搜索到
11
篇与
的结果
-
 用Python设计芯片?开源设计语言PyGears亮相! 近日,加州大学洛杉矶分校引入了一种新的硬件描述语言PyGears,以实现基于可重用组件和高级 Python 构造的敏捷芯片设计理念。PyGears 是对快速发展的软件世界的回应,这要求硬件设计与可扩展和智能未来的需求保持同步。据官网介绍PyGears 是一种免费的开源硬件描述语言 (HDL),该门语言可作为 Python 库实现,专注于函数式编程、模块组合和同步。按照他们的说法,PyGears 的出现旨在将芯片设计的复杂性转变为简单、灵活且具有成本效益的开发过程,该过程遵循可扩展和智能的方式来构建未来。该框架允许您使用 Python 结构设计硬件并将其编译为可综合的 SystemVerilog 或 Verilog 代码。内置模拟器允许您使用任意 Python 代码及其大量库来验证您的硬件模块。PyGears 使连接模块 得容易 ,并具有内置的同步机制,可帮助您构建正确的并行系统。PYGEAR 的创造者Bogdan Vukobratovic表示:“PyGears 的诞生是为了捕捉我在职业生涯中发现的所有有用的良好实践,该工具可以显着加快复杂架构的硬件实现,尤其是当它们与 AI 范式相关时。这应该是创建下一代芯片设计的一个良好开端,但这个目标需要我们所有人为硬件开发做出贡献并确定其方向。否则,未来的人工智能世界将不可持续。”据报道,通过在 VLSI 信号处理课程中采用它, 加州大学洛杉矶分校 Samueli 工程学院 开始建立一个通过软件范式观察硬件的社区,目标是通过使用更灵活和可组合的模块来加速硬件设计和验证。“芯片设计变得越来越复杂,成本越来越高,开发周期越来越长,”加州大学洛杉矶分校电气和计算机工程教授 Dejan Markovic博士说。“PyGears 通过采用由志同道合的贡献者社区构建的可重用组件的模块化硬件构建来解决这些挑战。这对于小型和大型工程团队都非常有效。硬件设计和验证基于Python环境,减少了软硬件领域的壁垒。我们的愿景是让软件人员能够编写硬件代码。”“软件的最大限制是硬件发展速度相对较慢,” Lux Capital 的合伙人Shahin Farshchi说。“PyGears 站在巨人的肩膀上,将硬件设计加速到接近‘编码’的速度,这将带来神奇的新用例,为定义市场的产品和公司提供支持。”PyGears的创建者兼 Anari AI 研发负责人Bogdan Vukobratovic博士表示,当前的工具行业倾向于对硬件开发中的所有组件进行低级优化和低级控制。另一方面,PyGears 提供对所有方面直至最低层的控制,使流程效率提高数倍。他还强调,构建复杂的架构需要具有更高开发敏捷性的系统。根据斯坦福大学教授 Boris Murmann博士的说法。,“新硬件设计工具的开发可以极大地受益于开源解决方案。为了让硬件行业摆脱石器时代并使其更加敏捷,我们需要社区塑造的新概念。”除了 UCLA 学生和其他大学,PyGears 团队已经 向硬件团队和有兴趣改进 HDL 的个人开放社区,使硬件设计更加高效和以结果为导向。附部分说明截图
用Python设计芯片?开源设计语言PyGears亮相! 近日,加州大学洛杉矶分校引入了一种新的硬件描述语言PyGears,以实现基于可重用组件和高级 Python 构造的敏捷芯片设计理念。PyGears 是对快速发展的软件世界的回应,这要求硬件设计与可扩展和智能未来的需求保持同步。据官网介绍PyGears 是一种免费的开源硬件描述语言 (HDL),该门语言可作为 Python 库实现,专注于函数式编程、模块组合和同步。按照他们的说法,PyGears 的出现旨在将芯片设计的复杂性转变为简单、灵活且具有成本效益的开发过程,该过程遵循可扩展和智能的方式来构建未来。该框架允许您使用 Python 结构设计硬件并将其编译为可综合的 SystemVerilog 或 Verilog 代码。内置模拟器允许您使用任意 Python 代码及其大量库来验证您的硬件模块。PyGears 使连接模块 得容易 ,并具有内置的同步机制,可帮助您构建正确的并行系统。PYGEAR 的创造者Bogdan Vukobratovic表示:“PyGears 的诞生是为了捕捉我在职业生涯中发现的所有有用的良好实践,该工具可以显着加快复杂架构的硬件实现,尤其是当它们与 AI 范式相关时。这应该是创建下一代芯片设计的一个良好开端,但这个目标需要我们所有人为硬件开发做出贡献并确定其方向。否则,未来的人工智能世界将不可持续。”