搜索到
32
篇与
的结果
-
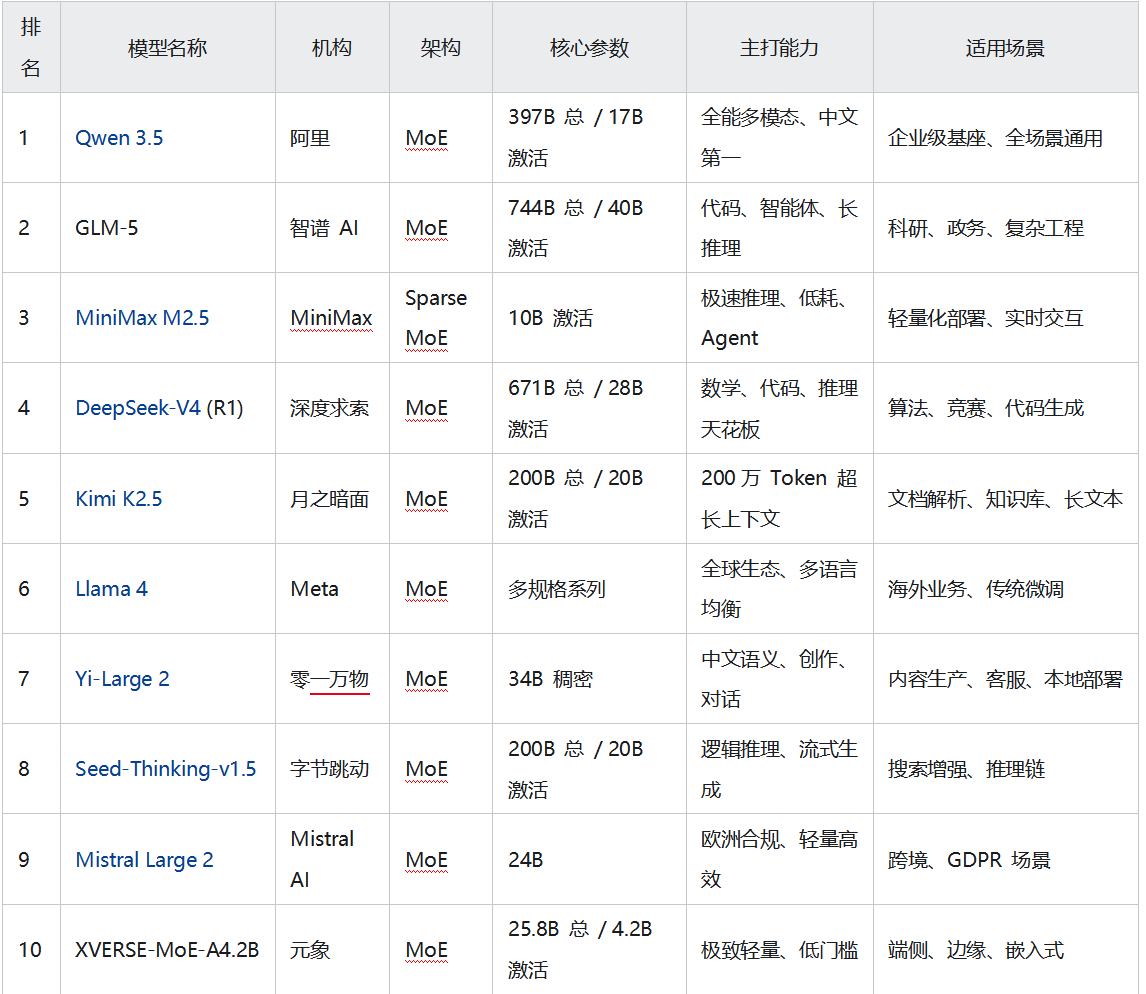
 2026 年开源大模型 TOP10 2026 年,开源大模型彻底告别“参数内卷”,进入效率优先、场景为王、生态成熟的普惠时代。 本文基于 Hugging Face 下载量、LMSYS 盲测、工程化落地成本、商用友好度、社区活跃度 五大维度,发布 2026 全球开源大模型 TOP10 权威榜单。榜单呈现一个明确事实: 全球开源 TOP10 中,中国模型占 8 席;MoE 架构成为绝对主流;国产模型在中文、推理、代码、多模态全面领跑。一、2026 开源大模型 TOP10 完整榜单(权威版)二、TOP10 模型深度解读Qwen 3.5 —— 全球开源综合之王总参数 397B,仅激活 17B,性能直逼 Gemini 3、GPT-5.2原生多模态,支持 201 种语言Hugging Face 全球下载量、综合评分双第一商用友好、文档齐全、生态最完善定位:企业级通用基座首选GLM-5 —— 开源代码与智能体之王744B 总参数,激活 40BSWE-bench 开源第一,代码通过率 77.8%支持复杂智能体、多工具协同、长链思考政务、学术、金融工程首选定位:高端研发与系统工程基座MiniMax M2.5 —— 性价比与速度之王轻量 MoE,推理成本仅为旗舰模型 1%低延迟、高吞吐,适合实时交互原生支持 Agent 工作流定位:中小企业、快速落地、API 服务DeepSeek-V4 (R1) —— 数学推理之王MATH 准确率 61.6%,HumanEval 65.2%开源模型中推理能力最接近 GPT-4o长思考、自验证、代码调试极强定位:科研、竞赛、高逻辑需求场景Kimi K2.5 —— 长文本处理之王支持 200 万 Token 上下文文档摘要、表格解析、PDF/Excel/PPT 全链路处理C 端用户量最大的开源模型之一定位:知识管理、办公自动化、法律/医疗文档Llama 4 —— 欧美生态根基Meta 官方旗舰开源 MoE海外资源最多、教程最丰富多语言均衡,但中文弱于国产定位:出海业务、传统 LLM 迁移Yi-Large 2 —— 中文稠密模型标杆34B 稠密架构,部署简单、稳定性高中文理解、情感、文案生成顶尖消费级显卡可流畅运行定位:个人开发者、轻量化企业服务Seed-Thinking-v1.5 —— 推理链专项强者字节开源,专注深度逻辑与流式推理AIME、Codeforces 等难题平均准确率超 75%三级并行,吞吐量极高定位:搜索增强、逻辑问答、智能诊断Mistral Large 2 —— 欧洲合规首选轻量高效、GDPR 合规小参数、强泛化、低部署成本欧洲市场占有率第一定位:跨境业务、欧盟区企业服务XVERSE-MoE-A4.2B —— 端侧部署王者仅激活 4.2B 参数,性能媲美 13B 模型全开源、免费商用边缘设备、手机、IoT 可运行定位:端侧 AI、嵌入式、低成本硬件三、2026 开源大模型三大趋势MoE 架构彻底统治市场几乎所有 TOP 模型均采用 MoE:总参数大 → 能力强激活参数小 → 成本低、速度快 稠密模型仅在轻量场景保留。中国开源力量全球主导TOP10 中 8 个来自中国Hugging Face 中文模型下载占比超 60%中文理解、工程化、性价比全面领先从“通用”走向“场景专精”推理型代码型长文本型端侧轻量型多模态型 选模型 = 选场景,不再唯参数论四、2026 开发者实战选型指南企业通用基座 → Qwen 3.5代码/智能体 → GLM-5低成本/高并发 → MiniMax M2.5数学/推理 → DeepSeek-V4长文档/知识库 → Kimi K2.5端侧/边缘 → XVERSE-MoE-A4.2B出海/多语言 → Llama 4 / Mistralhttps://zhuanlan.zhihu.com/p/2009705203163752429
2026 年开源大模型 TOP10 2026 年,开源大模型彻底告别“参数内卷”,进入效率优先、场景为王、生态成熟的普惠时代。 本文基于 Hugging Face 下载量、LMSYS 盲测、工程化落地成本、商用友好度、社区活跃度 五大维度,发布 2026 全球开源大模型 TOP10 权威榜单。榜单呈现一个明确事实: 全球开源 TOP10 中,中国模型占 8 席;MoE 架构成为绝对主流;国产模型在中文、推理、代码、多模态全面领跑。一、2026 开源大模型 TOP10 完整榜单(权威版)二、TOP10 模型深度解读Qwen 3.5 —— 全球开源综合之王总参数 397B,仅激活 17B,性能直逼 Gemini 3、GPT-5.2原生多模态,支持 201 种语言Hugging Face 全球下载量、综合评分双第一商用友好、文档齐全、生态最完善定位:企业级通用基座首选GLM-5 —— 开源代码与智能体之王744B 总参数,激活 40BSWE-bench 开源第一,代码通过率 77.8%支持复杂智能体、多工具协同、长链思考政务、学术、金融工程首选定位:高端研发与系统工程基座MiniMax M2.5 —— 性价比与速度之王轻量 MoE,推理成本仅为旗舰模型 1%低延迟、高吞吐,适合实时交互原生支持 Agent 工作流定位:中小企业、快速落地、API 服务DeepSeek-V4 (R1) —— 数学推理之王MATH 准确率 61.6%,HumanEval 65.2%开源模型中推理能力最接近 GPT-4o长思考、自验证、代码调试极强定位:科研、竞赛、高逻辑需求场景Kimi K2.5 —— 长文本处理之王支持 200 万 Token 上下文文档摘要、表格解析、PDF/Excel/PPT 全链路处理C 端用户量最大的开源模型之一定位:知识管理、办公自动化、法律/医疗文档Llama 4 —— 欧美生态根基Meta 官方旗舰开源 MoE海外资源最多、教程最丰富多语言均衡,但中文弱于国产定位:出海业务、传统 LLM 迁移Yi-Large 2 —— 中文稠密模型标杆34B 稠密架构,部署简单、稳定性高中文理解、情感、文案生成顶尖消费级显卡可流畅运行定位:个人开发者、轻量化企业服务Seed-Thinking-v1.5 —— 推理链专项强者字节开源,专注深度逻辑与流式推理AIME、Codeforces 等难题平均准确率超 75%三级并行,吞吐量极高定位:搜索增强、逻辑问答、智能诊断Mistral Large 2 —— 欧洲合规首选轻量高效、GDPR 合规小参数、强泛化、低部署成本欧洲市场占有率第一定位:跨境业务、欧盟区企业服务XVERSE-MoE-A4.2B —— 端侧部署王者仅激活 4.2B 参数,性能媲美 13B 模型全开源、免费商用边缘设备、手机、IoT 可运行定位:端侧 AI、嵌入式、低成本硬件三、2026 开源大模型三大趋势MoE 架构彻底统治市场几乎所有 TOP 模型均采用 MoE:总参数大 → 能力强激活参数小 → 成本低、速度快 稠密模型仅在轻量场景保留。中国开源力量全球主导TOP10 中 8 个来自中国Hugging Face 中文模型下载占比超 60%中文理解、工程化、性价比全面领先从“通用”走向“场景专精”推理型代码型长文本型端侧轻量型多模态型 选模型 = 选场景,不再唯参数论四、2026 开发者实战选型指南企业通用基座 → Qwen 3.5代码/智能体 → GLM-5低成本/高并发 → MiniMax M2.5数学/推理 → DeepSeek-V4长文档/知识库 → Kimi K2.5端侧/边缘 → XVERSE-MoE-A4.2B出海/多语言 → Llama 4 / Mistralhttps://zhuanlan.zhihu.com/p/2009705203163752429 -
RISC-V CPU侧信道攻击原理与实践 https://zhuanlan.zhihu.com/p/393106129RISC-V作为一种全新的开源CPU指令集体系结构(ISA),目前无论是在高校与各研究机构,还是商业应用中,皆方兴未衰,大有与X86和ARM形成成三足鼎立之势。但对于RISC-V CPU本身的安全, 却资料少而凌乱,晦涩难懂,面目狰狞,拒人于千里之外。故有此冲动,写几篇有关RISC-V CPU侧信道攻击的文章,介绍RISC-V CPU侧信道攻击的原理和作者本人的实践;作者研究CPU侧信道攻击的初衷也是为“防守”,意在为某款RISC-V CPU提供一个安全性验证平台,验证该CPU安全设计加固方案之有效性。我将用一系列文章来来介绍:什么是CPU侧信道攻击?导致CPU产生侧信道攻击风险的微架构设计技术Spectre攻击的种类与攻击方法细节;Meltdown攻击原理与工具过程;降低CPU侧信道攻击风险的手段那就让我们开始吧。侧信道攻击概述1.1什么是侧信道攻击1.1.1 日常生活中的侧信道攻击在科技日新月异的今天,在享受高科技带来的幸福感的同时,我们的隐私也会在不知不觉中从各种渠道被泄露出去,有些甚至你完全想不到,可以说防不胜防,比如说,你想过单从按键声音就分析出你的手机号码么?大家可能听说过网友“清华南都”就根据一段视频中的按键音,还原出了360总裁周鸿祎的手机号。事情起源于优酷的记者电话采访周鸿祎先生的一段视频. 在视频的第33-43秒,记者与周鸿祎先生进行了电话连线,视频播放把整个拨号过程也原封不动地播放了出来,包括在电话拨号阶段的产生的电话拨号音,“清华南都”就根据这段拨号音结合一些DTMF(双音多频, Dual-tone multi-frequency)的技术基础,破解这个电话号码;在这个事情中,如果把周鸿祎先生的电话号码当做一个高度机密信息(private data)的话,“清华南都”本人并没有看到过周先生的电话号码,也没有采用暴力破解的方式一个个电话号码去尝试,而“清华南都”通过分析声音特征信息获取了该机密信息,这个过程从技术范畴的角度讲就是一种利用了声波信息的“侧信道攻击”。那到底什么是侧信道攻击?维基百科是这么定义的:“在密码学中,侧信道攻击(Side-channel attack)是一种攻击方式,它基于从密码系统的物理实现中获取的信息,而非暴力破解法或是算法中的理论性缺陷,例如利用时间信息、功率消耗、电磁泄露或甚是声音可以提供额外的信息,来对系统的破解。”