引入NVSwitch实现全互联,最终演变为支持光电混合的跨机箱网络。145生态扩张:从专为NVIDIA GPU设计,到逐步开放生态,试图成为未来高性能计算和AI集群的统一互联标准。1011总而言之,NVLink的演进路线清晰地反映了AI计算对互联带宽和规模的需求增长,其发展已超越了单纯的GPU互联技术,成为定义现代超大规模AI基础设施架构的关键基石。PCIePCIe互联在高性能训练场景中的劣势PCIe在算力卡互联中的劣势主要体现在带宽和延迟上,使其难以胜任大规模AI训练任务。在高性能计算场景,尤其是需要多卡紧密协同的大模型训练中,PCIe的共享总线架构与NVLink等专用互联技术存在本质差距。NVLink专为GPU间高速直连设计,提供高达数百GB/s的带宽和微秒级延迟,并支持全互联拓扑;而PCIe最初为外设互联设计,用于多卡通信时带宽有限且延迟较高。例如,RTX 4090集群通过PCIe 4.0互联时,有效P2P带宽仅为理论值的12.5%-18.75%,8卡分布式训练AI模型时通信延迟可达NVLink方案的3.6倍,导致GPU利用率暴跌和大量算力空转。因此,在追求极致效率的数据中心训练场景,纯PCIe互联的算力卡难以与配备NVLink的专业卡竞争。139PCIe在推理、边缘及灵活部署场景中的优势尽管在高性能训练中存在瓶颈,但PCIe凭借其通用性、灵活性和成熟的生态,在推理、边缘计算和企业级部署中仍有显著优势与前途。PCIe接口具有极强的通用兼容性,无需改造服务器架构即可便捷部署,大幅降低了AI算力导入的门槛与成本。这在推理、轻量级训练、工业自动化等场景中至关重要,因为此类任务对通信带宽的要求相对较低,更注重部署的灵活性与经济性。同时,PCIe提供灵活的链路宽度(×1到×16),带宽代际演进清晰(目前已至PCIe 5.0/6.0),能适配不同算力等级的需求。在汽车等新兴领域,PCIe的超低延迟、高可靠性和直接内存访问优势,使其成为实时性要求高的边缘互连方案的补充。因此,专注于推理市场或采用非GPU架构的AI加速卡,完全可以依赖PCIe获得成功。257市场多元化与国产化带来的新兴机会在全球算力市场多元化与供应链自主可控的趋势下,仅使用PCIe互联的算力卡正迎来新的发展机遇。随着美国对高端AI芯片的出口限制,中国市场加速推动国产算力发展。许多国产AI芯片企业,如平头哥、寒武纪、燧原科技等,其产品主要通过PCIe形态切入市场。这些芯片在性能上可能不及顶级国际产品,但凭借PCIe的通用接口,能快速适配现有服务器,满足企业级推理、工业计算等广泛需求。此外,PCIe交换芯片作为算力网络的神经枢纽,在国产化进程中地位关键,其发展支撑了全国一体化算力网的建设。这意味着,在特定市场区域和差异化应用场景中,纯PCIe互联的算力卡不仅具有前途,而且是实现供应链安全与成本控制的重要路径。6810未来演进:CXL融合与专用交换芯片提升潜力PCIe互联的未来前途与其技术演进紧密相关,尤其是通过与CXL协议的融合以及专用交换芯片的智能化发展,PCIe有望突破传统外设接口的局限。未来,PCIe加速卡将随异构计算架构普及和CXL协议成熟进入新发展阶段。CXL建立在PCIe物理层之上,支持缓存一致性与内存池化,这将使通过PCIe连接的加速卡从外设转变为对等计算单元,大幅降低数据搬运开销。同时,专为PCIe优化的交换芯片正朝着超低延迟、CXL融合及光电共封装方向发展,以解决大规模集群的内部通信瓶颈。这些演进将使PCIe互联不仅能继续服务边缘与推理市场,更有潜力参与更复杂的异构计算任务,保持其作为通用高速互连基石的长期价值。
-
AI专题十四:大模型运行和多用户支持 1 一台服务器的部署的一个大模型同时支持多个用户的同时进行推理的原理是什么?多个用户同时使用不会造成计算混乱吗?核心原理:模型是“静态”的,请求是“动态”的你可以把训练好的大模型想象成一个巨型的、复杂的、只读的数学函数(参数文件)。这个函数本身是固定的,不会因为不同人使用而改变。多个用户的并发使用,实际上是依次或并行地向这个“函数”传入不同的输入数据(即用户的提问),并各自得到独立的输出。技术实现的关键点:服务化与请求队列模型被封装成一个推理服务。当多个用户同时发送请求时,这些请求会进入一个请求队列。服务端有一个调度器负责从队列中取出请求,组织计算。计算图与批处理这是并发的核心技术。服务器在加载模型时,会将模型结构预先编译成一个高效的静态计算图(尤其是在使用TensorRT、Triton等推理优化框架时)。批处理:调度器不会一次只处理一个请求,而是会将短时间内收到的多个请求(即使来自不同用户)组合成一个“批”,一次性送入GPU进行计算。例如,用户A的“写一首诗”和用户B的“翻译一句话”这两个请求,可能被组合成一个批次(batch size=2)输入模型。优势:GPU拥有数千个核心,擅长并行计算。批处理能极大地提高GPU的利用率和吞吐量,让硬件“吃饱”,从而服务更多用户。这就像烤箱一次烤10个面包,远比一个一个烤高效。内存与上下文隔离这是解决“混乱”问题的关键。模型参数共享:所有用户共享同一份模型参数,它们常驻在GPU显存中,只读,不会互相影响。计算上下文独立:每个用户的请求都有自己独立的内存空间,用于存储其输入的词元、计算过程中产生的中间激活值、以及独有的对话历史(KV Cache)。服务器框架会为每个请求维护独立的上下文,确保用户A的数据绝不会混入用户B的计算中。