据报道,通过在 VLSI 信号处理课程中采用它, 加州大学洛杉矶分校 Samueli 工程学院 开始建立一个通过软件范式观察硬件的社区,目标是通过使用更灵活和可组合的模块来加速硬件设计和验证。“芯片设计变得越来越复杂,成本越来越高,开发周期越来越长,”加州大学洛杉矶分校电气和计算机工程教授 Dejan Markovic博士说。“PyGears 通过采用由志同道合的贡献者社区构建的可重用组件的模块化硬件构建来解决这些挑战。这对于小型和大型工程团队都非常有效。硬件设计和验证基于Python环境,减少了软硬件领域的壁垒。我们的愿景是让软件人员能够编写硬件代码。”“软件的最大限制是硬件发展速度相对较慢,” Lux Capital 的合伙人Shahin Farshchi说。“PyGears 站在巨人的肩膀上,将硬件设计加速到接近‘编码’的速度,这将带来神奇的新用例,为定义市场的产品和公司提供支持。”PyGears的创建者兼 Anari AI 研发负责人Bogdan Vukobratovic博士表示,当前的工具行业倾向于对硬件开发中的所有组件进行低级优化和低级控制。另一方面,PyGears 提供对所有方面直至最低层的控制,使流程效率提高数倍。他还强调,构建复杂的架构需要具有更高开发敏捷性的系统。根据斯坦福大学教授 Boris Murmann博士的说法。,“新硬件设计工具的开发可以极大地受益于开源解决方案。为了让硬件行业摆脱石器时代并使其更加敏捷,我们需要社区塑造的新概念。”除了 UCLA 学生和其他大学,PyGears 团队已经 向硬件团队和有兴趣改进 HDL 的个人开放社区,使硬件设计更加高效和以结果为导向。附部分说明截图 -
Python 必杀技:用 print() 函数实现的三个特效 print() 应该是初学者最先接触到的第一个 Python 函数,因为几乎所有的启蒙课程都是从 print('Hello world') 开始的。事实上, print() 也是程序员使用频率最高的函数之一,同时也是很多程序员喜欢的代码调试利器。但是关于 print() 函数,你真的了解吗?打字机效果不了解 print() 的 flush 参数,很难实现下图所示的打字机效果:动图封面print() 像个调皮的小朋友,你让他帮你打印,他一定会做,但未必是立即去做,也许会攒够了多个打印任务才执行一次。设置 flush=True,可以让这位小朋友立刻去执行命令。 import time def printer(text, delay=0.2): """打字机效果""" for ch in text: print(ch, end='', flush=True) time.sleep(delay) printer('玄铁重剑,是金庸小说笔下第一神剑,持之则无敌于天下。')旋转式进度指示Linux 系统文本界面下,最常用的进度指示是用横竖斜杠构成的旋转图案。动图封面Python也可以轻松实现这个效果,秘诀就在于 '\b' 字符。 '\b' 相当于键盘上的退格键,可以让我们把刚刚打印过的最后一个字符擦掉重新打印。这个效果,同样需要设置参数 flush 为真。 import time def waiting(cycle=20, delay=0.1): """旋转式进度指示""" for i in range(cycle): for ch in ['-', '\\', '|', '/']: print('\b%s'%ch, end='', flush=True) time.sleep(delay) waiting() 反转字符顺序,就可以改变旋转方向。将第一个字符 '-' 改成 '-- ',还可以实现这样的效果:动图封面覆盖式打印效果'\b' 的作用是回退一个字符,'\r' 则可以退回到行首。借助于 '\r',可以实现整行覆盖式的打印效果:动图封面需要注意的是,整行覆盖的话,新的字符串长度不能小于原字符串长度,否则会留下前一次的打印内容。这个效果,同样需要设置参数 flush 为真。 import time def cover(cycle=100, delay=0.2): """覆盖式打印效果""" for i in range(cycle): s = '\r%d'%i print(s.ljust(3), end='', flush=True) time.sleep(delay) cover()
-
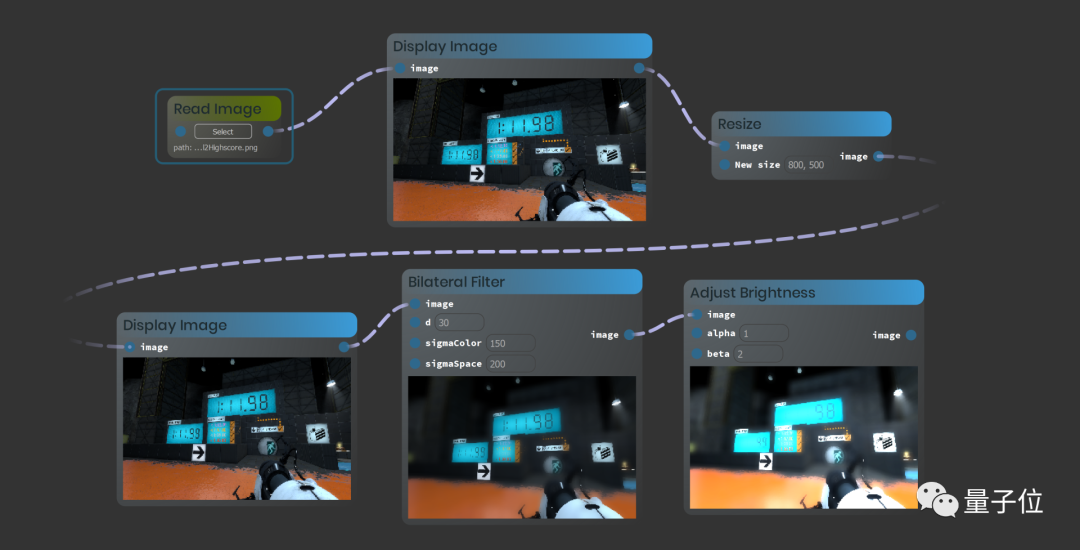