这个定义对于非密码学行业从业人员来讲还是非常抽象的。我们简单一点理解就是利用一些“旁门左道”的手法来获取我们需要的机密信息;比如我们经常在电视剧中看到的一个场景:一个窃贼将听诊器压在保险柜的前面板上,通过内部的机械声来打开保险柜。小偷会慢慢地转动转盘,听着内部机械结构所泄露出的咔哒声或阻力声,来分析保险箱齿轮的内部运作,并从而得知其密码的组合。除了拨号盘上的数字和保险柜“是”或“否”的打开状态以外,这个保险柜并不会给用户任何反馈。但保险箱的物理机械所产生的那些微小的触动和声音线索,这也是一个典型的侧信道攻击。某网站(https://www.wired.com/story/lamphone-light-bulb-vibration-spying/...)曾经公布了一项新技术(lamphone):“通过使用望远镜观察室内悬挂的灯泡的振动(通过灯泡所发出的光的微弱变化),可以实时窃听房间内的对话”。这种技术将测信道攻击变得更加具有广泛性。1.1.2 计算机领域的侧信道攻击计算机领域的侧信道攻击是利用计算机不经意间释放出的信息信号(如电磁辐射,电脑硬件运行产生的声音)来进行破译的攻击模式:例如,黑客可以通过计算机显示屏或硬盘驱动器所产生的电磁辐射,来读取你所显示的画面和磁盘内的文件信息;或是,通过计算机组件在执行某些程序时需要消耗不同的电量,来监控你的电脑;亦或是,仅通过键盘的敲击声就能知道你的账号和密码。最早的计算机侧信道攻击之一,是美国国家安全局(National Security Agency)所称的TEMPEST。1943年贝尔实验室发现,每当有人在电传打字机上打字时,电传打字机会导致附近示波器的读数移动。贝尔实验室的研究人员很快意识到这一问题。电传打字机的目的是为了实现安全、加密的通信,但任何接近它的人,只要能读到它的电磁辐射,就有可能破译它的秘密。这种现象直到1985年才被完全公开记录下来,当时一位名叫维姆·范·埃克(Wim van Eck)的计算机研究人员发表了一篇论文,这就是后来被称为 "屏幕辐射窃密(van Eck phreaking)",即通过远距离检测电脑屏幕放电的电信号,在电脑屏幕上重建图像。计算机领域的侧信道攻击,目前使用最为广泛的攻击手段就是基于时序的攻击(timing attack)。讲了那么多故事,让我们来看一段代码直观地了解一下什么是时序攻击:这是某产品中的一个秘钥比对函数,假设这个函数的用户无法看到源码(也不进行反汇编),我们只是通过库函数的头文件知道这个函数接口定义为int does_password_match(char * input_password)。那我们怎么能够快速地获取函数内部设定的机密信息strPrivateKey的值呢?你可能首先想到的是采用暴力破解方式,逐一尝试各种字符组合,直到函数返回true为止;如果这个秘钥只使用字母和数字,并且秘钥的最大长度7,那你需要尝试的最大次数为62**7=3,521,614,606,208【注26大写字母+26小写字母+10数字)。如果我们利用一下这个函数的timing信息,测量一下这个函数的处理时间,我们其实可以有一种更为快捷的方法,我们可以采用逐位破解的方法快速地完成这个任务;因为我们输入的密码与机密信息的匹配度越高,该函数的处理时间越长,这样我们通过测量这个函数的处理时间就可以判断前面的第一位,第二位,第三位等是否验证通过;则最坏的尝试的次数为62*7=434;用这种方式实现的一个产品(比如密码门禁系统),通过采用timing-attack的方法,其破解是完全可以通过人力的方式在数分钟内完成的;1.1.3 CPU的侧信道攻击目前随着超标量CPU技术的飞速发展,其处理性能大幅提升的同时, 以计算机为中心的侧信道攻击也变得更加复杂和手段多样。所谓道高一尺,魔高一丈; 2018伊始,两个芯片级漏洞Meltdown(熔断)、Spectre(幽灵)漏洞震惊了安全界。受影响的CPU包括Intel、AMD和ARM,基本囊括的消费级CPU市场的绝大部分。Meltdown漏洞可以在用户态越权读取内核态的内存数据,Spectre漏洞可以通过浏览器的Javascript,读取用户态的内存数据。这两个漏洞摧毁了公有云的基石(用户数据隔离),因为通过Meltdown和Spectre的攻击,用户在虚拟机里就可以无限制的读取宿主机或者其他虚拟机的数据。Spectre、Meltdown等攻击方式利用了微处理器的 "微架构"设计中的这些特性(站在安全的角度也可以叫漏洞,包括但不局限于分支预测,推断执行,乱序执行,等)。随着计算机变得越来越复杂,如果计算行业继续优先考虑性能而不是安全,侧信道攻击将会越来越猖獗,今天一个你看似巧妙的设计,非常有可能成为明天攻击的一个突破口。1.2 侧信道攻击的分类对于CPU侧信道攻击,很多公司(比如google和微软)成立了专门的安全团队,用来发现目前市场上主流CPU的安全风险并提供安全解决方案以降低危害(mitigation of the risk)。 随着对上述meltdown和Spectre攻击方式的研究深入,越来越多的基于meltdown和spectre的变种被开发了出来。参考文献[A Systematic Evaluation of Transient Execution Attacks and Defenses]对瞬态执行攻击进行了系统的分析,并把当前已经发现的针对CPU微架构的侧信道攻击方法进行了总结与归类(见图),文献的作者认为当前大部分的安全防护方法无法有效应对当前如此多的攻击方式带来的安全风险。本系列文章主要描述如下几种Spectre变种攻击方式:• Variant 1 (Spectre_PHT): bounds check bypass• Variant 2 (Spectre_BTB): branch target injection• Variant 4 (Spectre_STL): Store bypass• Variant 5 (Spectre_RSB): Return Stack Buffer【注:PHT: Pattern History Table, BTB:Branch Target Buffer, STL:Store To Load, RSB:Return Stack Buffer】Meltdown属于 Variant 3, Meltdown还可以进一步细分为:• Meltdown-US(Supervisor-only Bypass)• Meltdown-P(Virtual Translation Bypass)• Meltdown-GP(System Register Bypass)• Meltdown-NM(FPU Register Bypass)• Meltdown-RW(Readonly Bypass)• Meltdown-PK(Protection Key Bypass)• Meltdown-BR(Bounds Check Bypass)我们重点关注高性能CPU的一些通用设计带来的风险,而对于某些厂家独特设计带来的问题,本文不做过多的描述。
-
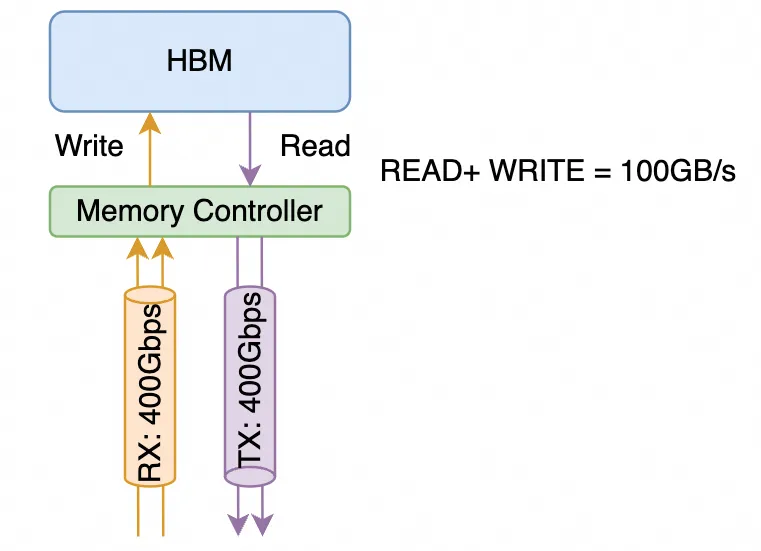
英伟达GB200架构解析1: 互联架构和未来演进 原创扎波特的橡皮擦zartbot2024年03月31日22:36浙江关于GB200想从下面几个方面来谈:NVL72和互联架构演进GH200/GB200在推荐系统等场景下的业务价值和商业逻辑GB200芯片的微架构的分析这是这个系列的第一篇,从互联架构上进行探讨。很多金融机构和分析师团队都在将英伟达和互联网兴起时的思科对比,那么本文在介绍完英伟达互联架构演进后也会穿插着把思科在互联网兴起时对互联系统的演进路径,以及当年的网络处理器(Network Processor,NP)和当下的DPU在体系结构上的进行对比,包括英伟达BlueField的片上网络还有很多Ezchip和Tilera这些网络处理器的影子,于是很多事情都会更加清晰了。互联网时代的思科和AI时代的英伟达,虽然时代不同,但有太多的路径重叠。本源是都在面临算力不够(思科是大量的查路由表访问内存)碰到内存墙后开始了一系列多芯片Scale-Out而产生互联架构的创新。特别是Bill Dally在互联网时代创办的Avici和当年华为的最顶级路由器NE5000有太多的关系,以及当下TPU的互联架构都是3D-Torus,而如今Bill Dally又是英伟达的首席科学家,未来的演进路线基本上也就清晰了。1.GB200互联架构解析1.1 NVLink带宽计算英伟达在对NVLINK的传输带宽计算和对于SubLink/Port/Lane的概念上存在很多混淆的地方,通常 单颗B200的NVLINK 5带宽是1.8TB/s,这是做计算的人算带宽通常按照内存带宽的算法以字节每秒(Byte/s)为单位。而在NVLink Switch上或者IB/Ethernet交换机和网卡上,是Mellanox的视角以网络带宽来计算的,通常是以传输的数据位为单位,即比特每秒(bit/s)。这里详细解释一下NVLINK的计算方式,NVLINK 3.0开始由四个差分对构成一个"sub-link"(英伟达经常对它用Port/Link,定义有些模糊),这4对差分信号线同时包含了接收和发送方向的信号线,而通常在计算网络带宽时,一个400Gbps的接口是指的同时能够收发400Gbps的数据,如下图所示它总共由4对差分信号线构成RX/TX各两对,从网络的视角来看是一个单向400Gbps的链路,而从内存带宽的视角是支持100GB/s的访存带宽。1.1.1 NVLINK 5.0 互联带宽在Blackwell这一代采用了224G Serdes,即sub-link的传输速率为200Gbps 4(4对差分线)/8 =100GB/s,从网络来看单向带宽为400Gbps。B200总共有18个sublink,因此构成了 100GB/s 18 = 1.8TB/s的带宽,而从网络的视角来看等同于9个单向400Gbps的接口。