分时复用与流式输出分时复用:对于无法组成批次的请求,或者长序列请求,调度器会采用分时策略,快速在多个计算任务间切换。由于GPU计算速度极快,给用户的感知仍然是“同时”在响应。流式输出:为了提升用户体验,模型通常以流式方式逐个词元生成文本。服务器可以同时管理多个这样的“流”,分别推送给不同的用户。一个简单的比喻:中央厨房将大模型服务器比作一个高度自动化的中央厨房:模型:就是厨房里固定不变的、复杂的菜谱(函数)和厨具设备(GPU)。厨师(GPU核心):可以同时处理多份订单。订单(用户请求):来自不同顾客。批处理:厨师一次性腌制10块牛排(一个批次),而不是一块一块地腌,效率大增。隔离:每份订单都有独立的餐盘和包装,绝不会把顾客A的酱汁打到顾客B的菜里。调度器:是餐厅经理,负责接收订单、安排厨师工作、将做好的菜分送给正确的顾客。总结:为什么不会混乱?状态隔离:每个用户的会话和计算上下文在内存中是逻辑隔离的。参数只读:模型本身作为基础模板,不被任何单一请求改变。有序调度:通过请求队列、批处理、分时等调度技术,系统有条不紊地处理并发请求,最大化硬件效率。专用框架:使用如 vLLM, TGI, Triton Inference Server 等专业推理服务器框架,它们正是为高效、稳定地处理高并发推理场景而设计的。所以,单个模型不仅能被多人同时使用,而且通过并发技术,服务提供商还能显著降低单次推理的平均成本,这正是AI服务能够大规模商业化的技术基石。2 一台服务器的部署的一个大模型支持的最大同时使用的用户数量是有哪些因素决定的?一台服务器能支持的最大并发用户数(或并发请求数)是一个性能容量规划问题,没有单一公式可以直接算出,但可以通过系统化的方法来估算。它取决于硬件、模型、工作负载和服务质量(QoS)四大类因素的复杂交互。以下是你提到的 32张H100服务器(假设为戴尔PowerEdge,搭配高速互联) 场景下的关键决定因素和估算方法。一、 四大决定因素硬件极限GPU算力(FLOPs):H100的FP16张量核心峰值算力极高,但实际利用率取决于模型和优化程度。推理通常是内存瓶颈或通信瓶颈,而非算力瓶颈。GPU显存(容量与带宽):这是最硬性的约束。模型参数、KV缓存、激活值、批处理数据都存储在显存中。参数占用:例如,一个70B参数的FP16模型需要约140GB显存。KV缓存占用:这是大模型推理的“内存杀手”。每个并发请求的序列越长,KV缓存占用越大。公式大致为:2 层数 隐藏维度 序列长度 批大小 * 精度(字节)。这直接限制了能同时“保持活跃”的请求数。HBM带宽:自回归生成是“内存带宽受限”操作,每次生成一个token都需要从显存读取整个模型参数(或大部分)。因此,显存带宽决定了生成token的极限速度。互联带宽:在32张卡上进行张量并行或流水线并行时,GPU间的通信(NVLink, NVSwitch)可能成为瓶颈。通信开销会降低计算效率。模型特性参数量与架构:模型越大,单次前向传播的计算量和内存占用越大。优化程度:量化:使用FP8或INT4量化,可以将参数和激活值占用的显存减半或更多,从而显著增加并发容量。内核融合/定制化内核:使用像FlashAttention这样的优化内核,可以减少内存访问、提升速度。连续批处理/动态批处理:这是现代推理服务器(如vLLM, TGI)的核心功能。它允许不同请求的序列被高效地打包在一个批次中,动态更新KV缓存,极大提升GPU利用率和并发支持数。工作负载特征(用户行为)请求到达模式:是平稳流还是突发高峰?输入长度(Prompt Tokens):用户提问的长度。输出长度(Generation Tokens):模型回复的长度。这通常更重要,因为生成是自回归的,每个输出token都需要一次完整的前向传播。请求频率:单个用户在收到上一个回复后,多快会发送下一个请求?服务质量要求延迟(Latency):用户能容忍的响应时间。首Token延迟(TTFT):从发送请求到收到第一个token的时间。这受批处理等待、计算初始提示影响。Token间延迟(TPT):后续每个token的生成速度。高延迟容忍度意味着系统可以积累更大的批处理尺寸,从而提高吞吐量和并发用户数。反之,低延迟要求会限制批处理大小,降低并发能力。二、 估算方法与步骤(以70B模型为例)这是一个从吞吐量倒推并发用户数的简化流程。你需要先设定目标延迟和典型用户行为模式。步骤1:确定单次请求的“计算负载”假设一个典型请求:输入长度(I): 512 tokens输出长度(O): 256 tokens总处理量: 模型需要为这个请求计算 I + O 次前向传播(实际上,计算提示是一次性并行计算I个token,生成则是串行进行O次)。但更关键的指标是 “每用户每秒处理的Token数(Token/s/user)”。步骤2:测量系统在目标延迟下的最大吞吐量这是必须通过实际基准测试得到的核心数据。你需要:将70B模型以最优的并行策略(如张量并行TP=8,即8张卡服务一个模型实例)部署在32张H100上。那么你可以运行 4个这样的模型实例(32/8=4),每个实例独立处理请求,实现多副本并行以提高总吞吐。使用基准测试工具,模拟不同并发请求数,测量在满足目标延迟(如TTFT < 2s,TPT < 50ms) 的前提下,整个系统(4个副本)的:总吞吐量(Throughput): 单位是 Tokens/秒。假设:在目标延迟下,测得系统总吞吐量为 T_total = 40,000 Tokens/秒。