大一新生开源 Python 脚本可视化工具,火了! Python数据科学2021年01月25日14:05普普通通黑底白字地敲代码太枯燥?那么,把 Python 脚本可视化怎么样?就像这样,从输入图片、调整尺寸到双边滤波,每一步都能看得清清楚楚明明白白。输入一个矩阵,无论是对它进行转置、求共轭还是乘方,都能得到及时的反馈。这样一个 Python 脚本可视化工具,名叫 Ryven,出自一位名叫 Leon Thomm 的大一新生之手。如果你也想试用一番,不妨接着往下看。如何使用使用之前,简单准备一下开发环境:Python3(推荐 3.8 以上)PySide2(推荐 2.14 以上)运行该项目中的 Ryven.py,即可打开编辑器。作者提到,在 Ryven 中,有许多不同的脚本。每个脚本都包含变量、流(或图)以及日志。右键单击就可以轻松操作。不过,想要使用这些节点,需要先导入节点软件包。点击 file,选择 import Nodes,导入 *.rpc 文件即可。这个工具的另外一个特点是,包含了两种不同的算法模式。数据流:每次数据更改(节点数据输出也就更改了)都会向前传播,并在所有连接的节点中触发更新。如下图,滑动滑块,会立即触发右侧节点中结果的更新。执行流:数据不会在更改时立即向前传播,而是只会在某个节点请求输出数据时,在受影响的节点中触发更新。另外,作者还给自己列了一个 to do list,比如加入语法高亮功能、自动代码补全功能,完善视觉体验等等。可视化编程是不是还挺有趣的?不过,作者小哥也指出,可视化编程的目的不是取代文本编程,并且,文本编程中实现的许多工作没有可视化的必要。关于作者作者 Leon Thomm,目前是苏黎世联邦理工学院的大一学生,自称 “业余程序员”,致力于人机交互和可视化编程。根据他的个人简介,早在进入大学前,他已经具备丰富的软件开发经历。传送门项目地址:https://github.com/leon-thomm/Ryven来自微信
-
答应我,调试 Python 代码,不要再用 Print 了! Python数据科学2021年01月27日14:27相信大部分人学习Python,肯定会用print()这个内置函数,来调试代码的。那么在一个大型的项目中,如果你也是使用print来调试你的Python代码,你就会发现你的终端有多个输出。那么你便不得不去分辨,每一行的输出是哪些代码的运行结果。举个例子,运行下面这个程序。num1 = 30num2 = 40 print(num1)print(num2)输出结果。3040这些输出中哪一个是num1?哪一个又是num2呢?找出两个输出可能不是很困难,但是如果有五个以上的不同输出呢?尝试查找与输出相关的代码可能会很耗时。当然你可以在打印语句中添加文本,使其更容易理解:num1 = 30num2 = 40 print("num1" num1)print("num2" num1)输出结果。num1 30num2 40这个结果就很容易理解了,但是需要时间去写相关的信息。这时就该「Icecream」上场了~什么是Icecream?Icecream是一个Python第三方库,可通过最少的代码使打印调试更清晰明了。使用pip安装Icecream库。pip install icecream下面,让我们通过打印Python函数的输出来进行尝试。from icecream import ic def plus_five(num): return num + 5 ic(plus_five(4)) ic(plus_five(5))输出结果如下。ic| plus_five(4): 9ic| plus_five(5): 10通过使用icecream,我们不仅可以看到函数输出,还可以看到函数及其参数!检查执行情况如果你想要找到执行代码的位置,可以通过执行如下所示的操作,来查找执行了哪个语句。def hello(user:bool): if user: print("I'm user") else: print("I'm not user") hello(user=True)输出结果。I'm user使用icecream则无需多余的文本信息,就可以轻松地完成上述的操作。from icecream import ic def hello(user:bool): if user: ic() else: ic() hello(user=True) 输出结果如下。ic| ice_1.py:5 in hello() at 02:34:41.391从输出结果看,函数hello中的第5行的代码已被执行,而第7行的代码未执行。自定义前缀如果您想在打印语句中插入自定义前缀(例如代码执行时间),icecream也是能实现的。