同理,在NVSwitch的介绍中声明的是 Dual 200Gb/sec SerDes构成一个400Gbps的Port为了方便后文的叙述,我们对这些术语进行统一定义如下:B200 NVLINK带宽为1.8TB/s,由18个Port构成,每个Port 100GB/s,由四对差分线构成,每个Port包含两组224Gbps的Serdes (2x224G PAM4 按照网络接口算为每端口单向400Gbps带宽)1.1.2 NVLINK 4.0 互联我们再补充一下Hopper,在NVLINK 4.0中采用了112G Serdes,即单对差分信号线可以传输100Gbps,累计单个NVLINK的Sub-link构成4x100Gbps= 50GB/s,支持NVLINK 4.0的Hopper这一代产品有18个sub-link(port),则单个H100支持50GB/s * 18 = 900GB/s,单机8卡利用4个NVswitch连接,如下图所示它还可以增加第二层交换机构成一个256卡的集群扩展接口采用OSFP的光模块如下图所示,OSFP光模块可以支持16对差分信号线, 因此单个OSPF支持4个NVLINK Port,即下图中NVLink Switch包含32个OSFP光模块接口连接器,累计支持32 * 4 = 128个NVLINK4 Port1.2 GB200 NVL72GB200 NVL72的Spec如下图所示,本文主要讨论NVLINK相关的问题一个GB200包含一颗Grace 72核的ARM CPU和2颗Blackwell GPU整个系统由Compute Tray和Switch Tray构成,一个Compute Tray包含两颗GB200子系统,累计4颗Blackwell GPU一个Switch Tray则包含两颗NVLINK Switch芯片,累计提供72 * 2 = 144个NVLINK Port,单颗芯片结构如下,可以看到上下各36个Port,带宽为7.2TB/s,按照网络的算法是28.8Tbps的交换容量,相对于当今最领先的51.2Tbps交换芯片小一些,但是需要注意到它由于实现SHARP(NVLS)这样的功能导致的整个机柜支持18个Compute Tray和9个Switch Tray,因此构成了一个单机柜72个Blackwell芯片全互联的架构,即NVL72.单个GB200子系统则包含2 * 18 = 36个NVLink5 Port,整个系统对外互联上并没有采用OSFP的光模块接口,而是直接通过一个后置的铜线背板连接,如下图所示:关于光退铜进这些金融机构分析师的说法其实是片面的,Hopper那一代是考虑的相对松耦合的连接方式,导致这些分析师过分的夸大了光模块的需求。而且当时对机柜散热部署等要求更加灵活。而这一代是在单机柜内整柜子交付,属于类似于IBM大型机的交付逻辑,自然而然的就选择了铜背板,同时单个B200功耗更高,整机液冷交付同时还有功耗约束,从功耗的角度来看换铜也可以降低很多。但是这并不代表未来都会是铜互联,后面章节会详细分析。整个NVL72的互联拓扑如下所示:每个B200有18个NVLINK Port,9个Switch Tray刚好共计18颗NVLINK Swtich 芯片,因此每个B200的Port连接一个NVSwitch芯片,累计整个系统单个NVSwitch有72个Port,故整个机器刚好构成NVL72,把72颗B200芯片全部连接起来。1.3 NVL576我们注意到在NVL72的机柜中,所有的交换机已经没有额外的接口互联构成更大规模的两层交换集群了,从英伟达官方的图片来看,16个机柜构成两排,虽然总计正好72 * 8个机柜构成576卡集群的液冷方案,单是从机柜连接线来看,这些卡更多的是通过Scale-Out RDMA网络互联的,而并不是通过Scale-Up的NVLINK网络互联对于一个32,000卡的集群也是通过这样的NVL72的机柜,一列9个机柜,4个NVL72和5个网络机柜,两列18个机柜构成一个Sub-Pod,并通过RDMA Scale-Out网络连接当然这个并不是所谓的NVL576,如果需要支持NVL576则需要每72个GB200配置18个NVSwitch,这样单机柜就放不下了,事实上我们注意到官方有这样一段话:官方说NVL72有单机柜版本,也有双机柜的版本,并且双机柜每个Compute Tray只有一个GB200子系统,另一方面我们注意到NVSwitch上有空余的铜缆接头,很有可能是为了不同的铜背板连接而特制的这些接口是不是会在铜互联背板上方再留一些OSFP Cage来用于第二层NVSwitch互联就不得而知了,但这样的方法有一个好处,单机柜的版本是Non-Scalable的,双机柜版本的是Scalable的,如下图所示:两个机柜的版本有18个NVSwitch Tray,可以背靠背互联构成NVL72.虽然交换机多了一倍,但是为以后扩展到576卡集群,每个交换机都提供了36个对外互联的Uplink,累计单个机柜有36 2 9 =648个上行端口,构成NVL576需要有16个机柜,则累计上行端口数为 648 * 16 = 10,368个,实际上可以由9个第二层交换平面构成,每个平面内又有36个子平面,由18个Switch Tray构成,NVL576的互联结构如下所示:1.4 从业务视角看到NVL576对于NVL576这样超大规模的单一NVLink Scale-Up组网是否真的有客户,我个人是持怀疑态度的,AWS也只选择了NVL72来提供云服务。主要的问题是2层组网的可靠性问题和弹性售卖的问题来看,NVL576并不是一个好的方案,系统复杂性太高。这样的方案存在的价值和当年思科搞CRS-1 MultiChassis集群类似,当年思科也是弄了一个16卡单个机柜,累计可以通过8个8个交换矩阵机柜互联72个线卡机柜来构成一个超大规模系统。主要是需要在市场上留一个技术领先的flag/benchmark,最终这样大规模的理论存在的系统埋单的用户几乎没有。另一方面是从下一代大模型本身的算力需求来看的,meta的论文《How to Build Low-cost Networks for Large Language Models (without Sacrificing Performance)?》[1]讨论过, 对于NVLink互联的Scale-Up网络,论文中将其称为一个(High Bandwidth Domain,HBD),对HBD内的卡的数目进行了分析:针对GPT-1T的模型来看,K=36以上时对性能提升相对于K=8还是很明显的,而对于K>72到K=576时的边际收益相对于系统的复杂性而言是得不偿失的,另一方面我们可以看到,当Scale-Up的NVLINK网络规模增大时,实际上HBD之间互联的RDMA带宽带来的性能收益在减小,最终的一个平衡就是通过NVL72并用RDMA Scale-Out来构建一个32,000卡的集群。互联系统演进:思科的故事这里用思科当年的发展路径来做对比具有很大的借鉴意义,前段时间有一篇公众号GlassEye的《英伟达的思科时刻》更多的是从金融市场和经济的视角来看待:第一,新技术的迭代(万维网 vs. 大模型)第二,卖铲子公司的垄断( 1993年思科的路由器/交换机 vs. 2023年英伟达的GPU)第三,标志应用的推出(1995年Netscape vs. 2023年的ChatGPT)--引用自GlassEye《英伟达的思科时刻》但是从技术的角度上,思科在那些年代的发展可以参考我以前写过的一篇文章《“网络编程” 还是 “可编程网络”?》2.1 算力/内存瓶颈带来的分布式架构最早的时候,思科的路由器是采用单颗PowerPC处理器执行转发的。随着互联网的爆发,对于路由查表等访存密集型计算导致了性能瓶颈,因此逐渐出现了进程交换/CEF等多种方式,通过数据总线将多个处理器连接起来:这些做法和早期的NVLINK 1.0 / NVLINK 2.0类似,例如Pascal那一代也是采用这种芯片间直接总线互联的方式2.2 交换矩阵出现1995年的时候,Nick Mckeown在论文"Fast Switched Backplan for a Gigabit Switched Router"中提出使用CrossBar交换机构成一个背板来支撑更高规模的Gigabit级的路由器,即后来的Cisco 12000系列高端路由器这些交换背板和当下的NVSwitch以及NVSwitch Tray构建的NVL8~NVL72的系统背后的原理是完全一致的。都是在单颗芯片遇到内存墙后,通过多个芯片互联构建一个更大规模的系统。Cisco12000的单机柜构造,中间是Switch Fabric和GB200机柜中间的9个Switch Tray类似,而顶部和底部都有8个业务线卡(LineCard)插槽,对应于GB200的每个Compute Tray。而这里面相对核心的技术是VOQ和iSLIP调度算法的设计,等价来说,当模型执行All-to-All时,有可能会多个B200同时向一个B200写入数据,因此会产生一定的头阻(Head-Of-Line Blocking,HOLB),聪明的人类总会在十字路口前后加宽一点作为缓冲,也就是所谓的Input Queue和Output Queue:可惜问题又来了,对于Output Queue而言, 虽然可以最大限度的使用带宽, 但需要队列缓存具有N * R的操作速度. 而对于Input Queue, 缓存可以用R的速度进行处理, 但是会遇到HOL Blocking的问题. 在一个IQ交换机上受制于HOL Blocking的crossbar最大吞吐量计算可得为 58.6%.解决IQ HOL Blocking问题的一种简单方案是使用虚拟输出排队(virtual output queueing , VOQ).在这种结构下,每个输入端口为每个输出设置一个队列,从而消除了HOL Blocking. 并保持缓存的操作速度为R.当然英伟达在NVLINK上采用了Credit based的设计方案,Credit的分发仲裁等都是国内一些做GPU创业的公司值得深入研究的问题。2.3 MultiStage多级架构和光互联演进而NVL576更像是思科在2003年推出的Carrier Routing System(CRS-1)当时也是面对互联网泡沫时期对带宽的巨大需求,构建了多级交换网络的系统。单个机柜3-stage的交换网络构建的Switch Tray,等同于当前的Non-Scalable的GB200 NVL72。