步骤3:定义典型用户场景假设每个用户的平均请求间隔(从收到完整回复到发送下一个请求)为 R 秒。例如,一个聊天机器人场景,用户平均每10秒发送一条新消息。那么:每个用户对系统的平均需求吞吐量 = (I + O) tokens / R seconds。以上述数字为例:每个请求总tokens为768,R=10秒,则每用户平均需求吞吐 = 76.8 Tokens/秒/用户。步骤4:计算最大支持用户数理论最大并发用户数 = T_total / (每用户平均需求吞吐) = 40,000 / 76.8 ≈ 521 用户。这是平均情况。如果所有用户同时发送请求(突发),系统需要使用队列,并且瞬时并发请求数会受到KV缓存容量和调度器的限制。步骤5:用KV缓存容量进行校验这是更硬性的即时约束。假设:模型层数 L=80,隐藏维度 H=8192,使用FP16存储KV缓存(2字节)。系统为每个请求分配的最大序列长度为 2048 tokens。单张H100 80GB显存中,除去模型参数和其他开销,可用于KV缓存的空间约为 50GB。则单张GPU上能同时活跃的请求数(批大小)上限为: KV缓存容量 / (2 L H 序列长度 2字节) = 50GB / (2 80 8192 2048 2) ≈ 50e9 / (5.36e9) ≈ 9个请求。如果你使用TP=8,那么一个模型实例(跨8张卡)的批大小上限也大致是这个数量级(因为KV缓存是并行分散的)。那么4个副本的总瞬时并发请求数上限约为 9 * 4 = 36个。这里出现了关键区别:吞吐量估算的用户数(521):是随时间平均的用户数,系统通过快速处理请求,在1秒内可以服务很多用户,但不是同时。KV缓存限制的并发数(36):是同一时刻正在被处理(处于生成过程中)的活跃请求数。在连续批处理调度下,系统会在极短的时间窗口(毫秒级)内循环处理这些活跃请求,快速切换上下文。因此,系统能支持的总在线用户数可以远高于36,只要他们的请求不是严格同时到达,而是错开的。36代表的是系统的“瞬时并发处理深度”。三、 结论与公式提炼对于你的32张H100服务器,支持的最大同时在线用户数(满足一定响应延迟)取决于:瞬时并发硬上限: 瞬时并发请求数 ≈ (总GPU显存可用于KV缓存的部分) / (单个请求的KV缓存占用) 这由模型架构、序列长度和GPU数量决定。可持续吞吐软上限: 平均支持用户数 ≈ (系统在目标延迟下的总吞吐 Tokens/秒) / (每个用户的平均Token需求速率 Tokens/秒/用户) 这由GPU算力/带宽、优化程度、用户行为模式决定。实际生产中:你会先用KV缓存容量估算出瞬时并发批处理大小(例如36)。然后通过基准测试,测量在这个批处理大小下,系统的吞吐量(Tokens/秒)和延迟。最后根据用户行为模型,计算能支持多少用户。给你的直接建议: 如果你想估算32张H100对特定模型(如Llama3 70B)的容量,可以:查找该模型在类似硬件(如8xH100)上的公开基准测试数据(vLLM、NVIDIA TensorRT-LLM等发布的Benchmark)。关注其 “每秒生成Token数” 和 “支持的最大并发请求数” 指标。按比例(4个副本)进行外推,并结合你的业务场景用户模型进行计算。最终,真实的容量必须通过在生产负载下的压力测试来验证,因为用户行为往往是不可预测的,且软件栈的优化水平对性能有巨大影响。3 多个用户同时使用时,状态隔离:每个用户的会话和计算上下文在内存中是逻辑隔离的;有序调度:通过请求队列、批处理、分时等调度技术 , 这些机制是在哪里实现的?是AI 服务器的操作系统?还是GPU的kernel 还是什么软件代码?您提到的这些机制,是由一整套分层的软件栈协同实现的,从高层的应用框架一直到底层的硬件驱动。没有一个单一组件(如操作系统或GPU内核)能独立完成这一切。下面我为您拆解这些机制具体在哪里实现:一、状态隔离的实现层状态隔离的核心是为每个请求独立管理其对话历史(KV缓存)和计算中间状态。推理框架/服务器层(如vLLM、TGI、Triton)这是实现逻辑隔离的核心层。 框架会为每个进入系统的请求创建一个唯一的“请求句柄”或“序列对象”。该对象内部维护着该请求专属的:输入Token IDs已生成的输出Token IDs指向其独占的KV缓存内存块的指针。在像vLLM这样的框架中,其核心创新PagedAttention技术,就像操作系统的虚拟内存管理器一样,将不同请求的KV缓存分配在不同的、可独立换入换出的“内存页”中,从物理存储上就保证了隔离。GPU内核与运行时层当框架发起一次批处理计算时,它会告诉底层计算内核(Kernel):“这是批处理A,包含用户1、用户2、用户3的数据,他们的KV缓存地址分别在X、Y、Z。”定制化的GPU计算内核(如FlashAttention的变体) 在计算注意力时,会根据框架传入的地址,精确地从显存的不同位置读取属于每个请求的KV缓存,并在计算后写回原处。内核代码本身被设计为能根据索引正确处理批次中不同序列的数据。二、有序调度的实现层调度是将无序、海量的用户请求转化为高效、有序GPU计算指令的过程。调度器(Scheduler) - 位于推理框架内这是调度的大脑,是框架代码的一部分(如vLLM的Scheduler模块)。它维护着多个队列:等待队列:存放新到达的请求。运行队列:存放正在被预填充(处理Prompt)或生成(Generation)的请求。