from datetime import datetime from icecream import ic import time from datetime import datetime def time_format(): return f'{datetime.now()}|> ' ic.configureOutput(prefix=time_format) for _ in range(3): time.sleep(1) ic('Hello') 输出结果如下。2021-01-24 10:38:23.509304|> 'Hello'2021-01-24 10:38:24.545628|> 'Hello'2021-01-24 10:38:25.550777|> 'Hello'可以看到代码的执行时间,就显示在输出的前面。获取更多的信息除了知道和输出相关的代码之外,你可能还想知道代码执行的行和代码文件。在ic.configureOutput()中,设置includeecontext的参数值为True即可。from icecream import ic def plus_five(num): return num + 5 ic.configureOutput(includeContext=True) ic(plus_five(4)) ic(plus_five(5))输出结果如下。ic| ice_test.py:7 in - plus_five(4): 9ic| ice_test.py:8 in - plus_five(5): 10这里我们就知道了,第一个输出是由函数plus_five在文件icecream_example.py的第7行执行的。第二个输出则是由函数plus_five在代码文件的第8行执行的。上述两个操作都用到了ic.configureOutput()函数。通过查看源码,可知有四个可供设置的参数。prefix,自定义输出前缀outputFunction,更改输出函数argToStringFunction,自定义参数序列化字符串includeContext,显示文件名、代码行、函数信息删除Icecream代码最后你可以将icecream仅用于调试,而将print用于其他目的(例如漂亮的打印)。from icecream import ic def plus_five(num): return num + 5 ic.configureOutput(includeContext=True) ic(plus_five(4)) ic(plus_five(5)) for i in range(10): print(f'****** Training model {i} ******') 输出结果。ic| ice_1.py:7 in - plus_five(4): 9ic| ice_1.py:8 in - plus_five(5): 10 Training model 0 ** Training model 1 ** Training model 2 ** Training model 3 ** Training model 4 ** Training model 5 ** Training model 6 ** Training model 7 ** Training model 8 ** Training model 9 **由于你可以区分调试打印和漂亮打印,因此搜索和删除所有ic调试语句非常容易。删除所有调试代码后,你的Python代码就整洁了。总结到此,你就应该就学会了如何使用icecream去打印调试。更多功能可以访问「GitHub」,了解详情~https://github.com/gruns/icecream来自微信
-
VSCode配置PyQt5 Designer 开发环境 1 vscode 安装 python扩展包配置Python解释器安装pyqt integration扩展配置pyqt integration2.1 进入配置界面如图所示进入设置, 选择Extension Settings然后在里面根据自己安装的pyqt5-tools, 把Designer设计器路径填上去。Ubuntu 系统一般在venv的lib下面。lib/python3.8/site-packages/qt5_applications/Qt/bin/designer最后可以在资源管理器的空白处右键就可以选择pyqt form了。设计之后的python选择,点击右键,选择Run current File in interactive Windows。