而多机柜的结构则是对应于NVL576,当年思科也是将单机柜16个Linecard可以扩展到采用8个Fabric机柜+72个LineCard机柜来构建1152个LineCard的大规模集群,当年思科的内部连接也是采用光互联机箱之间的光连接器如下图所示:需要注意的是这个时间点还有一个人,那就是现在英伟达的首席科学家Bill Dally,它创建了Avici公司通过3D-Torus互联来构建Tbit级路由器3D-Torus的互联是不是又想到了Google的TPU?而后来华为也OEM了Avici这套系统并标记为NE5000售卖,再后来才是自己研发的核心路由器产品NE5000E。而同一个时代,Juniper的诞生也在核心路由器这个领域给思科带来很多压力。或许英伟达一家独大的日子接下来会引来更多的挑战者。另一方,MEMS的光交换机也是在那个年代引入的,和如今Google利用光交换机似乎也有一些似曾相识的感觉英伟达未来的演进年互联系统的大会HOTI上,Bil Dally做了一个Keynote: Accelerator Clusters,The New Suppercomputer[2]从片上网络和互联系统的角度来谈主要就是三大块内容:Topolgy:CLOS/3D-Torus/DragonflyRouting:Flow control不同的器件连接有不同的带宽和功耗:问题是如何有机的将它们组合起来,需要考虑功耗/成本/密度和连接距离等多个因素3.1 光互联通过这些维度的度量,Co-Package Optic DWDM成为一种选择:构建光互联的系统概念图如下:最终构建一个超大规模的光互联系统这一点上你会看到和思科当年做的CRS-1多机框系统几乎完全一致,GPU Rack等同于Cisco LineCard Chassis, Switch Rack等同于思科的Fabric Chassis,并且都是光互联,同时也使用了DWDM技术来降低连接复杂度并提升带宽芯片架构上则采用了Optical Engine作为chiplet进行互联而互联结构上则是更多的想去采用DragonFly拓扑并利用OCS光交换机至于FlowControl这些拥塞控制算法上,Bill在谈论一些类似于HOMA/NDP的机制,还有Adaptive Routing等。事实上并不用这么复杂,因为我们有更好的MultiPath CC算法,甚至不需要任何新的交换机特性支持。3.2 算法和特殊硬件结合另一方面来看,Transformer已经出来7年了,当然它是一个非常优秀的算法,既占满了算力有Compute Bound的算子,又有Memory Bound的算子,而整个工业界是否还有更精妙的算法呢?在《大模型时代的数学基础(4)》中我们介绍了一些算法,例如稀疏Attention的Monarch Mixer以及不需要Attention机制的Mamba/RMKV等模型,当然还有很多人正在研究的基于范畴论/代数几何/代数拓扑等算法下的优化。当然还有不同精度的数值格式,例如Blackwell开始支持的FP4/FP6格式,以及未来可能支持的Log8格式其实历史上思科也是依靠算法和特殊硬件来逐渐提高单芯片的算力摆脱复杂互联结构的。当时通过TreeBitMap这些路由查表算法在普通的DRAM上就可以支持大规模的路由查询同时借助于多核和片上网络等技术的发展,构建了超高性能的SPP/QFP/QFA网络处理器,而这些技术又辗转着在AWS Nitro/ Nvidia BlueField / Intel IPU等DPU处理器上再次出现。算法/算力和硬件的反复迭代才是时代发展的脉搏结论本文分析了最新的Blackwell这一代GPU的互联架构,并且针对《英伟达的思科时刻》对于两次科技浪潮中,两家公司面临单芯片算力跟不上爆发性需求后进行的分布式系统构建和互联架构的探索,并分析了英伟达首席科学家Bill Dally在2023 Hoti的演讲,基本上能够看清楚英伟达未来的发展路径了。但是我们同时也注意到,思科在互联网泡沫的高峰时期,也诞生了Juniper/Avici这样的公司,英伟达也是在那个年代作为挑战者战胜了3Dfx,后来又在专业领域战胜了SGI。任何一个时代都值得期待,而赢下来的不是单纯的堆料扩展,而是算法和算力结合硬件的创新。从挑战者来看,算力核本身抛开CUDA生态,其实难度并不大。最近Jim Keller和日韩一些HBM玩家动作频频,是否BUDA+RISC-V+HBM会成为一个新兴的力量。从互联系统替代IB/NVLINK来看,以太网已经有了51.2Tbps的交换芯片,基于以太网高速连接HBM的通信协议,并且支持SHARP这些随路计算在网计算的东西早在三年前NetDAM就设计好了《NETDAM-DPU新范式: 网络大坝和可编程存内计算》HBM通过以太网互联并高速低延迟访问内存的应用场景,很多人或许到了今日才会明白它的价值,毕竟只有经历过很多事情的老司机们才能更早的把这些看穿了:)参考资料[1]How to Build Low-cost Networks for Large Language Models (without Sacrificing Performance)?: https://arxiv.org/abs/2307.12169[2]HOTI 2023: Bill Dally Keynote: Accelerator Clusters: https://www.youtube.com/watch?v=napEsaJ5hMU来自微信
-
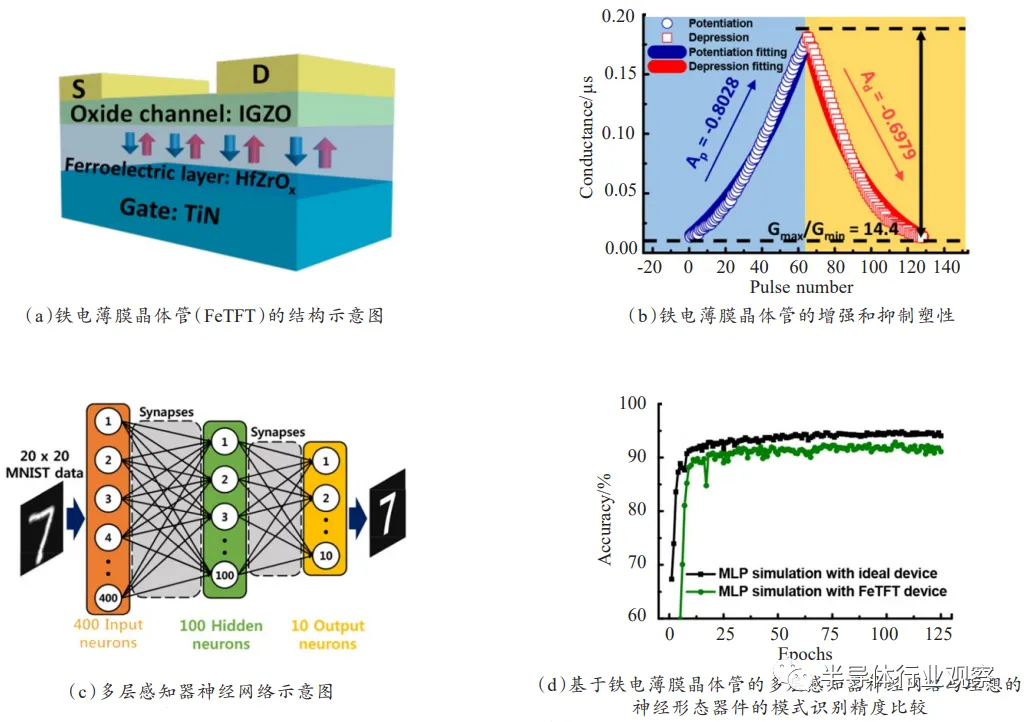
神经形态晶体管研究进展 光刻人的世界2020年12月28日18:45神经元是大脑信息处理的基本单元,突触则是神经元之间在功能上发生联系的部位,也是信息传递和处理的关键部位。从底层出发研制具有生物突触和神经元功能的固态器件与系统对于研制超低功耗“类脑芯片”和实现全新一代人工智能系统意义十分重大。其中多端口晶体管由于其独特的电容耦合机制,多元化的界面调控手段和丰富的材料选择等优点,最近引起了科研界的广泛关注。从铁电突触晶体管、双电层/电化学突触晶体管、光电突触晶体管3类器件介绍近年来神经形态晶体管的研究进展,并总结该类器件面临的机遇和挑战。引言人脑是一个大规模并行计算结构,通过突触传递输入信息,能够实时处理接收到的各类信息,每个突触事件仅消耗1~10fJ,其高效和超低功耗一直为全人类所惊叹。大脑由大约1011个神经元组成,每个神经元可以通过1000多个突触与其他神经元连接。这些神经元和突触连接排列在三维空间中,形成了一个复杂的信息处理神经网络,它是人类所有感知、思想和行为的基础。在当今社会,人类已经步入了大数据时代,每天都要进行大量的数据传输和储存,这些工作如今主要都依赖于传统的计算机处理系统,其功不可没,然而传统计算机也面临着许多 的挑战。(1)构筑传统计算机的主要器件CMOS晶体管发展到当前工艺已经很难遵循摩尔定律了,传统计算机很难实现更小尺寸的高效处理模式;(2)传统计算机的构架遵循冯·诺依曼结构,其结构中CPU和内存是分开的。两者之间的大量数据传输不利于计算系统的效率提升,功耗降低,体积减小,即达到了“冯·诺依曼瓶颈”[1]。众所周知,相对于传统计算机,人脑能够快速处理复杂信息,同时学习和记忆,并且能耗非常低,体积很小,其高效和强大引起了众多科学家的关注[2-3]。受大脑这样的生物超级计算机的强大能力鼓舞,利用电子器件构筑一个能够自学习低功耗类脑计算机的神经形态工程理念于几十年前就已经提出来了。发展至今,科学家们提出类脑神经计算可由两类途径实现,分别是软件模拟和硬件实现。目前基于软件模拟的方法往往需要消耗大量的能量和占据很大的空间。IBM曾用超级计算机(Blue Gene)来进行软件模拟,其电功耗高达1.4兆瓦[4]。此外,软件模拟的途径是通过计算机大量串行处理进行计算,因此不能高效地模拟神经网络的并行处理机制。基于硬件实现的途径是利用高集成度的电子器件来构建人工神经元网络。突触作为神经元的功能连接部位,能够高效地处理和传递信息,也是计算和学习的基本单位。因此,设计并制备出具有突触功能的电子器件装置对于实现类脑计算体系存在着非凡的意义。神经系统中,突触作为一种特殊的结构,它能够将电信号转化为化学信号,再转化为电信号,从而进行神经元之间的信息传递。根据后神经元响应的电信号不同可分为兴奋性突触电流/后电位(excitatory post-synaptic current/potential, EPSC/EPSP)和抑制性突触后电流/后电位(inhibitory postsynaptic current/potential,IPSC/IPSP)。前神经元和后神经元之间的连接强度被定义为突触权重,许多突触权重变化的研究统称为突触可塑性。根据保留时间的不同,突触可塑性可以简单地分为短程可塑性(short-term plasticity,STP)和长程可塑性(long-term plasticity, LTP)。STP发生在毫秒到分钟之间,是神经网络计算功能的生理基础。双脉冲易化(pairedpulse facilitation,PPF)是STP的一种表现形式,当第二个输入信号跟第一个输入信号时,突触后信号被放大。PPF可参与一些神经元任务,如简单的学习和信息处理。LTP表示持续几个小时或更长时间的可塑性变化,将给神经网络带来永久性的变化,从而使大脑能够存储大量的信息。Hebb假设认为持续和反复刺激突触前神经元,可导致突触后神经元突触传递效率的提高[5]。时间依赖突触可塑性(spiketiming-dependent plasticity,STDP)概念的提出进一步完善了Hebb的理论,指出突触前和突触后尖峰的时间关系可以调节突触权重[6]。除STDP外,频率依赖突触可塑性(spike-rate-dependent plasticity,SRDP)是另一个基本的学习机制,突触权重可以通过控制突触前脉冲频率来改变,高于特定频率阈值的高频突触前脉冲将引起突触后反应增强,而低于特定频率阈值的低频突触前脉冲会导致这种反应的抑制[7]。近年来,大量的电子器件被构筑出来模拟突触塑性以期其在类脑神经形态工程中的突破和应用。其中两端器件如忆阻器、相变存储器、原子开关等,由于它们具有结构简单、功耗低、物理体积小、易于大规模集成等优点已被广泛应用于模仿突触功能[8-9]。