交换队列:管理因显存不足而暂时被换出到CPU内存的请求状态。它做出所有关键决策:何时进行批处理(Batching):等待一小段时间(例如几毫秒)以收集更多请求,组成更大的批次,提升吞吐量。批次的构成(Continuous Batching):这是现代框架的核心。它不会等一个请求完全生成完再处理下一个,而是动态地将新请求加入批次,同时将已生成完成的请求移出批次。这就好像餐厅经理不断安排新顾客入座,同时给吃完的顾客结账。何时抢占或交换:当高优先级请求到来,或显存不足时,决定暂停或换出哪些低优先级请求。GPU内核与硬件执行调度器决定“做什么”(批次的构成),而GPU硬件负责“快速地做”。GPU收到一个计算批次后,其数千个核心会并行地执行相同的指令(SIMT架构),但处理批次中不同序列的不同数据。分时(Time-sharing) 的效果,本质上是由调度器快速提交多个小的计算任务到GPU的命令队列(CUDA Stream)中,由GPU硬件高速串行执行而宏观上并发的。GPU计算速度极快(微秒级),这种切换对用户来说就是“同时”。三、技术栈全景图我们可以用一个从高到低的层次来看:总结与类比操作系统(OS) 就像是场地和基础服务提供商:它提供了建筑(内存空间)、电力(CPU调度)、物流通道(网络和PCIe总线)。但它不懂“烹饪AI模型”这个业务。推理框架(如vLLM) 就像是中央厨房的智能管理系统和经理:它设计工作流(调度)、管理食材库存(显存)、为每个订单分配独立的厨具和餐盘(状态隔离),并指挥厨师工作。GPU内核 就像是高度专业化、训练有素的厨师团队:他们严格按照工作指令(内核代码),同时、快速、精准地处理多个订单(批处理)中的不同步骤。因此,您所问的状态隔离和有序调度,其智能和逻辑核心是在“推理框架层”(如vLLM)中实现的。它充分利用了底层操作系统和GPU硬件提供的基础能力,但赋予了它们理解大模型并发推理这一特定业务场景的“智慧”。正是这些专用框架的出现,才使得大模型的高效、高并发服务成为可能。4 推理框架(如vLLM) 是在AI 服务器哪里实现的,操作系统安装某个推理框架(如vLLM) 的应用app 包吗?还是什么调度机制在哪里实现?您可以将推理框架看作是为大模型推理这个特殊任务而专门构建的一个高度特化的“智能操作系统”或“超级后台服务”。它运行在服务器的基础操作系统之上,但管理着GPU这个“第二王国”的一切。下面我为您具体拆解它在哪里、以及如何实现:一、推理框架是什么,安装在哪里?它不是操作系统的一部分,也不是一个简单的“应用商店APP”。像 vLLM, TensorRT-LLM, TGI 这样的推理框架,本质上是一个用Python/C++编写的、复杂的软件项目(或“服务程序”)。您通过服务器的命令行终端,使用Python包管理器(如 pip)或容器技术(如 Docker)将其“安装”到系统中。安装后,它是一系列可执行脚本和库文件,就像您安装了Nginx或MySQL数据库服务一样。它的运行形态:一个长期运行的守护进程当您启动服务时,通常会执行一条类似 python -m vllm.entrypoints.api_server --model=xxx 的命令。这会启动一个持续的进程。这个进程会:加载您指定的大模型权重文件到GPU显存。启动一个HTTP服务器(如FastAPI)监听特定端口(如8000),等待用户请求。初始化其核心的调度器、内存管理器等组件,并常驻内存,7x24小时运行。二、调度机制具体在哪里实现?这是最关键的部分。我们可以分层来看:第1层:用户空间应用层 - “调度决策中心”位置:在vLLM进程的内存空间里,具体是它的 Scheduler 和 Worker 等核心类的Python/C++代码中。功能:这是调度的“大脑”,负责高级决策。请求队列:当HTTP服务器收到用户请求后,将其转化为一个Request对象,放入Python代码中维护的等待队列。调度策略:调度器的代码逻辑(例如,vllm/core/scheduler.py)会周期性地检查队列,根据预设策略(如FCFS先来先服务,或是否优先处理短请求)决定:从等待队列中取出哪些请求。将它们与当前正在生成的请求动态组合成一个新的批处理。决定哪些已完成的请求该移出。内存管理:其PagedAttention内存管理器(同样是vLLM的Python/C++代码)负责为这个新批次中的每个请求分配或查找物理显存块,用于存储KV缓存,确保完全隔离。第2层:计算图与运行时层 - “命令编制部”位置:在PyTorch、CUDA Graphs或框架自有的引擎中。功能:调度器做出“要处理A、B、C用户请求”的决策后,需要将决策转化为GPU能执行的具体计算。框架会为这个特定的批次(包含不同长度、不同内容的请求)动态编译或调用一个预编译的计算图。这个计算图会精确地包含从显存哪个地址读取用户A的KV缓存,哪个地址读取用户B的输入等“低级指令”。第3层:GPU内核与驱动层 - “执行工厂”位置:在GPU上运行的定制化内核(Kernel)代码中。功能:这是调度的“肌肉”,负责最终执行。计算图最终会调用一系列高度优化的GPU内核函数(例如用CUDA C++编写的FlashAttention内核)。这些内核被设计为支持批处理:它们内部有逻辑,能根据一个“序列ID”或偏移量参数,在同一时间内,但为批次中不同的序列进行正确的计算。内核代码保证了计算在数学上的正确性和隔离性。分时的实现:当调度器快速连续地提交多个小批次任务到GPU的命令队列时,GPU硬件会以极高的速度串行执行它们,宏观上实现了并行。这是由NVIDIA驱动和GPU硬件调度器在纳秒/微秒级别完成的。三、一个简化的运行流程图用户请求 -> 网络 -> 服务器端口 ↓[vLLM 进程 - 常驻内存] ↓HTTP服务器接收请求(FastAPI代码) ↓放入内部等待队列(Python列表/队列对象) ↓核心调度器(Scheduler类)被触发决策:将请求A、B、C组成一个新批管理:为A、B、C分配独立的KV缓存页 ↓构建计算图(调用PyTorch/CUDA)输入:批数据 + A/B/C的KV缓存地址 ↓启动GPU内核执行GPU内核:并行计算,但数据各安其位 ↓获取结果,返回给对应HTTP连接四、重要总结:为什么不是操作系统内核?职责不同:操作系统内核(如Linux Kernel)的通用调度器,调度的是进程和线程这种通用计算单元。它对“大模型推理”、“KV缓存”、“自回归生成”这些领域特定知识一无所知。效率与灵活性:在用户空间实现的调度器(如vLLM的),可以用Python/C++快速实现复杂的、针对LLM优化的调度策略(如连续批处理、内存换入换出),并随时调整,无需修改操作系统内核。访问硬件:推理框架通过CUDA驱动API这个“特权通道”直接与GPU对话,绕过了操作系统对计算细节的管理,实现了极致性能。所以,答案是: 推理框架(如vLLM)是安装并运行在操作系统之上的一个独立的、专门化的后台服务进程。它最核心的调度机制,是在这个进程内部,由其自身用高级语言(Python/C++)实现的逻辑代码来完成的。 它就像是在通用操作系统之上,为AI计算这个特定领域建立的一个“自治王国”,拥有自己的法律(调度策略)、资源管理方式(显存分页)和军队(GPU内核)。5 一个AI服务器的一个大模型其实在同一时刻其实只有一个人使用是吗? 多个用户是按照时间片划分看起来在同时使用,如果使用用户过多,调度不过来,就需要排队?它不是纯粹的时间片轮转,而是两者的结合:既有真正的物理并行,也有时间上的交错。核心答案:既是“并行”,也是“交错”,排队是必然的“同一时刻只有一个人使用”是错误的现代GPU(如H100)拥有成千上万个核心,其设计初衷就是为了并行计算。推理框架通过批处理技术,会将多个用户的请求数据(输入的Token、各自的KV缓存)物理上打包成一个批次,一次性送入GPU。在这个批次的前向传播计算过程中,GPU的硬件是同时在为所有请求进行计算。例如,计算注意力分数时,矩阵运算会并行处理批次中的所有序列。所以,在计算微观层面,GPU确实在同一时刻为多个用户工作。“时间片划分”体现在哪里?关键在于自回归生成的过程。模型生成文本是一个“猜下一个词”的循环过程:第一步(预填充):并行处理整个批次中所有用户的输入提示(Prompt)。这是高度并行的。第二步(生成):为每个用户逐个生成输出Token。这个过程是交错并行的:调度器会执行一次前向传播,为批次中的所有活跃请求各生成一个Token。然后,将已生成完毕的请求移出批次,加入新的请求,再执行下一次前向传播。从每个用户的感受上看,他们是轮流收到下一个词的(例如用户A收到第1个词,用户B收到第3个词),宏观上像是“时间片”。但从GPU的视角看,每一次前向传播都是同时在为多个请求工作。“调度不过来,就需要排队”是完全正确的这发生在两个层面:进入运行队列前的排队:当新请求到达速率超过调度器能将其加入运行批次的速度时,请求会在等待队列中排队。KV缓存容量导致的排队:这是更根本的限制。GPU显存中能同时保存的“活跃请求”的KV缓存总数是有限的(如之前计算的,可能只有几十个)。一旦超过这个数,新请求就必须在等待队列中排队,直到有活跃请求完成、释放出其KV缓存空间后,才能被调度进来。一个更精确的比喻:中央厨房的炒菜流程延续之前的比喻:批处理(并行):厨师(GPU)同时将10份订单(一个批次)的牛排放进同一个大火炉(并行计算)烹煮。这是物理上的同时处理。交错生成(时间交错):每份牛排需要煎5分钟。厨师不是等一份煎完再煎下一份,而是同时开煎。但出锅时,由于订单要求不同(有的要5分熟,有的要7分熟),牛排会按各自的时间线依次出锅(对应每个请求流式输出Token)。排队:如果瞬间来了100份订单,厨房最多只能同时处理10份。另外90份就在订单接收区(等待队列)排队。只有当前面10份中的某份完成出锅、腾出了炉位,排队中的订单才能进入烹饪区。总结所以,实际情况是:GPU计算是并行的:硬件在同一时刻处理多个请求的数据。生成输出是交错并行的:每个请求按自己的序列逐个获得Token,宏观上像是轮流服务。排队不可避免:由于硬件资源(显存、算力)有限,当并发需求超过系统吞吐量或KV缓存容量上限时,排队必然发生。这正是为什么我们需要评估系统“最大支持用户数”的原因——这个数字本质上就是在可接受延迟下,系统能处理的平均请求速率。因此,您可以说“多个用户是共享同一个模型的计算资源”,但不是简单的单核CPU时间片轮转,而是更高效的、并行与交错相结合的高级调度。排队是系统保护自身、保证服务质量的自然机制。5 那就是GPU 在设计之初就支持多进程同时计算,这些进程的数据互补干扰,是这样吗?这是一个非常关键的问题。您的理解方向是正确的,但需要更精确地澄清“进程”和“干扰”的含义。GPU的并行能力:硬件基础GPU在设计之初的核心思想就是大规模并行计算。