然而,这些器件很难同时执行信号传输和自学习功能,大大阻碍它们在先进类脑神经形态工程中的进一步应用[10]。三端/多端突触晶体管不仅克服了二端器件很难同时执行信号传输和自学习的缺点,还具有稳定性好、测试参数相对可控、运行机制清晰、可由多种材料构成等优点[11]。通过适当的材料选择和结构设计,三端/多端突触晶体管可以将外界的刺激(光、压力、温度等)转换成电信号,从而实现对外界环境直接响应的人工突触[12-13]。此外,模拟需要多端操作的并行学习和树突整合可以很容易地在基于三端/多端突触晶体管的人工突触中实现,这为开发具有较少神经元件的神经网络开辟了可能 性。因此,三端/多端突触晶体管可能比其他类型的器件更适合模拟突触功能。基于三端/多端突触晶体管的人工突触的研究越来越受到重视,但这一领域还处于起步阶段。本文综述和讨论了包括铁电突触晶体管、双电层/电化学突触晶体管和光电突触晶体管在内的三端/多端晶体管的工作原理和近年来的主要进展,以期对今后的研究有所启发。铁电突触晶体管铁电场效应晶体管(ferroelectric field-effect transistors,FeFETs)具有编程速度快、无损读出、开关比大、低功耗等优点,在人造电子突触仿生学方面有广泛的应用前景[14]。FeFETs应用于突触晶体管的工作原理是由于具有高介电常数能够自发极化的铁电材料作为其绝缘层,通过电压可以调控铁电材料的极 化状态,从而改变沟道载流子密度,而沟道电导非易失性改变实现了突触功能的模拟。此外,每一个脉冲电压都会改变铁电材料的细微极化状态,因此也会在沟道中得到不同的电导。利用这种多级化非易失性的变化可用于记录突触权重,许多科学家利用这一性质模拟了突触的STDP学习功能。2014年,Kaneko等[15]提出基于ZnO/Pr(Zr,Ti)O3/SrRuO3/Pt结构的铁电晶体管构筑神经网络。利用铁电材料Pr(Zr,Ti)O3(PZT)的多极化效应可调控晶体 管中沟道ZnO中电导的大小,这种调节变化可保持很长的时间,类似长程可塑性。使用此铁电晶体管成功地模拟了生物突触中的STDP学习规则,此外为了实现模式识别功能利用此器件搭建了神经网络结构,其原理是由于STDP学习规则进行了学习和记忆,其网络结构中的权值分布会发生改变,进行识别操作过程时,当输入一定模式时,神经网络会召回最接近曾经学习过的模式形成输出信号。虽然基于PZT的铁电晶体管在模拟突触方面表现出很好的塑性行为,但其固有的铅含量,不可避免地会给人类和环境带来危害。近年,Kim等[16]报道了一种如图1(a)所示以24nm HfZrOx为铁电绝缘层10nm InGaZnO为沟道层的突触晶体管。HfZrOx首先由ALD在280℃的腔体温度下沉积,然后在400℃氮气 氛围下退火1min形成铁电绝缘层。通过改变施加的电压脉冲的振幅,可以精细地调制通道的电导。此外,如图(1b)所示构筑的铁电晶体管表现出很好的增强和抑制塑性,例如高的模拟状态数(64)、良好的线性(Ap,-0.8028;Ad,-0.6979)和Gmax/Gmin比值>10。受其良好性能的鼓舞,设计了一个如图1(c)所示具有400个输入神经元、100个隐藏神经元和10个输出神经元的多层感知器神经网络。经过多阶段训练,实现了手写数字91.1%的识别准确度,接近理想突触神经网络94.1%的识别率,如图1(d)所示。氧化物铁电材料通常需要较高的结晶温度,这限制了其在塑料基板上大面积电子器件的应用。此外,其固有刚性也限制了其在柔性和可穿戴电子设备领域的应用。图1.无机铁电晶体管的神经形态应用与氧化物铁电体相比,有机铁电体可以克服氧化物铁电体的这方面的局限性。Jang等[17]报道了以有机PVDF-TrFE薄膜作为铁电绝缘层的超薄(500nm) 突触晶体管,如图(2a)所示。它可以独立存在,无需基底或封装层,利用简单的干法剥离和粘贴方法,所制备的器件可以稳定地转移到如图2(b)所示的二氧化硅、纺织品、牙刷、果冻、糖果等各种均匀和不均匀的基板上。通过对有机铁电绝缘层的极化调节,成功地实现了短程可塑性(STP),长程可塑性(LTP),长程抑制(LTD),时间依赖突触可塑性(STDP)等重要的突触功能,如图2(c)~(e)。为了验证超薄有机突触晶体管能在苛刻的弯曲条件下保持其稳定的突触功能,他们在R=50µm,ε=0.48%的折叠条件下测试了器件突触的突触塑性,图2(f)展现了苛刻的弯曲条件下施加6000个脉冲器件表现 出稳定的长期增强和长期抑制突触塑性。这项工作表明了超薄柔性有机人工铁电突触器件是实现未来可穿戴智能电子的关键技术之一。图2.超薄柔性有机铁电晶体管的突触塑性双电层/电化学突触晶体管双电层/电化学突触晶体管(electric-double-layer/electrochemical synaptic transistors)由于其栅介质层中离子可以自由移动,在电场诱导作用下进行迁移、积聚进而改变沟道导电特性。晶体管中的栅电极可以看作是突触前膜,沟道层可以看作是突触后膜,沟道电导可以看作是突触重量,这种类似于突触的工作模式使其在低功耗,柔性突触仿生学领域展现了广泛的应用前景。在外电场作用下界面处由于静电耦合积累电荷层的晶体管称为双电层薄膜晶体管[18],而对于有些离子可渗透的半导体,当施加的外电场过大,离子可从栅介质层中渗透进沟道层中进而改变沟道电导的工作原理是电化学掺杂,其晶体管称之为电化学薄膜晶体管[19]。突触电子学中常用易失性的静电耦合作用和非易失性的电化学掺杂/脱掺杂这两种机制来模拟突触的短程和长程可塑性。此外,双电层/电化学突触晶体管一个出众的方面是在低功耗方面已经能够实现生物学中单个突触事件的能量消耗(大约10fJ/spike)[20],这为实现超低功耗突触器件打下了坚实的基础。无机半导体具有良好的稳定性和较高的载流子迁移率,在三端双电层/电化学突触晶体管中彰显着巨大的应用潜力。近年来用于突触器件的无机半导体材料有很多,包括碳纳米管[20],石墨烯[21],二硫化钼[22],铟锌氧[11],铟镓锌氧[23]等。碳纳米管具有纳米尺寸和独特的电学性质,被认为是未来电子电路中 替代硅的潜在材料。2013年,Kim等[20]报道了以碳纳米管作为沟道层,氢掺杂聚乙二醇单甲醚(PEG)作为栅介质层的突触晶体管,其结构示意图如图3 (a)所示。在施加电压脉冲之前,聚合物中的氢离子是随机分布的。当正电压脉冲作用于碳纳米管突触器件的栅极时,氢离子开始定向移动,最终由于静电 耦合效应形成双电层,进而调节碳纳米管沟道中载流子浓度,导致沟道电流的增加。脉冲结束后,由于浓度梯度的存在,电解质/沟道界面附近的氢离子会从界面处开始慢慢扩散,使沟道电流继续减小直至稳定,如图3(b)。基于离子迁移和非易失性静电耦合效应,该晶体管成功地模拟了EPSC、PPF、动态逻 辑、长程增强塑性、长程抑制塑性和STDP等典型的突触功能。图3.碳纳米管突触晶体管示意图及突触前电压脉冲触发的EPSC石墨烯具有优异的热稳定性、超薄的层状结构和良好的力学性能,是一种应用于高集成度柔性电子器件领域的理想材料。Sharbati等[21]利用聚氧化乙烯(PEO)中的LiClO4作为固体电解质,被剥落下来的石墨烯原子层作为沟道层。栅电极模拟突触前膜,固体电解质模拟神经元间传导离子的突触裂缝。通过控制石墨烯层中锂离子的浓度,实现了对石墨烯器件电导的可逆精确调节。在这个电化学石墨烯突触器件中模拟了突触的增强和抑制塑性。当向石墨烯器件施加50pA、10ms的输入电流时,沟道电阻立即下降30Ω,然后衰减到稳定状态,此时的电阻比初始状态小10Ω,这种现象模拟了兴奋性突触的突触权重变化,电导的永久性变化是锂掺杂的非易失性造成的。在应用一系列不同参数的脉冲后,还观察到LTP和LTD行为。STDP塑性也在这种电化学突触中通过应用双脉冲可编程方案得到了证实。种种突触行为的成功模拟预示着这种电化学石墨烯突触晶体管有可能成为神经形态计算的硬件实现方案之一。近年来,原子层状的2D材料已经引起了纳米器件的广泛关注,在各类先进的电子器件方面表现出很好的应用前景。Jiang等[22]制备了一种以聚乙烯醇(PVA)质子传导电解质为栅介质层的多栅调控2D MoS2突触晶体管。共面金属电极2DMoS2分别被认为是突触前膜和突触后膜。通过调控多个突触前输入端可以在这样的2D MoS2神经形态晶体管中进行时空耦合。基于2D MoS2的器件中已经成功模拟了EPSC、PPF、动态滤波器、时空信号树状积分等突触行为。此外,乘法神经编码和神经元增益调制也被成功证明。这种2D MoS2神经形态装置对于在二维纳米级神经形态认知系统中实现有趣的人工智能具有重要意义,如方向选择性、目标识别、感知处理等。金属氧化物半导体由于其高的载流子迁移率、优异的光学透明性、良好的稳定性以及可大面积制备等优点使其成为人工突触晶体管的潜在候选沟道材料。其中铟锌氧(IZO)和铟镓锌氧(IGZO)是应用最广泛的氧化物材料。Zhu等[11]提出了一种基于磷(P)掺杂纳米颗粒SiO2薄膜质子横向耦合效应的IZO突触晶体管。如图4(a)所示,不需要底部导电,并且栅极电压可以仅通过一个横向双电(EDL)电容直接耦合到IZO半导体实现横向调控。使用该器件模拟了一系列短程可塑性行为,包括两个脉冲时间间隔Δtpre越小可获得较高的PPF数值的双脉冲易化(如图(4b)所示),高频信号越多,突触权重在短时间内增加越多的高通滤波行为(如图4(c)所示)以及时空相关动态逻辑测试(如图4(d))。此外,这种横向耦合的突触晶体管可以很容易扩展到多个输入栅极,以构建突触相互作用的功能。这里提出的这种基于质子传导电解质的横向耦合IZO晶体管对突触电子学和神经形态工程具有重要意义。图4.横向耦合IZO晶体管的突触塑性2019年,He等[23]展示了一种基于金属氧化物铟镓锌氧(IGZO)多端口神经晶体管,模拟了不同时空输入模式的树突辨别,其结构示意图如图5(a)所 示。首先,该器件模拟了突触可塑性的调节行为,如双脉冲易化和高通时间滤波。然后在多端神经晶体管中实现了不同时空输入模式的树突识别,说明它可以作为基本皮层计算的时空信息处理单元,大大减小神经形态系统的规模和复杂性,提高人工神经网络的效率。最后,作为一个时空信息处理的例子,一个有趣的工作——通过基于这种多端IGZO神经晶体管的人工神经网络来模拟人脑的声音定位功能被提出来,利用双耳效应在人脑中定位声音的示意图如图5(b)所示。