它拥有数千甚至上万个小而高效的计算核心(CUDA Core/Tensor Core),这些核心被组织成多个流多处理器(SM)。其架构擅长执行 “单指令,多线程” 的任务,即让大量核心同时执行相同的操作,但处理不同的数据。多进程与数据隔离:软件实现GPU硬件本身并不理解“进程”这个概念。数据隔离和不干扰是由软件栈(驱动、运行时、框架) 在硬件提供的并行能力之上实现的。多进程同时使用GPU:是的操作系统可以启动多个应用程序进程,每个进程都可以通过CUDA驱动向GPU提交计算任务。GPU硬件和驱动有能力快速切换、交错执行来自不同进程的计算任务(通过CUDA Stream等机制)。宏观上,多个进程“同时”在使用GPU。数据互不干扰:需要软件精心管理GPU本身不保证隔离:如果两个进程的程序错误地访问了相同的显存地址,数据就会互相干扰、覆盖。隔离是由软件层保障的:CUDA驱动/运行时:它为每个进程(或上下文)提供虚拟化的显存地址空间和管理,类似于操作系统为进程管理内存。这奠定了隔离的基础。推理框架(如vLLM):这是实现业务逻辑层面隔离的关键。它在上述基础之上,更进一步:会为每个用户请求精确分配独立的显存区域来存储其独有的KV缓存和中间数据。在启动GPU计算内核时,会传入精确的参数,告诉内核“请求A的数据在地址X,请求B的数据在地址Y”。内核代码则根据这些参数,确保在并行计算过程中,核心们处理的是各自正确的数据块,不会交叉混淆。一个技术层面的类比GPU硬件 像一个巨大的印刷厂,有成千上万个相同的印刷机(核心)。CUDA驱动 像印刷厂的调度员,可以接收来自多个客户(进程)的订单,并安排印刷机工作。推理框架 则像一个超级客户,它有一个大订单(运行大模型)。但它内部又把这个大订单拆分成无数个子订单(用户请求),并为每个子订单指定了专用的纸张和油墨(显存空间)。它告诉调度员:“请用印刷机同时印刷子订单A和B,但A用左边仓库的纸,B用右边仓库的纸。”印刷机(GPU核心)虽然同时运转,但因为拿的纸张和油墨来源不同,最终产品不会混淆。结论所以,答案是: 是的,GPU硬件设计支持并行计算,允许多个进程或任务同时利用其核心。但“数据互不干扰”并非由GPU自动保证,而是通过CUDA软件栈和上层推理框架(如vLLM)的精细内存管理和调度逻辑来实现的。 硬件提供了并行执行的“肌肉”,软件则提供了正确组织工作、避免混乱的“大脑”。因此,在您提到的AI服务器场景中,多个用户同时使用不会造成计算混乱,正是得益于这套从硬件底层到软件顶层的完整协作体系。
-
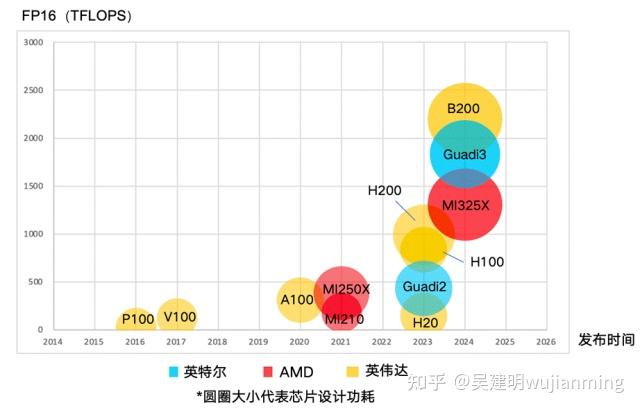
AI专题十三:地球上算力芯片参数汇总、整理、对比 摘自:https://zhuanlan.zhihu.com/p/1908027882829244313前言:AI大模型能力的快速提升(如Qwen3、Llama4的多模态升级与逻辑推理优化)正推动AI从辅助工具向核心生产力渗透。而算力芯片的性能对大模型的训练、推理至关重要。本文通过统计全球主要算力芯片的算力、显存和互联带宽指标,对比海外第三方设计公司、海外大厂自研和国产芯片的单卡性能。不考虑软件(如CUDA)、Scale out架构(如华为CloudMatrix超节点)和成本。华为芯片缺少官方公布数据,所有暂时没有收录。英伟达、英特尔、AMD英伟达的芯片覆盖最广,包括高性能的H100、H200和B200,以及较早的V100、P100等,其产品线在算力和迭代速度均占据领先地位。英特尔的AI芯片为Guadi系列(如Guadi3),而AMD是MI系列(如MI325X、MI250X)。从时间线看,英伟达迭代速度最快,2023年后密集发布新品;AMD的MI300系列和英特尔的Guadi3则瞄准了同期的英伟达B200竞争。功耗设计上,英伟达B200的圆圈显著更大,凸显其高功耗高性能定位。美国互联网大厂谷歌的TPU系列最为成熟,从v2到v7p逐步提升算力,其中v5p和v7p的能效比设计突出;亚马逊的Trainium3、Meta的MTIA v2和微软的Maia 100是较新的竞争者,发布时间集中在2023-2024年。这些芯片的算力普遍低于英伟达旗舰(如TPU v7p的FP16性能接近B200),但功耗更低(圆圈较小),反映其优化能效的特点。谷歌的TPU发布时间跨度大,显示其长期投入,而Meta、亚马逊和微软的布局更晚但速度迅猛。国产芯片寒武纪的思元590、海光信息的BW100和沐曦科技的曦云C500在算力和功耗上领先,发布时间集中于2023-2024年。整体来看,国产芯片的算力水平与英伟达中端产品(如A100)接近,但功耗控制更分散(圆圈大小差异大),反映技术路线多样性。发布时间显示2020年后中国AI芯片进入爆发期,但国际巨头仍保持性能代差。一、算力指标制程:海外:第三方设计公司:为后续产品制程的升级预留了空间。英伟达最新的Blackwell系列使用了TSMC 4NP,相当于4nm高性能版本。AMD、英特尔最新产品的制程都是5nm。Groq为了追求性价比,使用GlobalFoundries的14nm。大厂自研:谷歌最新的TPU Ironwood(TPU v7p)和亚马逊的Trainium3都使用了最先进的3nm,Meta和微软使用了5nm。中国大陆:国内厂商在受到制裁之前,旗舰产品绝大多数都是使用TSMC 7nm。目前正在转向中芯国际7nm。燧原科技的所有产品都采用GlobalFoundries 的12nm工艺。