如图5(c)所示,当声音来自右侧方向时,POSTN1首先处理弱突触传递的信号,然后处理强突触传递的信号。POSTN2首先处理强突触传递的信号,然后处理弱突触传递的信号。因此,在最后一个PREN信号出现时,POSTN1(IPOST1)的突触后电流幅度大于POSTN2(IPOST2)。同样,如果声音是从左方发出的,则IPOST2的振幅大于IPOST1的振幅。最后一个PREN信号时,IPOST和IPOST1的振幅与PREN 2和PREN1峰值(TPREN2-TPREN1)的相对时间和声音方位角的比值如图(5d)所示。最后一个PREN信号时,IPOST1和IPOST2之间的差变随着PREN 1和PREN 2峰值相对时间的变化。当时差为0ms时,比率为1。当时间差在25~1000ms变化时,比值大于1,并且随着时间差的增大而增大。当时间差在-1000~-25ms之间变化时,比值小于1,并且随着时间差的增大而增大。这种与时间相关的识别表明了人工神经网络对声音方位角的检测功能。图5.多端双电层晶体管神经形态模拟有机半导体由于其成本低,化学多功能性强,柔性可弯曲,易于加工等优点被国内外各大实验室所研究,其也被用来制备有机电化学晶体管来模拟突触塑性。2015年,Gkoupidenis等[24]首次报道了使用PEDOT:PSS作为沟道层,KCl 电解质作为栅绝缘层的低功耗有机电化学神经形态晶体管。电解液中的离子由于电场作用会被注入到PEDOT:PSS聚合物中以改变其空穴掺杂水平,从而调节流经通道的空穴电流。当脉冲电压被移除时,由于先前注入的离子会扩散回电解质,PEDOT:PSS将恢复到原来的状态。基于PEDOT:PSS的电化学突触晶体管实现了双脉冲抑制(PPD)和动态滤波特性等典型的突触行为。近年来,Qian等[25]将聚(3-己基噻吩)(P3HT)旋涂在SiO2/Si衬底上作为沟道层,热沉积了金作为源、漏和栅电极,最后将配比的离子凝胶作为栅绝缘层制备了有机电化学晶体管,其结构如图6(a)所示。利用施加在栅极的脉冲电压作为输入刺激,沟道电导变化代表突出权重。该突触晶体管成功模拟了后突触兴奋电流(如图(6b)所示),当施加脉冲栅电压,阴离子从离子凝胶移动到栅绝缘层与沟道层的界面处,从而形成EDL。因此,P3HT中的空穴积聚在半导体和离子凝胶的界面上,导致通道电导增加。在脉冲电压撤去后,阴离子开始扩散,回到它们在离子凝胶中的初始分布,因此PSC恢复到原来的状态。基于P3HT的有机电化学晶体管也实现了自我调整(如图6(c)所示)。当一系列的输入脉冲电压施加时,双脉冲易化出现在前两个尖峰上,但随后EPSC值随着脉冲电压的持续增加而减少,这种现象与生物兴奋性突触的适应性相同。此外,如图6(d)所示该突触晶体管还实现了双栅调控的OR逻辑。图6.有机电化学晶体管的突触塑性模拟光电突触晶体管光电突触晶体管(optoelectronic synaptic transistors)是构成神经形态计算系统的另一基本方法,利用这种新型人工装置模拟突触行为具有高效节能的优势。相对于传统的突触装置需要额外的传感器来进行光电转换。而以光为输入信号的光电神经形态器件,不仅将视觉、信息处理和记忆结合在一起,而且具有带宽高、鲁棒性强、并行性好等优点,适用于模拟人眼视网膜神经元等功能[26-27]。2018年,Yang等[28]制造了基于铟镓锌氧(IGZO)双电层(EDL)晶体管的电阻负载反相器用于光电突触器件应用。这种光电人工突触装置可以模拟突触 行为,如兴奋性突触后电位(EPSP),双脉冲易化(PPF)和长期可塑性等。整个器件可以看作是一种低压光电人工突触。其施加在IGZO通道层上的光脉冲 ,输出电位和沟道的电导改变分别被视为输入信号,突触后电位(PSP)和突触权重,其结构示意图如图7(a)所示。图7(b)的上部和下部分别描绘了不同光脉冲功率(232mw/cm²在和176mw/cm²)在不同栅压下刺激的EPSP曲线。从图中观察到更强的光脉冲信号导致更显著的反应,输出端电位从基态急 剧升高,达到峰值后,突触后电位逐渐回落。在这个过程中,通道电阻被输入光脉冲调制,导致输出电压相应地改变。图7(c)显示了两个连续的突触前光脉 冲触发的EPSP(PPF塑性行为),由第二个突触前光脉冲触发的EPSP的振幅比由第一个突触前光脉冲刺激的EPSP的振幅大1.37倍。图7(d)描述了不同 栅压下,刺激次数累积时,器件突触权重变化情况。图7.基于铟镓锌氧(IGZO)双电层(EDL)晶体管的光电突触塑性同年,Dai等[29]报道了一种有机场效应晶体管的光电突触装置,该装置使用聚丙烯腈(PAN)膜作为介电和电荷捕获层,PAN介质薄膜的强极性官能团可以在沟道/栅介质的界面上产生很强的电荷俘获效应。界面处光生电荷的捕获和去捕获过程为OFET提供了突触行为,如EPSC和PPF。此外,通过调节光刺激参数(包括光脉冲宽度、强度和光脉冲数量),实现了类似于人脑的记忆和学习行为。包括EPSC衰退和遗忘等行为。Wang等[30]报道了一种无机卤化物钙钛矿(CsPbBr3)量子点(QD)的光子突触。将厚度为30nm的CsPbBr3QD层旋涂到100nm厚的SiO2的Si衬底上。超薄的聚甲基丙烯酸甲酯(PMMA)层被旋涂在顶部作为钝化层。然后在PMMA顶部沉积p型并五苯作为半导体沟道。最后通过热蒸发和掩膜版技术沉积金的源、漏电极,该器件结构如图8(a)所示。器件中CsPbBr3量子点和半导体层之间形成的异质结构是该器件的光学可编程和电可擦除特性的基础。在栅极作用下,CsPbBr3量子点中的光生空穴通过能带调控下很容易注入到半导体层,而电子则留在CsPbBr3量子点中。而由于势阱的存在,留在CsPbBr3量子点中电子能保持较长时间从而产生类似突触的记忆效应。想要完全擦除这种记忆效应则需要加一个足够的负栅极电压。利用这种特性,通过光脉冲宽度、光脉冲强度和光脉冲波长等光刺激参数,有效地模拟了EPSC、PPF、PPD等突触塑性,如图(8b)~(d)所示。此报道中光电突触装置的制备有望为今后神经形态器件的设计提供新的思路。图8.有机场效应晶体管的光电突触塑性总结和展望近10年来,在神经形态工程的飞速发展进程中,基于硬件途径实现人造突触得到了充分的重视和研究,从模拟生物突触或神经元行为,到复杂的神经形 态计算 ,都取得了显著的进展。其中三端口晶体管由于具有稳定性好、测试参数相对可控、运行机制清晰、可由多种材料构成等优点在众多被构筑出来用以模拟突触行为的电子器件中脱颖而出。通过适当的材料选择和结构设计,三端/多端突触晶体管可以将外界的刺激(光、压力、温度等)转换成电信号,从而实现对外界环境直接响应的人工突触。此外,三端/多端突触晶体管还具有同时执行信号传输和自学习的优势,而且模拟需要多端操作的并行学习和树突整合可以很容易地在基于三端/多端突触晶体管的人工突触中实现,这为开发具有较少神经元件 的神经网络开辟了可能性。本文讨论了包括铁电突触晶体管、双电层/电化学突触晶体管和光电突触晶体管在内的三端/多端晶体管近年来的最新进展。它们有各自的优缺点,其中铁电场效应晶体管具有编程速度快、无损读出、开关比大、低功耗等优点。然而部分改变铁电材料的极化状态通常需要较大的工作电压,铁电材料的稳定极化状态使其易于实现LTP,但是很难实现STP;双电层/电化学突触晶体管在实现逻辑功能、树突整合和人工树突神经元方面优于其他类型的器件。此外,双电层/电化学晶体管的低压工作特性也为实现超低能耗的突触器件提供了可能。然而,器件的耐用性和电解质的不稳定性可能是双电层/电化学突触晶体管的主要限制;在光电突触晶体管方面,以光为输入信号的光电神经形态器件,不仅将视觉、信息处理和记忆结合在一起,而且具有带宽高、鲁棒性强、并行性好等优点,适用于模拟人眼视网膜神经元等功能。然而,利用光信号实现抑制性突触仍然是一个很大的挑战。这些器件各有优缺点,根据特定应用程序的要求,一种类型的器件可以优先于其他类型的器件。神经形态工程旨在构建具有超低能耗的鲁棒类脑计算机,利用新兴的突触装置来实现人工神经网络已经有了很多成功的尝试,然而神经形态器件领域所面临的一些主要问题和挑战仍需要我们不断进取努力。例如:目前所报道的突触器件模拟的小部分突触行为,完整的人造突触功能还需进一步研究完善;对于能够模拟生物神经元信息处理功能的神经形态器件的研究还仅限于少数报道,迫切需要更 深入的研究;目前科学对人脑的功能和运行机制的了解还在初步阶段。虽然目前这一领域还处于起步阶段,但是在未来,期待利用大量人造突触晶体管模拟类似于感官(视觉、听觉、运动、嗅觉)这样复杂的人类神经系统。相信通过物理、化学、材料学、计算机和医学等科学领域的跨学科交流,类脑神经形态工程将获得不断的革新进步和应用,先进的人工智能系统将促进人类在服务行业、个人医疗、教育和交通等领域的生活。文献引用:朱力,万青. 神经形态晶体管研究进展[J]. 微纳电子与智能制造, 2019, 1(4): 39-50.Research progress of neuromorphic transistors[J]. Micro/nano Electronics and Intelligent Manufacturing, 2019, 1(4): 39-50.《微纳电子与智能制造》刊号:CN10-1594/TN主管单位:北京电子控股有限责任公司主办单位:北京市电子科技科技情报研究所北京方略信息科技有限公司投稿邮箱:tougao@mneim.org.cn(网站:www.mneim.org.cn)参考文献:[1] BACKUS J. Can programming be liberated from the von Neumann style? a function style and its algebra of programs[J]. Communications of the ACM, 1978, 21(8): 613-641. [2] DRACHMAN D A. Do wo have brain to spare[J]. Neurology, 2005, 64 (12):2004-2005. [3] FURBER S. To build a brain[J]. Spectrum IEEE, 2012, 49(8): 44-49. [4]MARKRAM H. The blue brain project[J]. Nature Reviews Neuroscience, 2006, 7(2): 153-160.[5] MARKRAM H, GERSTNER W, SJÖSTRÖM P J. A history of spike-timing-dependent plasticity[J]. Frontiers in Synaptic Neuroscience, 2011, 3(4): 4. [6] CAPORALE N, DAN Y. Spike timing-dependent plasticity: a hebbian learning rule[J]. Annual Review of Neuroscience, 2008, 31(1): 25-46. [7] RACHMUTH G, SHOUVAL H Z, BEAR M F, et al. A biophysically- based neuromorphic model of spike rate- and timing-dependent plasticity[J]. Proceedings of the National Academy of Sciences, 2011, 108(49): E1266-74. [8] PREZIOSO M, MERRIKH-BAYAT F, HOSKINS B D, et al. Training and operaion of an integrated neuromorphic network based on metal- oxide memeristors[J]. Nature, 2015, 521(7550): 61-64. [9 ] XU W, LEE Y, MIN S Y, et al. Simple, inexpensive, and rapid approch to fabricate cross- shaped memristors using an inorganic- nanowire- alignment technique and a one- step reduction process[J]. Advanced Materials, 2016, 28(3): 527-532. [10] NISHITANI Y, KANEKO Y, UEDA M, et al. Three-terminal ferroelectric synapse device with concurrent learning function for artficial neural networks[J]. Journal of Applied Physics, 2012, 111(12): 124108-1-124108-6. [11] ZHU L Q, WAN C J, GUO L Q, et al. Artificial synapse network on inorganic proton conductor for neuromorphic systems[J]. Nature Communications, 2014, 5: 3158. [12] DAI S, WU X, LIU D, et al. Light- stimulated synaptic devices utilizing interfacial effect of organic field-effect transistors[J]. ACS Applied Materials & Interfaces, 2018, 10 (25): 21472-21480. [13] WANG K, DAI S, ZHAO Y, et al. Light-stimulated synaptic transistors fabricated by a facile solution process based on inorganic perovskite quantum dots and organic semiconductors[J]. Small, 2019, 15(11): 1900010-1-19000010-8. [14] MILLER S L, MCWHORTER P J. Physics of the ferroelectric nonvolatile memory field effect transistor[J]. Journal of Applied Physics, 1992, 72(12): 5999-6010. [15] KANEKO Y, NISHITANI Y, UEDA M. Ferroelectric artificial synapases for recognition of a multishaded image [J]. IEEE Transactions on Electron Devices, 2014, 61 (8): 2827-2833. [16] KIM M K, LEE J S. Ferroelectric analog synaptic transistors[J]. Nano Letters, 2019, 19(3): 2044-2050. [17] JANG S, JANG S, LEE E -H, et al. Ultrathin comformable organic artificial synapses for wearable intelligent device applicatios[J]. ACS Applied Materials & Interfaces, 2019, 11(1): 1071-1080. [18] MIN Y, AKBULULUT M, SANGORO J R, et al. Measurement of forces across room temperature ionic liquids between mica surfaces[J]. The Journal of Physical Chemistry C, 2009, 113(37): 16445-16449. [19] KIM S H, HONG K, XIE W, et al. Electrolyte-gated transistors for organic and printed electronics[J]. Advanced Materials, 2013, 25(13): 1822-1846. [20] KIM K, CHEN C L, TRUONG Q, et al. A carbon nanotube synapse with dynamic logic and learning[J]. Advanced Materials, 2013, 25(12): 1693-1698. [21] SHARBATI M T, DU Y, TORRES J, et al. Low- power, electrochemically tunable graphene synapses for neuromorphic computing[J]. Advanced Materials, 2018, 30 (36): 1802353. [22] JIANG J, GUO J, WAN X, et al. 2D MoS2 neuromorphic devices for brain- like computational systems[J]. Small, 2017, 13(29): 1900933-1-1700933-11. [23] HE Y L, NIE S, LIU R, et al. Spatiotemporal information processing emulated by multiterminal neuro- transistor networks[J]. Advanced Materials, 2019, 31(21): 1900903-1-19000903-8. [24] GKOUPIDENIS P, SCHAEFER N, GARLAN B, et al. Neuromorphic functions in PEDOT: PSS organic electrochemical transistors[J]. Advanced Materials, 2015, 27 (44): 7176-7180. [25] QIAN C, SUN J, KONG L A, et al. Artificial synapses based on in- plane gate organic electrochemical transistors[J]. ACS Applied Materials & Interfaces, 2016, 8 (39): 26169-26175. [26] KURAMOCHI E, NOZAKI K, SHINYA A, et al. Largescale integration of wavelength- addressable all- optical memories on a photonic crystal chip[J]. Nature Photonics, 2014, 8(6): 474-481. [27] GHOLIPOUR B, BASTOCK P, CRAIG C, et al. Amorphous metal- sulphide microfibers enable photonic synapses for brain-like computing[J]. Advanced Optical Materials, 2015, 3(5): 635-641. [28] LI H K, CHEN T P, LIU P, et al. A light-stimulated synaptic transistor with synaptic plasticity and memory functions based on InGaZnOx- Al2O3 thin film structure [J]. Journal of Applied Physics, 2016, 119(24): 244505- 1-244505-5. [29] DAI S L,WU X H, LIU D P, et al. Light-stimulated synaptic devices utilizing interfacial effect of organic fieldeffect transistors[J]. Applied Materials & Interfaces, 2018, 10(25): 21472-21480. [30] WANG Y, LV Z Y, CHEN J R, et al. Photonic synapses based on inorganic perovskite quantum dots for neuromorphic computing[J]. Advanced Materials, 2018, 30 (38): 1802883-1-1802883-9.来自微信