晶体管数量/芯片面积/晶体管密度:芯片面积:由于掩膜版的尺寸,单个芯片最大曝光区面积限制为858mm²,可以通过Chiplet构建更大的芯片。晶体管密度:更高的晶体管密度允许在相同芯片面积内集成更多计算核心,直接提升并行计算能力。海外:第三方设计公司:英伟达的B200首次使用了Chiplet技术,包含了两个B100 Die,两个Die通过NV-HBI互联,芯片面积达到1600mm²,晶体管密度达到130百万/mm²。AMD的芯片一直都采用Chiplet,由许多小芯粒组成大芯片,芯粒之间通过Infinity Fabric互联.大厂自研:谷歌最新的TPU Ironwood(TPU v7p)晶体管密度达到了308 百万/mm²,是英伟达Blackwell的两倍多。TPU v6e和微软的Maia 100分别达到110百万/mm²和128百万/mm²。中国大陆:国内厂商多使用Chiplet技术,增强算力、降低成本。燧原科技2021年发布的邃思2.0的芯片面积3306 mm²,采用GlobalFoundries 12nm工艺,号称中国最大AI单芯片,达到了日月光 2.5D 封装的极限。各浮点运算次数海外:第三方设计公司:英伟达Blackwell系列的推出,巩固了其在深度学习训练和推理的领导地位。GB200的FP16算力达到5000TFLOPS,相比于H200提升了5倍以上。AMD的MI325X为1300TFLOPS,英特尔Gaudi3为1835TFLOPS,谷歌TPU Ironwood(TPU v7p)为2307TFLOPS,与GB200都有明显差距。同时,Blackwell通过第二代Transformer引擎和定制Tensor Core,首次在硬件上实现了FP4数据类型的直接处理。H20/H800:H20基于H200进行性能裁剪,通过牺牲计算性能换取合规性。H20的FP16算力为148 TFLOPS,FP8算力为296 TFLOPS,仅为H200的15%左右。H800与H100算力指标保持一致,根据美国商务部2023年10月17日发布的出口管制新规,H800 被列入禁售名单。大厂自研:多数ASIC聚焦于低精度领域,除谷歌外都处于起步阶段。谷歌最新的TPU Ironwood(TPU v7p)是首款专为推理而设计的加速器,FP16算力达2307TFLOPS,比前代提升了两倍多。亚马逊的Trainium3预计FP16算力达1310TFLOPS,是Trainium2的两倍。中国大陆:除华为外,FP16算力能达到300TFLOPS以上的国产芯片,只有寒武纪的思元590和海光信息的BW100。壁仞科技在2022年推出的BR100的FP16算力能达到1024TFLOPS,但因受到制裁,无法量产落地。功耗/能效比能效比:FP16运算次数/功耗(TFLOPS/W)海外:第三方设计公司:英伟达Blackwell的能效比在所有架构里面最高,体现英伟达超强的硬件设计能力。尽管GB200的功耗达到了2700W,但能效比仍能达到1.9,在业内处于领先地位。大厂自研:多数ASIC的功耗在700W以下,达到降本目的。但能效比仍低于英伟达的GPGPU。中国大陆:根据不完全统计,国产芯片的功耗绝大多数都在500W以下,能效比低于1。二、显存指标显存/显存带宽/显存容量海外:绝大多数海外厂商最新产品都配备HBM3e,因堆叠层数、频率和HBM堆栈数量的配置不同,显存带宽和容量不同。英伟达从H200开始使用HBM3e。GB200的显存带宽达16TB/s,容量达384GB,是H200的三倍多。H20和H800的显存分别与H200和H100保持一致,远高于国产芯片。中国大陆:因受到制裁,绝大多数国产芯片最新产品使用HBM2e。除采用HBM外,还有国产芯片使用GDDR和LPDDR。如昆仑芯二代芯片和摩尔线程S4000、S3000均使用GDDR6,寒武纪MLU370系列均使用LPDDR5。算术强度算术强度:总浮点运算次数/内存带宽(FLOPS/Byte) 算术强度过高,说明内存带宽过低,芯片运行有内存瓶颈。海外:英伟达H100的算术强度较高,接近600FLOPS/Byte,随着HBM3e的使用,算术强度在H200和Blackwell系列逐渐降低。其他厂商因使用HBM3e且算力不高,算术强度都较低。中国大陆:国产芯片的算力水平较低,所以尽管显存带宽低,算术强度都较低,不存在带宽瓶颈。三、互联带宽双向互联带宽=每条链路单向带宽x链路数x 2海外:绝大多数厂商都开发了专有协议,带宽普遍在500GB/s以上。英伟达的NVLink5相比于NVLink4带宽翻倍,达到了1800GB/s。英伟达的NVLink依然有较强壁垒。AMD的Infinity Fabric4达到896GB/s。谷歌的ICI Links最高能达到672GB/s。H20使用NVLink4,带宽达到900GB/s,相较于国产芯片有较大优势。H800和A800都使用特供版NVLink,带宽只有400GB/s。中国大陆:国产芯片的互联能力普遍较弱,除华为外,带宽普遍在400GB/s以下。寒武纪思元270和思元590采用的MLU-Link,带宽分别达到600GB/s和372GB/s。海光信息BW100和沐曦科技的曦云C500的互联带宽能达到400GB/s。References:[1]英伟达:公司官网https://www.nvidia.cn/CSDN博客https://blog.csdn.net/qq_39815222/article/details/136897603墨天轮https://www.modb.pro/db/1830075219425452032[2]AMD:公司官网https://www.amd.com/zh-cn.html[3]英特尔:公司官网https://www.intel.cn/content/www/cn/zh/homepage.html[4]Groq:http://Sacra.comhttps://sacra.com/c/groq/[5]谷歌:The Next Platformhttps://www.nextplatform.com/2025/04/09/with-ironwood-tpu-google-pushes-the-ai-accelerator-to-the-floor/[6]亚马逊:Semianalysishttps://semianalysis.com/2024/12/03/amazons-ai-self-sufficiency-trainium2-architecture-networking/[7]Meta:公司官网https://ai.meta.com/blog/next-generation-meta-training-inference-accelerator-AI-MTIA/[8]微软:Semianalysishttps://semianalysis.com/2023/11/15/microsoft-infrastructure-ai-and-cpu/[9]寒武纪:公司官网https://www.cambricon.com/格隆汇https://finance.sina.com.cn/wm/2025-01-19/doc-inefpcsy0554481.shtml北方算网https://zhuanlan.zhihu.com/p/18044815862[10]昆仑芯:电子元件采购网https://www.ameya360.com/hangye/108036.html电子元器件采购网https://www.ameya360.com/hangye/108036.html知乎https://zhuanlan.zhihu.com/p/603925398捷睿星云http://www.jieruixingyun.com/busniess/intro/百度昆仑芯Product Briefhttps://paddlelite-demo.bj.bcebos.com/devices/baidu/K100_K200_spec.pdf[11]平头哥:公司官网https://img.102.alibaba.com/1622193035686/9898014ba4eb8adfd3f31db3b2cf26f3.pdf?spm=a2ouz.12987056.0.0.68229352l5LGSa&file=9898014ba4eb8adfd3f31db3b2cf26f3.pdf集微网https://www.sohu.com/a/374479009_166680[12]海光信息:鲸起Studiohttps://mp.weixin.qq.com/s/Oq3HZxFwOJuLTuwzj9RYQw北方算网https://zhuanlan.zhihu.com/p/18044815862华西证券研究所http://www.qdatis.com/files/20250207/447df7d38b08845b0b7fdf376030fd19.pdf格隆汇https://finance.sina.com.cn/wm/2025-01-19/doc-inefpcsy0554481.shtml[13]燧原科技: 美通社https://www.prnasia.com/story/296402-1.shtml与非网https://www.eefocus.com/article/498969.html智东西https://chedongxi.com/news/21214.htmlIT之家https://news.qq.com/rain/a/20211208A02G3B00[14]摩尔线程:公司官网https://www.mthreads.com/product/S3000TechPowerUphttps://www.techpowerup.com/316881/moore-threads-launches-mtt-s4000-48-gb-gpu-for-ai-training-inference-and-presents-1000-gpu-cluster[15]沐曦科技:CSDN博客https://blog.csdn.net/qq_23934063/article/details/132473834飞桨https://www.paddlepaddle.org.cn/support/news?action=detail&id=3334[16]壁仞科技:第一财经https://m.yicai.com/news/101501217.html电子工程专辑https://www.eet-china.com/mp/a152602.html[17]天数智芯:电子发烧友https://www.elecfans.com/d/2253998.html安信力http://www.anssionic.com/sgproducts_view.asp?main_id=20&small_id=71&id=244