-
FPGA惊天大漏洞细节全解读 来源:内容授权转载自公众号「老石谈芯」,作者:老石,谢谢。今年4月,来自德国的研究者披露了一个名为“StarBleed”的漏洞,它存在于赛灵思的Virtex、Kintex、Artix、Spartan 等全部7系列FPGA中。通过这个漏洞,攻击者可以同时攻破FPGA配置文件的加密(confidentiality)和鉴权(authenticity),并由此可以随意修改FPGA中实现的逻辑功能。更严重的是,这个漏洞并不能通过软件补丁的方式修复,一旦某个芯片被攻破,就只能通过更换芯片的方式修复。漏洞的发现者已于2019年9月将这个漏洞知会了赛灵思,并在第二天就获得了赛灵思的承认。根据赛灵思之前发布的财报,7系列FPGA贡献了公司35%的营收。这些FPGA被广泛用于通信设备、医疗、军工宇航等多个领域,而这些领域很多都需要系统有着很高的稳定性与安全性。因此,这次爆出的重大漏洞,无疑会对赛灵思及其客户带来较大的负面影响。近年来,有关CPU的漏洞时有发现。例如在2018年初,几乎全部主流的CPU厂商都被发现在其CPU产品中存在熔断(Meltdown)和幽灵(Spectre)漏洞。相比之下,FPGA的漏洞问题并不那么“常见”。在这篇文章中,老石将深入解析造成这个漏洞的技术原因,并总结一些可行的应对方法与预防措施。FPGA的主要加密方式随着FPGA在数据中心、通信基础设施、AI加速、医疗设备、边缘计算等多个领域的广泛使用,针对FPGA安全性的研究在近年来逐渐成为学术界和工业界关注的热点之一。与CPU、ASIC等芯片相比,FPGA芯片本身并不会完成任何逻辑功能,它只包含大量的可编程逻辑阵列,以及若干固化的IP核。FPGA系统功能的实现,基本完全取决于开发者的逻辑设计。由于不同的设计者可以开发不同的系统逻辑,这就使得相同的FPGA芯片可以广泛用于众多不同的行业领域。通常来说,一个FPGA设计都是由很多IP组合而成,而这些IP才是FPGA设计中最有价值的部分。为了将设计加载到FPGA中运行,唯一的方式就是通过一个所谓的“比特流(bitstream)”文件完成,业界也通常称之为系统映像。系统映像由FPGA设计软件自动生成,它包含了FPGA设计的全部信息,因此是FPGA加密环节的重中之重。通常来说,对比特流或系统映像文件的保护方式有两个层面,第一是加密,第二是鉴权。加密指的是使用特定算法对比特流文件进行处理,将其转换成密文,使得其中的内容对外不可见。在赛灵思的7系列FPGA中,使用了CBC-AES-256算法进行比特流加密。鉴权指的是对加密后的比特流文件进行身份验证,防止对其进行篡改和删减,这类似于我们日常生活中的身份验证。如果比特流文件被修改,势必会导致错误的鉴权结果。如果将这个比特流下载到FPGA中,会因为身份校验失败而拒绝执行,从而避免被攻击的可能。在赛灵思的7系列FPGA中,使用了基于SHA-256的HMAC(散列消息认证码,Hash-based Message Authentication Code)方法进行鉴权。可以想象,如果比特流的加密过程被破解,那么攻击者就可以读出比特流文件中的所有信息,从而进行反向工程、IP破解、信息收集等工作。如果鉴权过程被破解,那么攻击者就可以对比特流文件进行任意修改,比如修改系统功能、木马注入等。所以说,这两种保护方式缺一不可。只可惜,这次的StarBleed漏洞恰恰利用了这两种保护方式各自的短板,从而彻底破解比特流的加密和鉴权,并达到了完全控制比特流和FPGA芯片的目的,可以说这个漏洞的破坏性和潜在危害性极强。StarBleed漏洞的具体攻击方法整个攻击过程分为两大部分,第一是对加密的比特流文件进行破解,第二是获取鉴权密钥。为了破解加密的比特流文件,攻击者利用了赛灵思FPGA里的一个特殊的配置寄存器WBSTAR,这个寄存器原本保存了FPGA MultiBoot功能的起始地址,当启动FPGA时,就通过读取这个寄存器从片外非易失性存储器找到映像文件。因此,当FPGA复位时,这个寄存器的内容是不会被抹掉的。对加密比特流的破解过程分为5个步骤。第一步,攻击者对一个合法的比特流文件进行了简单篡改。具体来说,他需要修改比特流的一个32位字,将其改成对WBSTAR寄存器的写操作。写入的内容,就是比特流本身。虽然比特流是加密的,但这个篡改过程并没有想象中那么困难。由于Vivado生成的比特流文件的格式和很多内容是固定的,攻击者可以对比不同的比特流文件,从而确定对WBSTAR寄存器操作命令的位置,然后对其进行修改即可。由于篇幅所限,这部分的具体的细节不再赘述,欢迎在知识星球或微博与老石进一步交流。比特流数据结构,灰色部分是加密的内容第二步,将篡改后的比特流加载到FPGA里。此时,FPGA会对比特流进行解密,并将一个32位字写入WBSTAR寄存器。值得注意的是,这里写入的是已经解密的比特流内容!第三步,加载完毕后,由于比特流发生了修改,因此校验失败,并自动触发系统复位。第四步,使用另外一个未加密的比特流文件,读取WBSTAR寄存器的内容。由于WBSTAR寄存器的特殊性,它的内容不会随着复位而清除。因此,此时攻击者再使用另外一个未加密的比特流文件读取这个寄存器的内容,就可以得到解密后的FPGA比特流的32位内容了。这个未加密的比特流文件已开源,请在文末扫码进入知识星球查看。第五步,手工复位,然后重复上述步骤,直到整个比特流都解密完成。可以看到,攻击者利用了上面提到的鉴权过程晚于加解密过程这个缺陷,通过“蚂蚁搬家”的方式完成了对比特流的完全解密。最可怜的是,此时的FPGA本身也沦为了帮助解密的工具。这也解释了为什么只能通过更换FPGA芯片才能修补这个漏洞。下面的表格总结了不同的7系列FPGA的比特流大小,以及解密所需要的时间。读出一个32位字大概需要7.9毫秒,那么破解一个Kintex FPGA的比特流就大概需要3小时42分钟。接下来,就可以对鉴权过程进行破解了。这个过程相对简单,事实上,身份校验所需的HMAC密钥就存储在比特流文件中,并且未经其他额外的加密。这正是所谓的“谜底就在谜面上”。所以只需要读取完整的比特流,就可以免费附赠HMAC密钥一枚。有了它,就可以任意修改比特流文件的内容,并重新计算身份校验。此外,攻击者甚至可以修改HMAC密钥本身。综上所述,StarBleed漏洞正是利用了赛灵思7系列FPGA的两大设计缺陷:身份校验发生在解密过程之后身份校验的密钥直接存储在加密后的比特流文件里,且无额外加密通过StarBleed漏洞,攻击者破解了全系列的赛灵思7系FPGA,包括SAKURA-X板卡上的Kintex-7,Basys3板卡上的Artix-7等等。同时,攻击者还利用同样的原理攻击了6系FPGA,例如ML605板卡上的Virtex-6 FPGA,也能实现不完全破解。防御方法由于StarBleed漏洞直接利用了赛灵思7系列FPGA芯片的设计缺陷,且攻击过程直接在加载映像文件时展开,因此不能使用软件补丁或固件升级的方法规避这个漏洞。目前唯一的修复方法只有更换芯片,赛灵思官方已经向研究者承认了这一点。事实上,攻击者使用这种方法无法破解UltraScale或更新的FPGA系列。这说明上面所说的设计缺陷已经在新型FPGA架构中得到了修复。例如,首先对比特流文件进行鉴权,通过后再进行加载。虽然除了换芯片外没有完全防御的方法,我们仍然可以采用一些设计手段增加破解的成本和复杂度。一个常见的方法是在设计中增加额外的冗余逻辑,这些额外的部分并不影响逻辑功能,但会极大的提升设计的复杂度,从而增加破解的时间成本。比如,在状态机中增加很多无用状态等等。此外,还可以在板卡设计时封锁FPGA的配置端口,比如研究者使用的JTAG和SelectMAP端口等。事实上,在量产的FPGA设计中,应该也很少有暴露的JTAG端口。同时,研究者还思考了如何尽早发现这类设计缺陷和漏洞,而形式化方法就是一个很好的解决手段。设计者可以根据芯片的设计规约,建立形式化模型,并通过满足性验证(satisfiability)等方式对这个模型进行分析和证明。结语FPGA的安全性研究并非一个全新的课题。然而,传统的FPGA攻击方法都需要使用额外的物理设备或操作,实用性远不如此次爆出的StarBleed漏洞。一旦FPGA被攻破,攻击者可以任意读取FPGA比特流的数据、IP内容等,并实现反向工程;也可以任意改变FPGA实现的逻辑功能,这使得FPGA所在的系统可能沦为攻击者的高性能“肉鸡”。由于FPGA能以40Gbps甚至更高的速度线速发送数据包,这使得大规模DDOS攻击变得“简单”。此外,攻击者也可以通过逻辑实现的方式,大幅提升芯片温度并对系统硬件进行不可逆的物理破坏,等等。可以说,这次的StarBleed漏洞给业界敲响了警钟,也将会提升人们对FPGA安全性的重视,并以此指导未来的FPGA安全性设计。亡羊补牢,犹未晚也。(注:本文仅代表作者个人观点,与任职单位无关。)*免责声明:本文由作者原创。文章内容系作者个人观点,半导体行业观察转载仅为了传达一种不同的观点,不代表半导体行业观察对该观点赞同或支持,如果有任何异议,欢迎联系半导体行业观察。今天是《半导体行业观察》为您分享的第2289期内容,欢迎关注。来自微信